Merge commit 'cb604491' into 12-2-auto-deploy-20190818
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
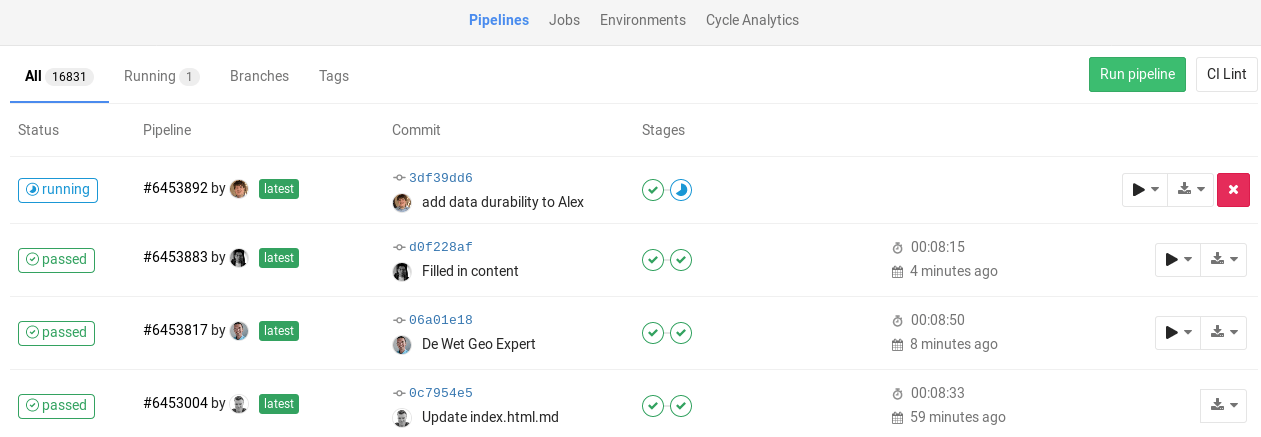
| W: | H:
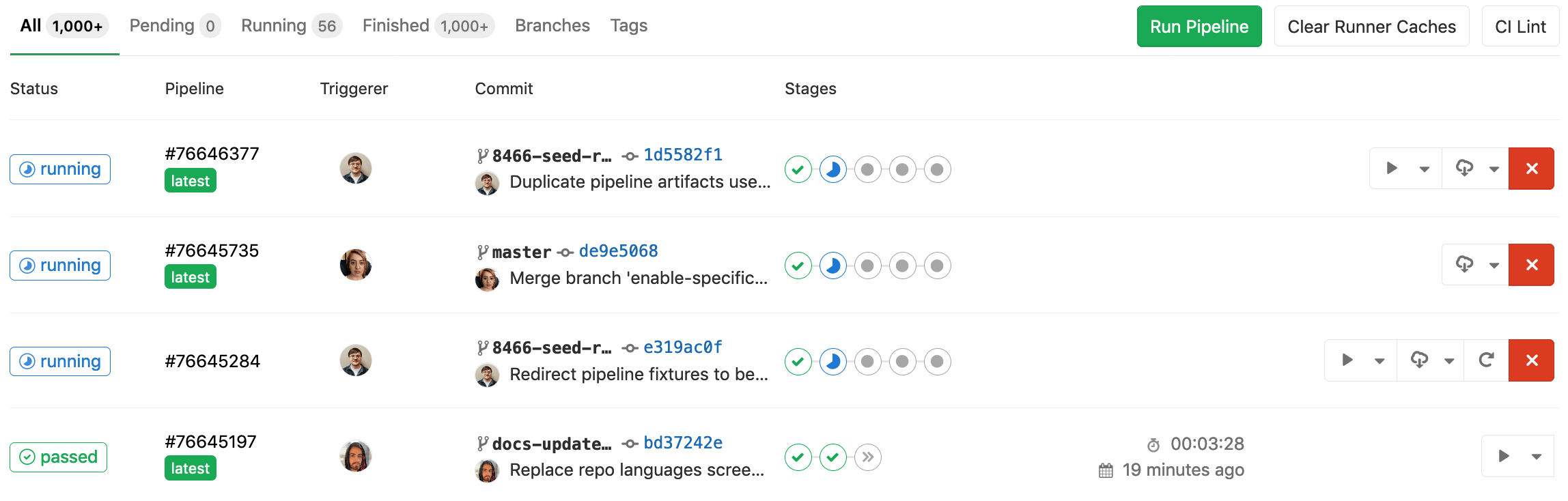
| W: | H:
{kind=link}
{kind=link}
