2020-07-11 16:26:48
Showing
docs/effective-tf.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

1.4 MB
docs/learning-tf-zh/1.md
0 → 100644
此差异已折叠。
docs/learning-tf-zh/2.md
0 → 100644
此差异已折叠。
docs/learning-tf-zh/3.md
0 → 100644
此差异已折叠。
docs/learning-tf-zh/4.md
0 → 100644
此差异已折叠。
docs/learning-tf-zh/README.md
0 → 100644
docs/learning-tf-zh/SUMMARY.md
0 → 100644
{kind=link}

141.8 KB
docs/learning-tf-zh/img/GPU.jpg
0 → 100644
{kind=link}

82.7 KB
{kind=link}

5.6 MB
{kind=link}

291.6 KB
{kind=link}
457.1 KB
{kind=link}

428.9 KB
{kind=link}

36.7 KB
{kind=link}
18.4 KB
docs/learning-tf-zh/img/cube.png
0 → 100644
{kind=link}
30.7 KB
{kind=link}
37.6 KB
{kind=link}
39.3 KB
{kind=link}
6.9 KB
{kind=link}
2.0 MB
{kind=link}
4.6 KB
{kind=link}
4.1 KB
{kind=link}
4.8 KB
{kind=link}
4.8 KB
{kind=link}

