[TECO-43] <docs>: transfer Chinese docs to grav cms system.
Showing
此差异已折叠。
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
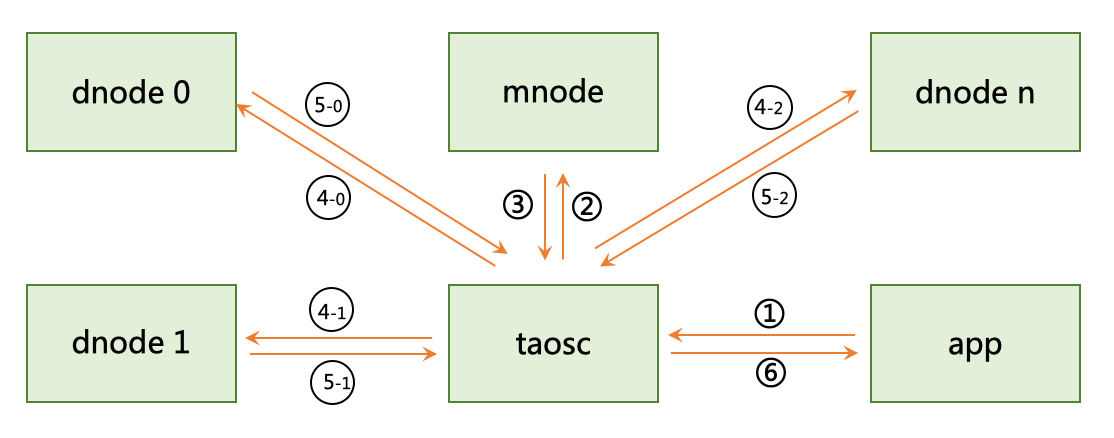
65.7 KB
{kind=link}
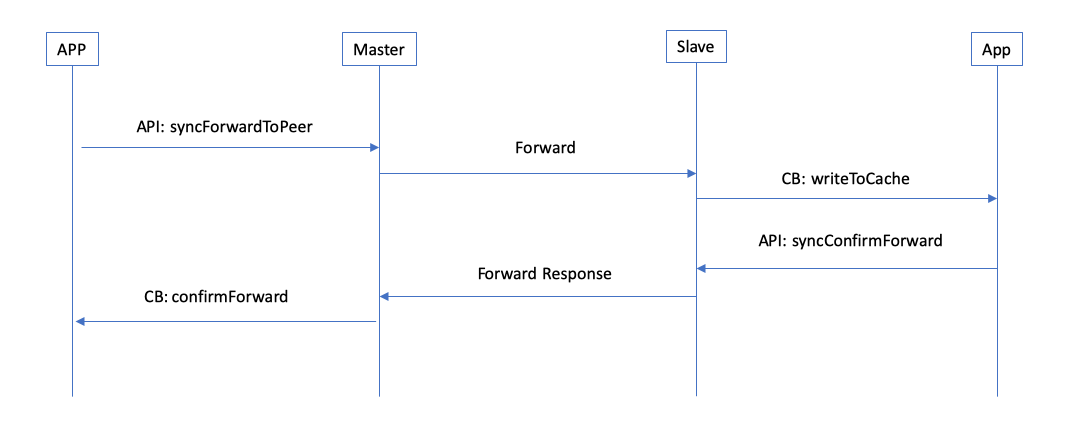
36.6 KB
{kind=link}
文件已移动
{kind=link}
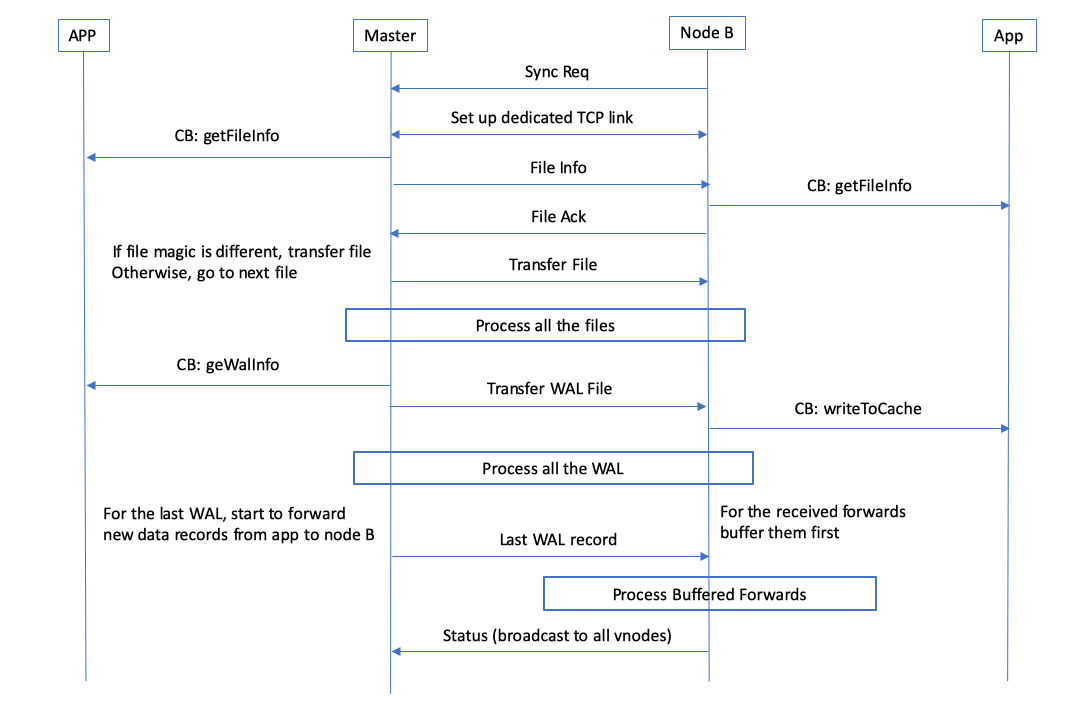
91.1 KB
{kind=link}
