- 25 2月, 2022 12 次提交
-
-
由 Dylan DPC 提交于
properly handle fat pointers to uninhabitable types Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this. Fixes #94149 r? ````@michaelwoerister```` since you touched this code last, I think!
-
由 Dylan DPC 提交于
Stop manually SIMDing in `swap_nonoverlapping` Like I previously did for `reverse` (#90821), this leaves it to LLVM to pick how to vectorize it, since it can know better the chunk size to use, compared to the "32 bytes always" approach we currently have. A variety of codegen tests are included to confirm that the various cases are still being vectorized. It does still need logic to type-erase in some cases, though, as while LLVM is now smart enough to vectorize over slices of things like `[u8; 4]`, it fails to do so over slices of `[u8; 3]`. As a bonus, this change also means one no longer gets the spurious `memcpy`(s?) at the end up swapping a slice of `__m256`s: <https://rust.godbolt.org/z/joofr4v8Y> <details> <summary>ASM for this example</summary> ## Before (from godbolt) note the `push`/`pop`s and `memcpy` ```x86 swap_m256_slice: push r15 push r14 push r13 push r12 push rbx sub rsp, 32 cmp rsi, rcx jne .LBB0_6 mov r14, rsi shl r14, 5 je .LBB0_6 mov r15, rdx mov rbx, rdi xor eax, eax .LBB0_3: mov rcx, rax vmovaps ymm0, ymmword ptr [rbx + rax] vmovaps ymm1, ymmword ptr [r15 + rax] vmovaps ymmword ptr [rbx + rax], ymm1 vmovaps ymmword ptr [r15 + rax], ymm0 add rax, 32 add rcx, 64 cmp rcx, r14 jbe .LBB0_3 sub r14, rax jbe .LBB0_6 add rbx, rax add r15, rax mov r12, rsp mov r13, qword ptr [rip + memcpy@GOTPCREL] mov rdi, r12 mov rsi, rbx mov rdx, r14 vzeroupper call r13 mov rdi, rbx mov rsi, r15 mov rdx, r14 call r13 mov rdi, r15 mov rsi, r12 mov rdx, r14 call r13 .LBB0_6: add rsp, 32 pop rbx pop r12 pop r13 pop r14 pop r15 vzeroupper ret ``` ## After (from my machine) Note no `rsp` manipulation, sorry for different ASM syntax ```x86 swap_m256_slice: cmpq %r9, %rdx jne .LBB1_6 testq %rdx, %rdx je .LBB1_6 cmpq $1, %rdx jne .LBB1_7 xorl %r10d, %r10d jmp .LBB1_4 .LBB1_7: movq %rdx, %r9 andq $-2, %r9 movl $32, %eax xorl %r10d, %r10d .p2align 4, 0x90 .LBB1_8: vmovaps -32(%rcx,%rax), %ymm0 vmovaps -32(%r8,%rax), %ymm1 vmovaps %ymm1, -32(%rcx,%rax) vmovaps %ymm0, -32(%r8,%rax) vmovaps (%rcx,%rax), %ymm0 vmovaps (%r8,%rax), %ymm1 vmovaps %ymm1, (%rcx,%rax) vmovaps %ymm0, (%r8,%rax) addq $2, %r10 addq $64, %rax cmpq %r10, %r9 jne .LBB1_8 .LBB1_4: testb $1, %dl je .LBB1_6 shlq $5, %r10 vmovaps (%rcx,%r10), %ymm0 vmovaps (%r8,%r10), %ymm1 vmovaps %ymm1, (%rcx,%r10) vmovaps %ymm0, (%r8,%r10) .LBB1_6: vzeroupper retq ``` </details> This does all its copying operations as either the original type or as `MaybeUninit`s, so as far as I know there should be no potential abstract machine issues with reading padding bytes as integers. <details> <summary>Perf is essentially unchanged</summary> Though perhaps with more target features this would help more, if it could pick bigger chunks ## Before ``` running 10 tests test slice::swap_with_slice_4x_usize_30 ... bench: 894 ns/iter (+/- 11) test slice::swap_with_slice_4x_usize_3000 ... bench: 99,476 ns/iter (+/- 2,784) test slice::swap_with_slice_5x_usize_30 ... bench: 1,257 ns/iter (+/- 7) test