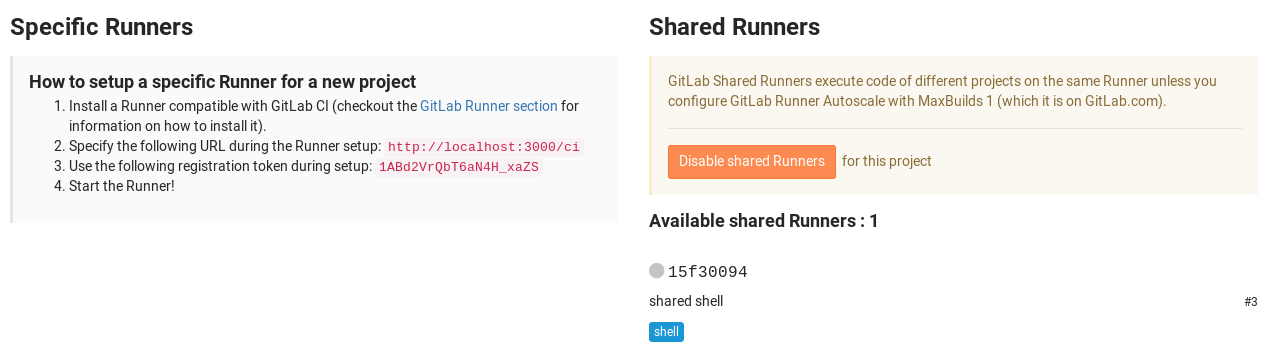
| W: | H:
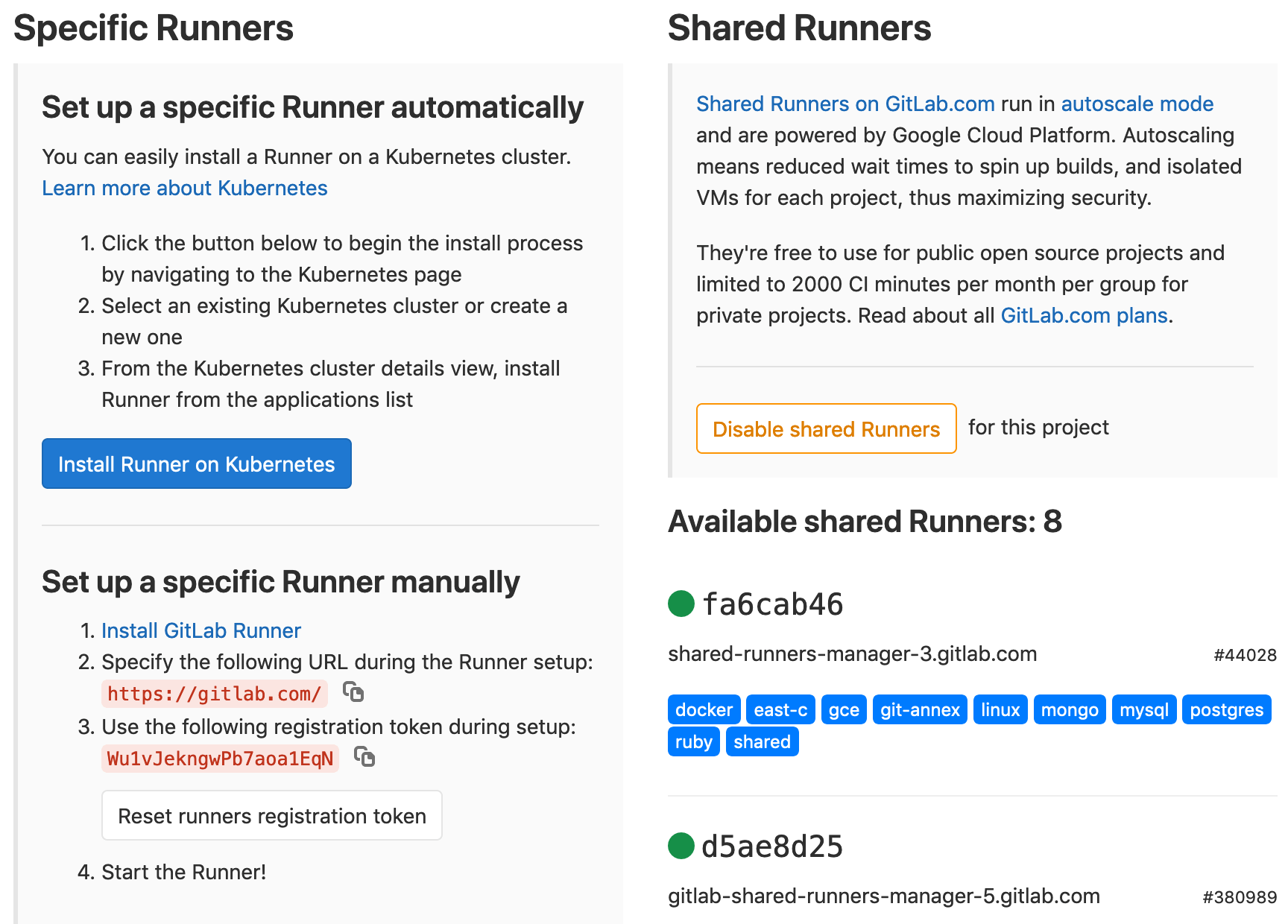
| W: | H:
doc/user/analytics/index.md