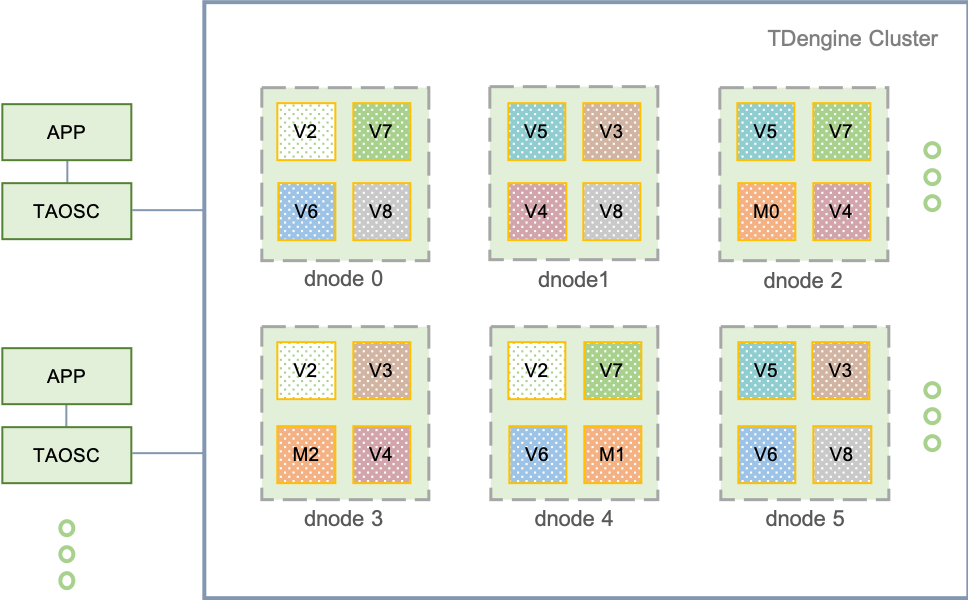
92.3 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
53.4 KB
{kind=link}
44.0 KB
{kind=link}
55.0 KB
{kind=link}
60.2 KB
{kind=link}
90.8 KB
{kind=link}
96.9 KB
{kind=link}
44.7 KB
{kind=link}
161.5 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
65.0 KB
{kind=link}
169.2 KB