Merge pull request #6462 from taosdata/docs/Update-Latest-Feature
Docs/update latest feature
Showing
{kind=link}
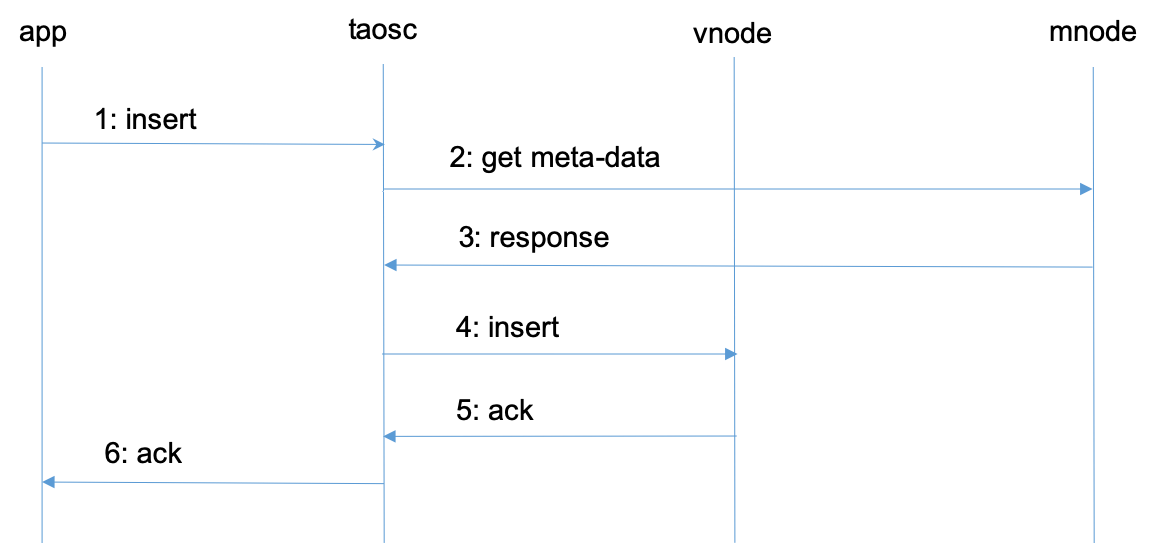
43.2 KB
{kind=link}
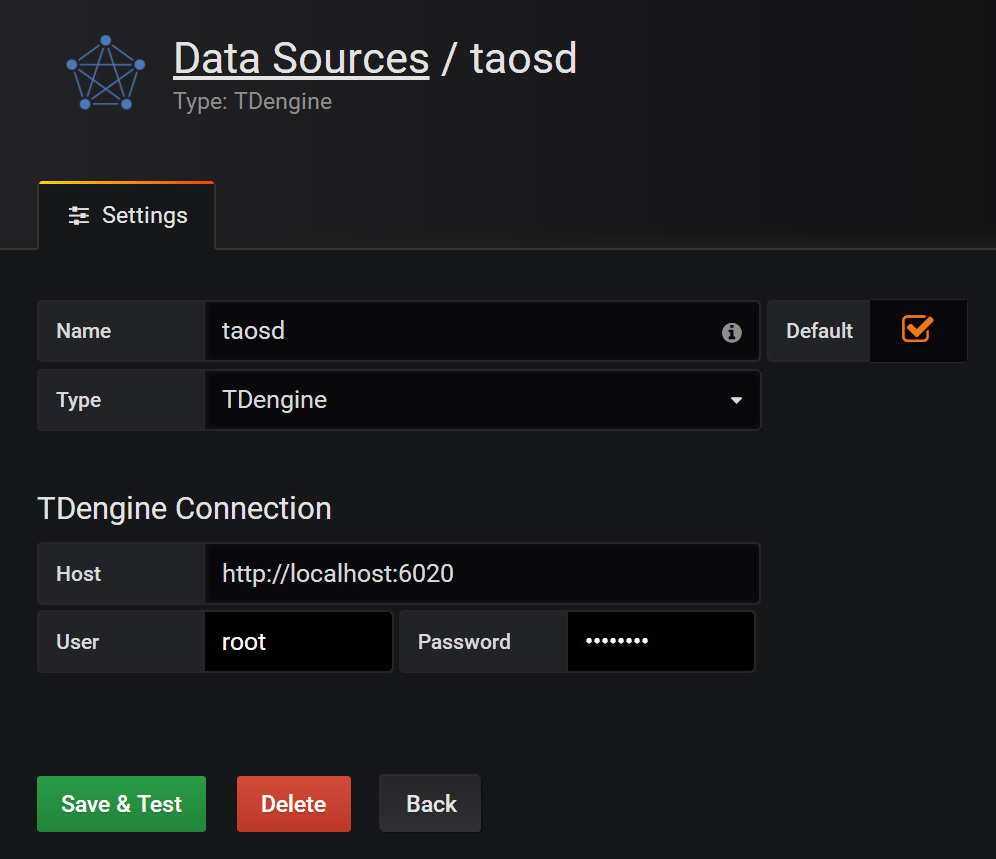
120.2 KB
{kind=link}
74.6 KB
{kind=link}
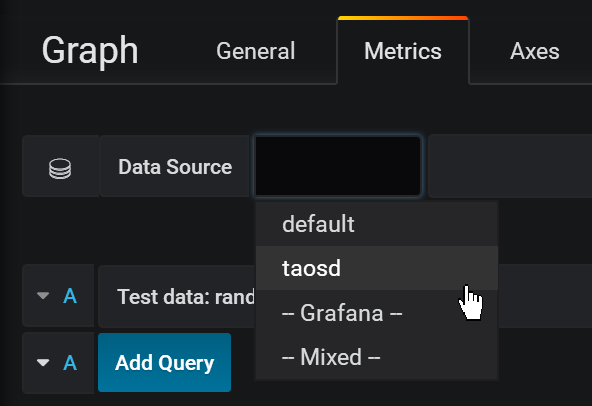
26.0 KB
{kind=link}
