Merge pull request #2191 from JetHong/pgnet-v1
Add PGNet
Showing
configs/e2e/e2e_r50_vd_pg.yml
0 → 100644
doc/doc_ch/pgnet.md
0 → 100644
{kind=link}

662.8 KB
{kind=link}

466.8 KB
{kind=link}

133.6 KB
{kind=link}

337.2 KB
doc/pgnet_framework.png
0 → 100644
{kind=link}
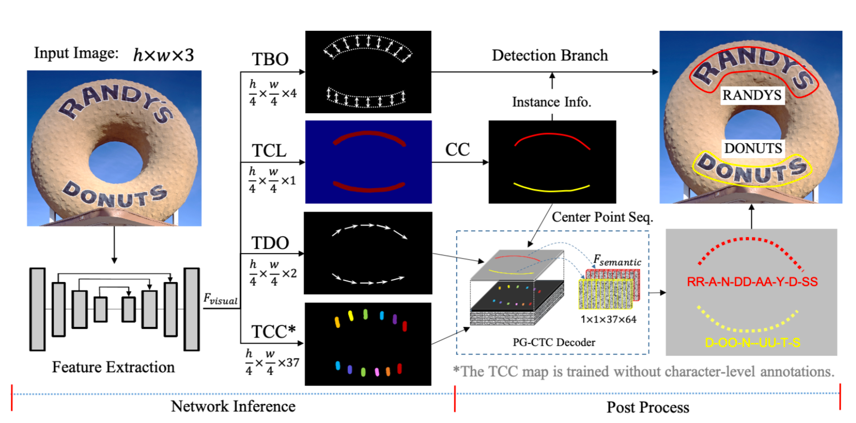
241.7 KB
ppocr/data/imaug/pg_process.py
0 → 100644
此差异已折叠。
ppocr/data/pgnet_dataset.py
0 → 100644
ppocr/losses/e2e_pg_loss.py
0 → 100644
ppocr/metrics/e2e_metric.py
0 → 100644
ppocr/modeling/necks/pg_fpn.py
0 → 100644
ppocr/utils/e2e_metric/Deteval.py
0 → 100755
此差异已折叠。
ppocr/utils/e2e_utils/visual.py
0 → 100644
| ... | ... | @@ -7,4 +7,5 @@ opencv-python==4.2.0.32 |
| tqdm | ||
| numpy | ||
| visualdl | ||
| python-Levenshtein | ||
| \ No newline at end of file | ||
| python-Levenshtein | ||
| opencv-contrib-python | ||
| \ No newline at end of file |
tools/infer/predict_e2e.py
0 → 100755
tools/infer_e2e.py
0 → 100755