4.4 KB
{kind=link}

4.2 KB
{kind=link}
25.9 KB
{kind=link}

11.3 KB
{kind=link}
41.7 KB
{kind=link}
36.7 KB
{kind=link}
12.3 KB
{kind=link}
18.6 KB
{kind=link}
19.8 KB
{kind=link}
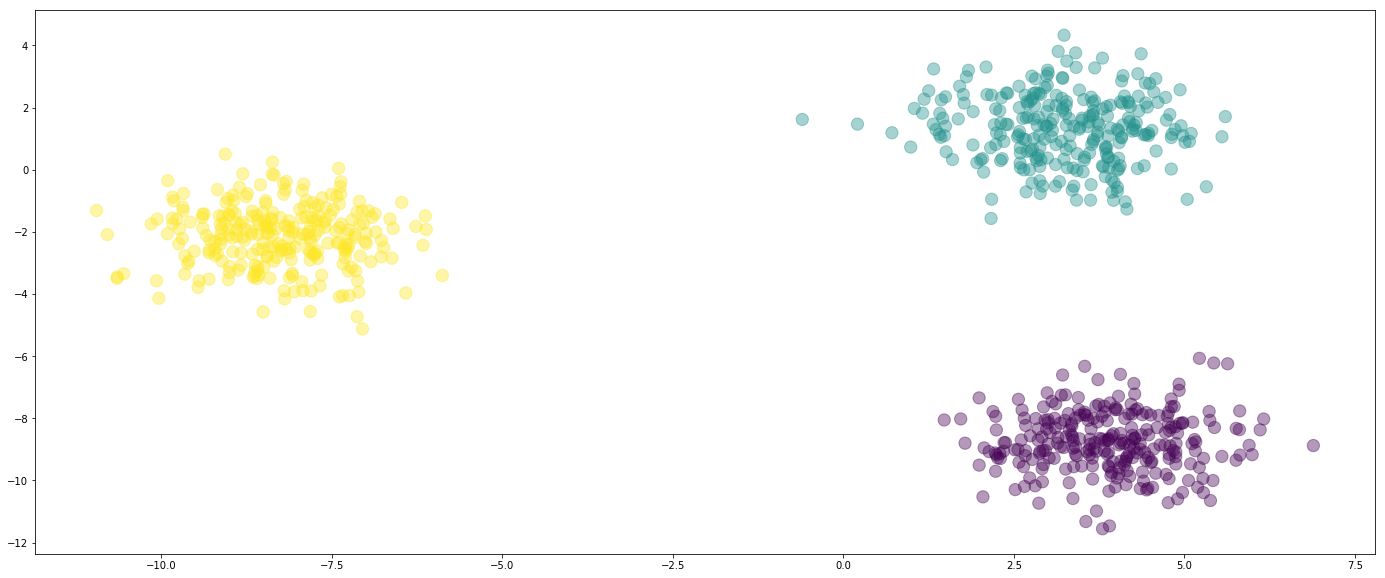
163.6 KB
docs/learning-tf-zh/img/redx.png
0 → 100644
{kind=link}
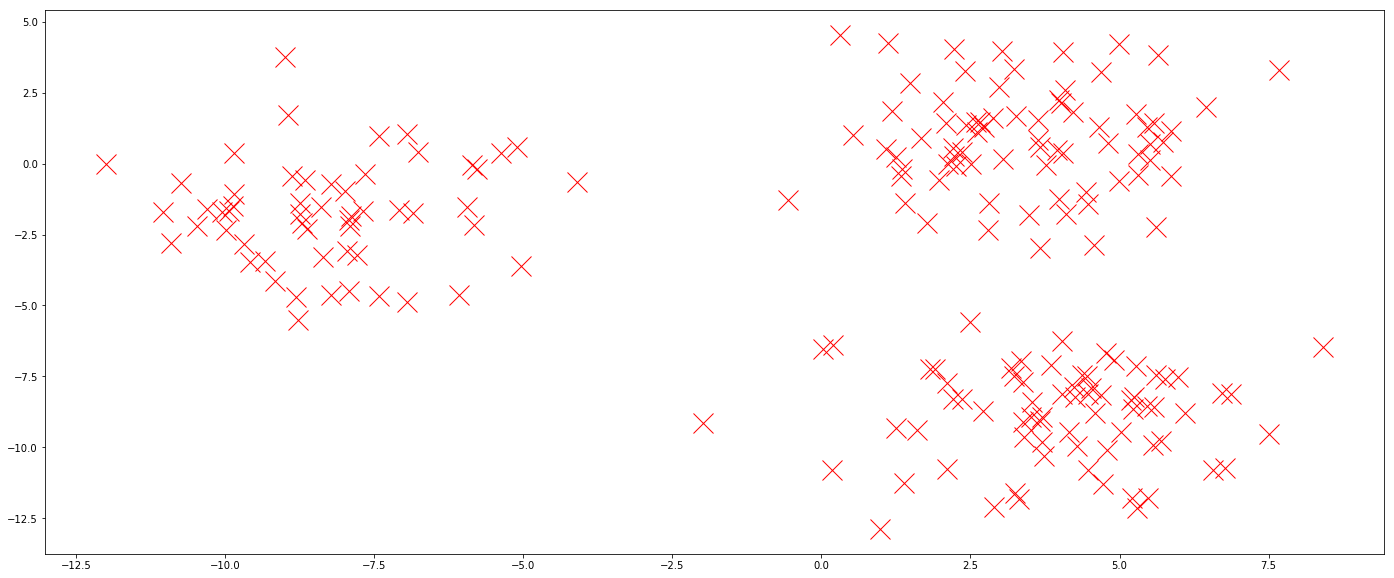
30.9 KB
{kind=link}
6.4 KB
{kind=link}
40.0 KB
{kind=link}
89.2 KB
{kind=link}
123.4 KB
docs/learning-tf-zh/img/tex1.gif
0 → 100644
{kind=link}
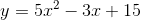
517 字节
docs/learning-tf-zh/img/tex10.gif
0 → 100644
{kind=link}
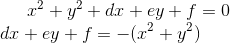
1.2 KB
docs/learning-tf-zh/img/tex11.gif
0 → 100644
{kind=link}
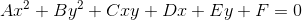
1.0 KB
docs/learning-tf-zh/img/tex12.gif
0 → 100644
{kind=link}
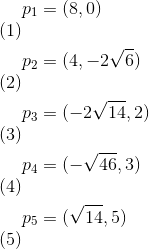
2.6 KB
docs/learning-tf-zh/img/tex2.gif
0 → 100644
{kind=link}
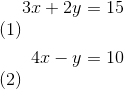
980 字节
docs/learning-tf-zh/img/tex3.gif
0 → 100644
{kind=link}
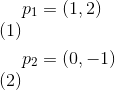
939 字节
docs/learning-tf-zh/img/tex4.gif
0 → 100644
{kind=link}
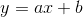
342 字节
docs/learning-tf-zh/img/tex5.gif
0 → 100644
{kind=link}
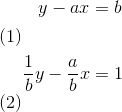
972 字节
docs/learning-tf-zh/img/tex6.gif
0 → 100644
{kind=link}
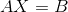
295 字节
docs/learning-tf-zh/img/tex7.gif
0 → 100644
{kind=link}
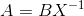
335 字节
docs/learning-tf-zh/img/tex8.gif
0 → 100644
{kind=link}
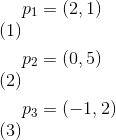
1.3 KB
docs/learning-tf-zh/img/tex9.gif
0 → 100644
{kind=link}
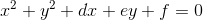
681 字节