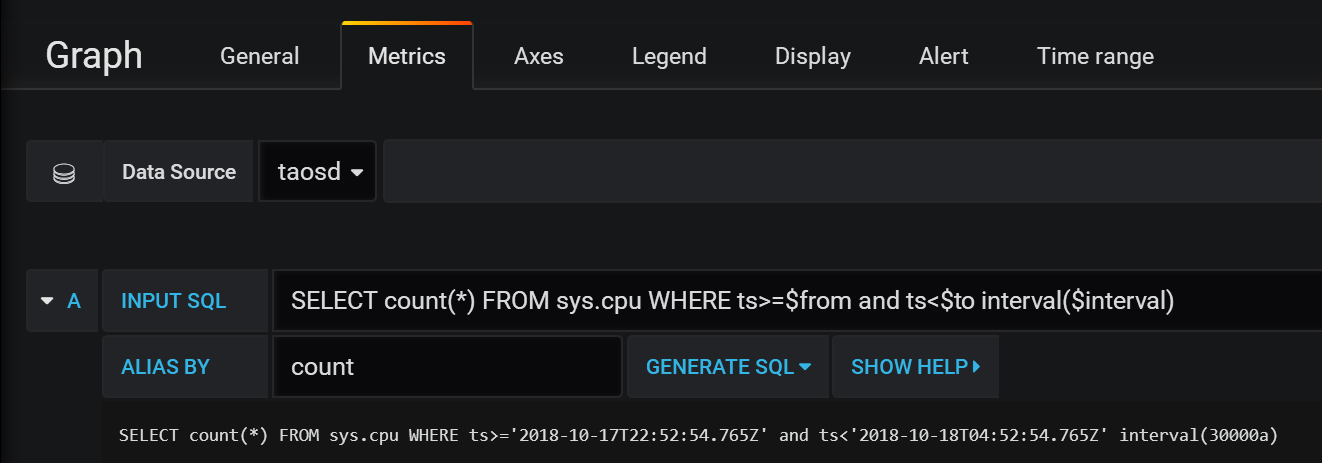
43.8 KB
{kind=link}
67.4 KB
{kind=link}
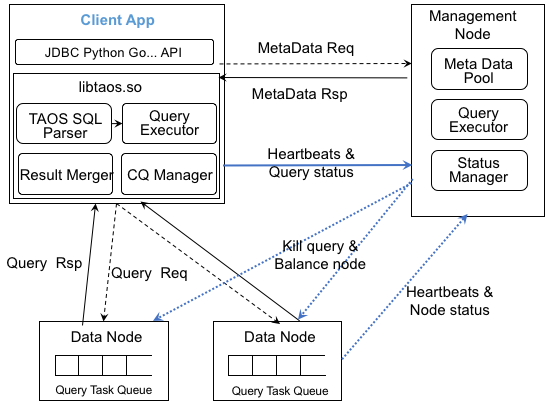
60.3 KB
{kind=link}
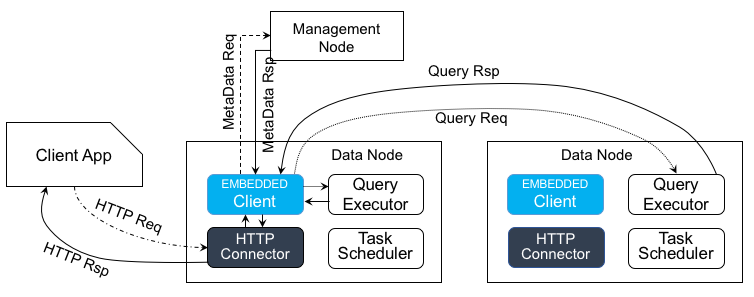
48.8 KB
{kind=link}
21.1 KB
{kind=link}
22.0 KB
{kind=link}
65.7 KB
{kind=link}
92.3 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。