slice::swap_with_slice_5x_usize_3000 ... bench: 139,922 ns/iter (+/- 959) test slice::swap_with_slice_rgb_30 ... bench: 328 ns/iter (+/- 27) test slice::swap_with_slice_rgb_3000 ... bench: 16,215 ns/iter (+/- 176) test slice::swap_with_slice_u8_30 ... bench: 312 ns/iter (+/- 9) test slice::swap_with_slice_u8_3000 ... bench: 5,401 ns/iter (+/- 123) test slice::swap_with_slice_usize_30 ... bench: 368 ns/iter (+/- 3) test slice::swap_with_slice_usize_3000 ... bench: 28,472 ns/iter (+/- 3,913) ``` ## After ``` running 10 tests test slice::swap_with_slice_4x_usize_30 ... bench: 868 ns/iter (+/- 36) test slice::swap_with_slice_4x_usize_3000 ... bench: 99,642 ns/iter (+/- 1,507) test slice::swap_with_slice_5x_usize_30 ... bench: 1,194 ns/iter (+/- 11) test slice::swap_with_slice_5x_usize_3000 ... bench: 139,761 ns/iter (+/- 5,018) test slice::swap_with_slice_rgb_30 ... bench: 324 ns/iter (+/- 6) test slice::swap_with_slice_rgb_3000 ... bench: 15,962 ns/iter (+/- 287) test slice::swap_with_slice_u8_30 ... bench: 281 ns/iter (+/- 5) test slice::swap_with_slice_u8_3000 ... bench: 5,324 ns/iter (+/- 40) test slice::swap_with_slice_usize_30 ... bench: 275 ns/iter (+/- 5) test slice::swap_with_slice_usize_3000 ... bench: 28,277 ns/iter (+/- 277) ``` </detail>
-
由 Dylan DPC 提交于
Improve `--check-cfg` implementation This pull-request is a mix of improvements regarding the `--check-cfg` implementation: - Simpler internal representation (usage of `Option` instead of separate bool) - Add --check-cfg to the unstable book (based on the RFC) - Improved diagnostics: * List possible values when the value is unexpected * Suggest if possible a name or value that is similar - Add more tests (well known names, mix of combinations, ...) r? ```@petrochenkov``` -
由 Dylan DPC 提交于
better ObligationCause for normalization errors in `can_type_implement_copy` Some logic is needed so we can point to the field when given totally nonsense types like `struct Foo(<u32 as Iterator>::Item);` Fixes #93687
-
由 Dylan DPC 提交于
resolve/metadata: Stop encoding macros as reexports Supersedes https://github.com/rust-lang/rust/pull/88335. r? `@cjgillot`
-
由 Vadim Petrochenkov 提交于
-
由 Vadim Petrochenkov 提交于
-
由 Vadim Petrochenkov 提交于
To make the `macro_rules` flag more readily available without decoding everything else
-
由 Vadim Petrochenkov 提交于
Previously it always returned `MacroKind::Bang` while some of those macros are actually attributes and derives
-
由 bors 提交于
Always format to internal String in FmtPrinter This avoids monomorphizing for different parameters, decreasing generic code instantiated downstream from rustc_middle -- locally seeing 7% unoptimized LLVM IR line wins on rustc_borrowck, for example. We likely can't/shouldn't get rid of the Result-ness on most functions, though some further cleanup avoiding fmt::Error where we now know it won't occur may be possible, though somewhat painful -- fmt::Write is a pretty annoying API to work with in practice when you're trying to use it infallibly.
-
由 Michael Goulet 提交于
-
由 Michael Goulet 提交于
-
- 24 2月, 2022 23 次提交
-
-
由 bors 提交于
Partially move cg_ssa towards using a single builder Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.) `@antoyo` please review the cg_gcc changes.