docs/tf-eager-tut/1.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/2.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/3.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/4.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/5.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/6.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/7.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/8.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/9.md
0 → 100644
此差异已折叠。
docs/tf-eager-tut/README.md
0 → 100644
docs/tf-eager-tut/SUMMARY.md
0 → 100644
docs/tf-eager-tut/img/1-1.png
0 → 100644
{kind=link}
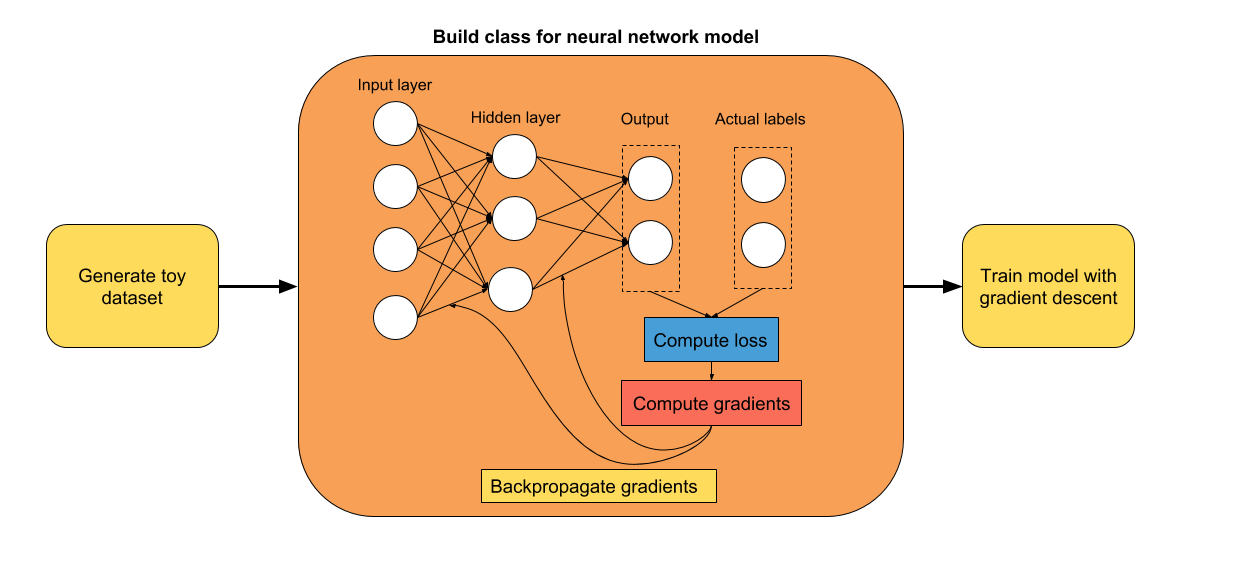
58.0 KB
docs/tf-eager-tut/img/1-2.png
0 → 100644
{kind=link}
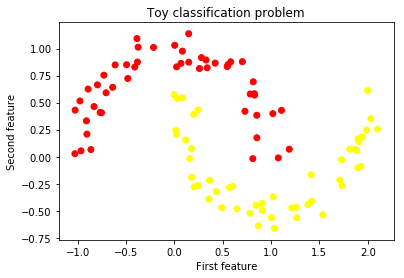
18.9 KB
docs/tf-eager-tut/img/1-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/2-6.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/3-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/4-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/5-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/6-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/6-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/7-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/7-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/7-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/7-4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/8-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/8-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/8-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/8-4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/8-5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-2.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-3.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-4.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-5.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-6.png
0 → 100644
{kind=link}
此差异已折叠。
docs/tf-eager-tut/img/9-7.png
0 → 100644
{kind=link}
此差异已折叠。
sidebar.md
0 → 100644
此差异已折叠。