0 → 100644
{kind=link}
{kind=link}
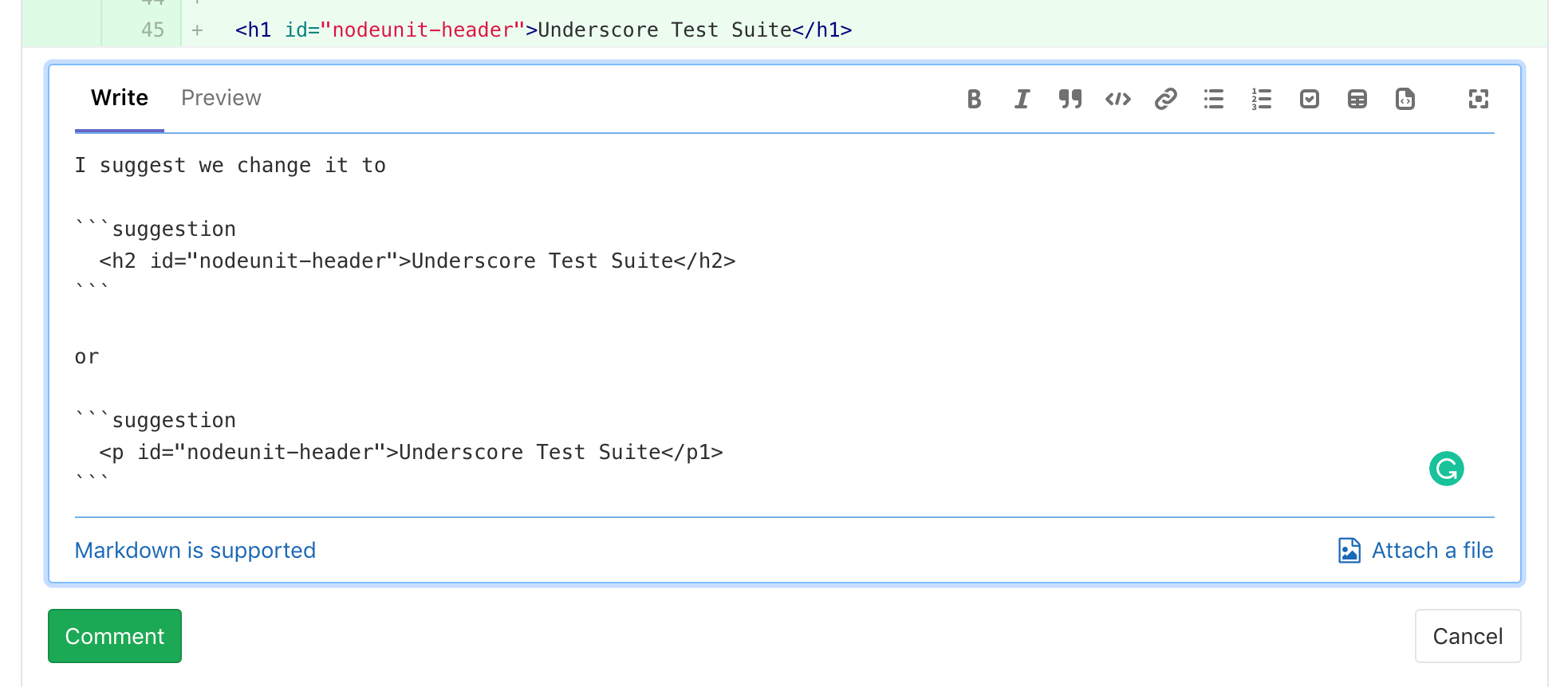
| W: | H:
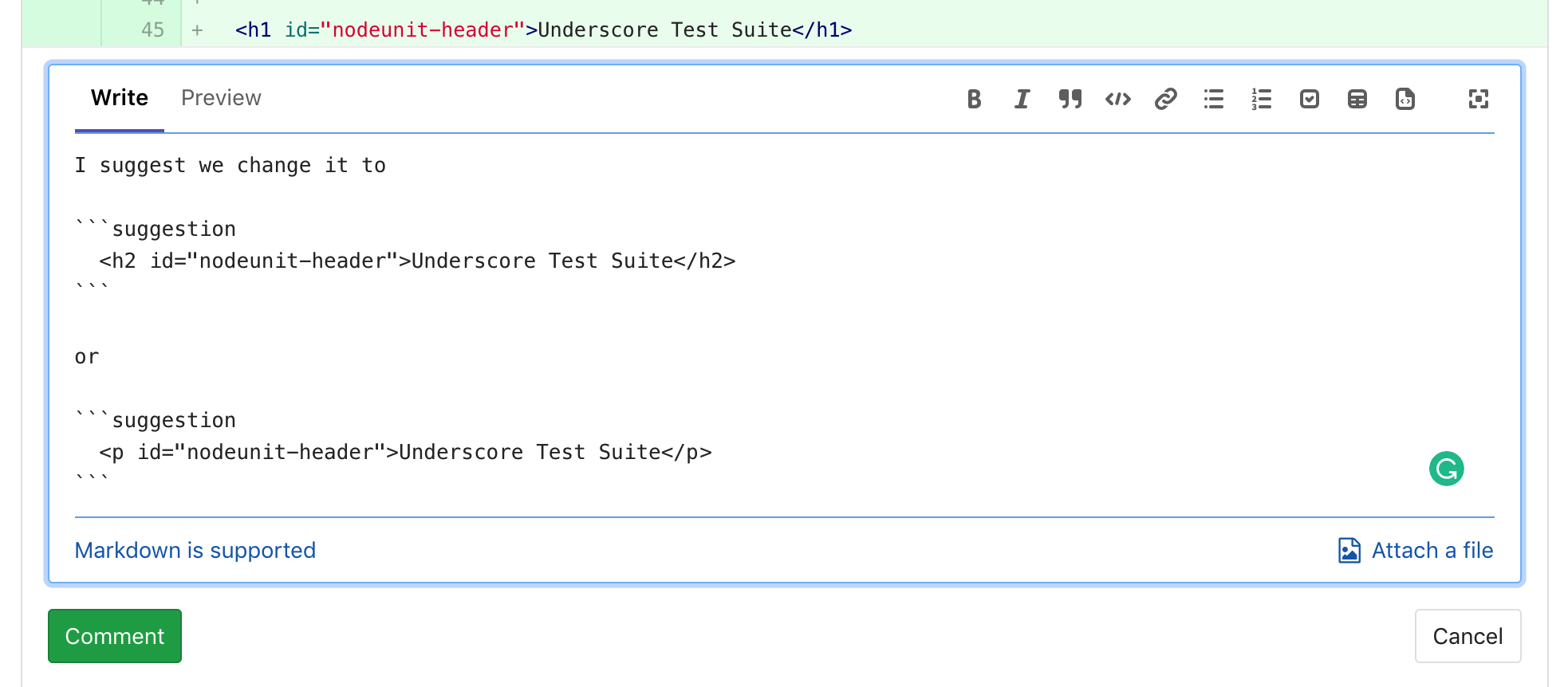