-
由 bjorn3 提交于
-
由 bors 提交于
Rollup of 9 pull requests Successful merges: - #89887 (Change `char` type in debuginfo to DW_ATE_UTF) - #94267 (Remove unused ordering derivations and bounds for `SimplifiedTypeGen`) - #94270 (Miri: relax fn ptr check) - #94273 (add matching doc to errorkind) - #94283 (remove feature gate in control_flow examples) - #94288 (Cleanup a few Decoder methods) - #94292 (riscv32imc_esp_espidf: set max_atomic_width to 64) - #94296 (
⬆ rust-analyzer) - #94300 (Fix a typo in documentation of `array::IntoIter::new_unchecked`) Failed merges: r? `@ghost` `@rustbot` modify labels: rollup -
由 Matthias Krüger 提交于
Fix a typo in documentation of `array::IntoIter::new_unchecked`
🌸 -
由 Matthias Krüger 提交于
⬆ rust-analyzer r? `@ghost` -
由 Matthias Krüger 提交于
riscv32imc_esp_espidf: set max_atomic_width to 64 For espidf targets without native atomics, there is atomic emulation inside [the newlib component of espidf](https://github.com/espressif/esp-idf/blob/master/components/newlib/stdatomic.c), this has been extended to support emulation up to 64bits therefore we are safe to increase the atomic width for the `riscv32imc_esp_espidf` target. Closes https://github.com/esp-rs/rust/issues/107 cc: `@ivmarkov`
-
由 Matthias Krüger 提交于
Cleanup a few Decoder methods This is just some simple follow up to #93839. r? `@nnethercote`
-
由 Matthias Krüger 提交于
remove feature gate in control_flow examples Stabilization was done in https://github.com/rust-lang/rust/pull/91091, but the two examples weren't updated accordingly. Probably too late to put it into stable, but it should be in the next release :)
-
由 Matthias Krüger 提交于
add matching doc to errorkind Rework of #90706
-
由 Matthias Krüger 提交于
Miri: relax fn ptr check As discussed in https://github.com/rust-lang/unsafe-code-guidelines/issues/72#issuecomment-1025407536, the function pointer check done by Miri is currently overeager: contrary to our usual principle of only checking rather uncontroversial validity invariants, we actually check that the pointer points to a real function. So, this relaxes the check to what the validity invariant probably will be (and what the reference already says it is): the function pointer must be non-null, and that's it. The check that CTFE does on the final value of a constant is unchanged -- CTFE recurses through references, so it makes some sense to also recurse through function pointers. We might still want to relax this in the future, but that would be a separate change. r? `@oli-obk`
-
由 Matthias Krüger 提交于
Remove unused ordering derivations and bounds for `SimplifiedTypeGen` This is another small PR clearing the way for work on #90317.
-
由 Matthias Krüger 提交于
Change `char` type in debuginfo to DW_ATE_UTF Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`. Clang also uses the DW_ATE_UTF for `char32_t` in C++. This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window. 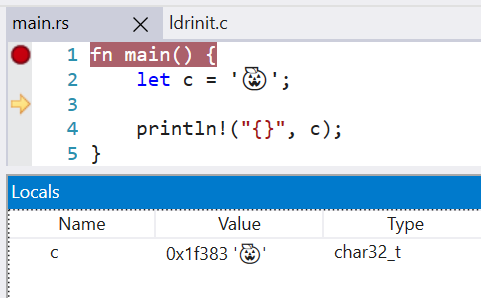 LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32` r? `@wesleywiser`
-
由 bors 提交于
Reapply cg_llvm: `fewer_names` in `uncached_llvm_type` r? `@davidtwco` `@erikdesjardins`
-
由 bors 提交于
Node id to hir id refactor Related to #89278 r? `@oli-obk`
-
由 Dylan DPC 提交于
-
由 Dylan DPC 提交于
-
由 Dylan DPC 提交于
Co-authored-by: NJosh Triplett <josh@joshtriplett.org> -
由 Ralf Jung 提交于
-
由 bors 提交于
Rollup of 12 pull requests Successful merges: - #94128 (rustdoc: several minor fixes) - #94137 (rustdoc-json: Better Header Type) - #94213 (fix names in feature(...) suggestion) - #94240 (Suggest calling .display() on `PathBuf` too) - #94253 (Use 2021 edition in ./x.py fmt) - #94259 (Bump download-ci-llvm-stamp for llvm-nm inclusion) - #94260 (Fix rustdoc infinite redirection generation) - #94263 (Typo fix: Close inline-code backtick) - #94264 (Fix typo.) - #94271 (Miri: extend comments on downcast operation) - #94280 (Rename `region_should_not_be_omitted` to `should_print_region`) - #94285 (Sync rustc_codegen_cranelift) Failed merges: r? `@ghost` `@rustbot` modify labels: rollup
-
由 Waffle Maybe 提交于
-
由 Arlo Siemsen 提交于
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is DW_ATE_UTF. Clang uses this same debug encoding for char32_t. This fixes the display of `char` types in Windows debuggers as well as LLDB.
-
由 Michael Goulet 提交于
-
- 23 2月, 2022 5 次提交
-
-
由 Laurențiu Nicola 提交于
-
由 Scott Mabin 提交于
-
由 Loïc BRANSTETT 提交于
-
由 Loïc BRANSTETT 提交于
- Test the combinations of --check-cfg with partial values() and --cfg - Test that we detect unexpected value when none are expected
-
由 Matthias Krüger 提交于
Sync rustc_codegen_cranelift r? `@ghost` `@rustbot` label +A-codegen +A-cranelift +T-compiler
-