| W: | H:
{kind=link}
{kind=link}
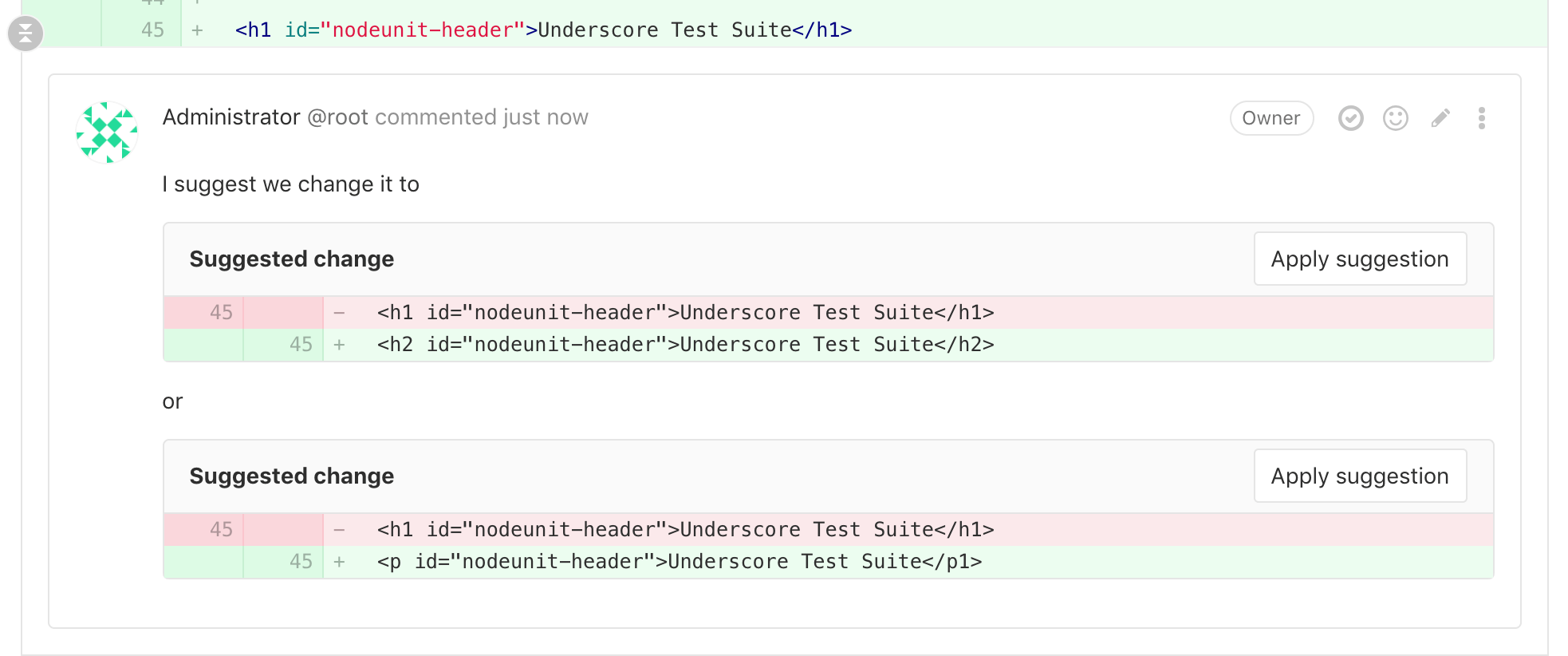
| W: | H:
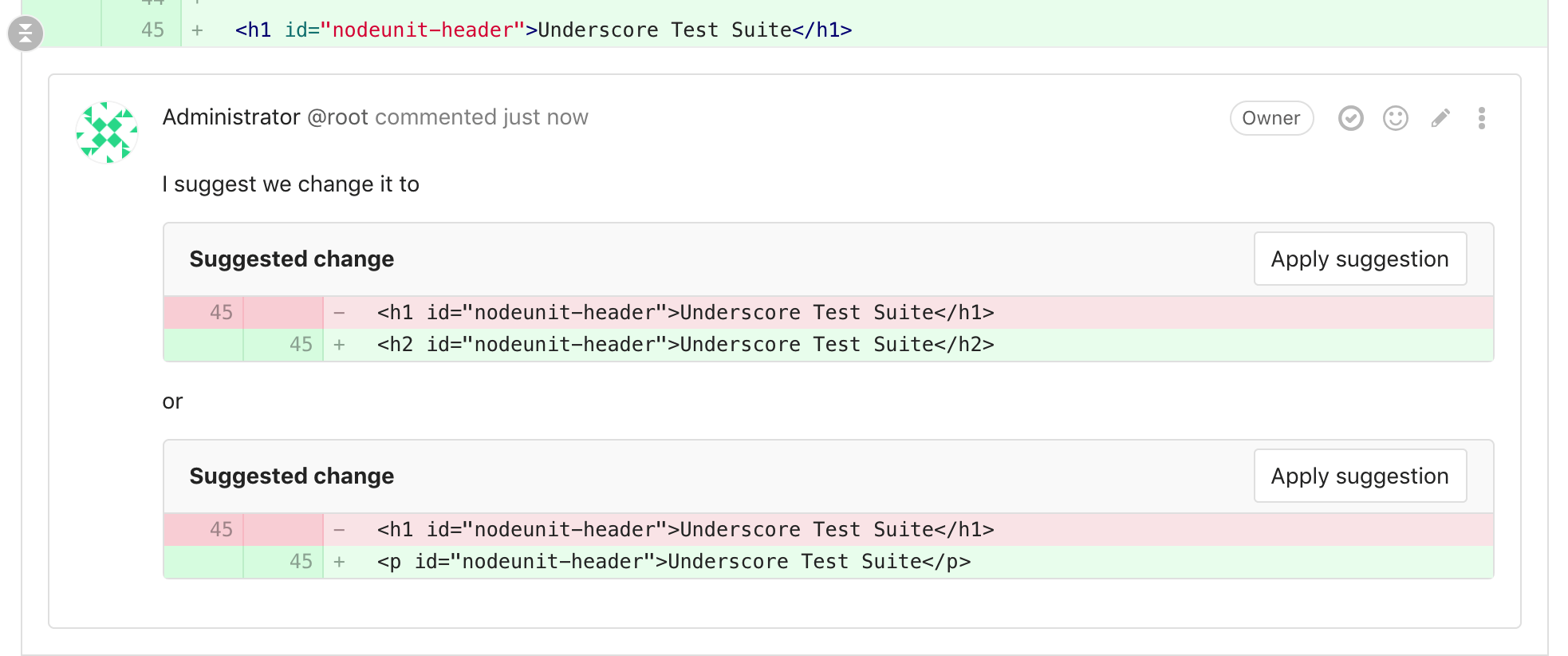
| W: | H:
{kind=link}
63.4 KB
{kind=link}
21.9 KB
{kind=link}
56.0 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动