Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Hypo
candock
提交
5ee4d56d
C
candock
项目概览
Hypo
/
candock
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
candock
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
5ee4d56d
编写于
6月 13, 2020
作者:
H
hypox64
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Fix autoencoder
上级
49bbc039
变更
9
隐藏空白更改
内联
并排
Showing
9 changed file
with
49 addition
and
39 deletion
+49
-39
README.md
README.md
+3
-2
README_CN.md
README_CN.md
+2
-2
imgs/running_err_eg.png
imgs/running_err_eg.png
+0
-0
imgs/running_loss_eg.png
imgs/running_loss_eg.png
+0
-0
models/core.py
models/core.py
+21
-19
tools/client.py
tools/client.py
+1
-1
tools/server.py
tools/server.py
+1
-0
util/dsp.py
util/dsp.py
+0
-9
util/plot.py
util/plot.py
+21
-6
未找到文件。
README.md
浏览文件 @
5ee4d56d
...
...
@@ -4,10 +4,11 @@
# candock
| English |
[
中文版
](
./README_CN.md
)
|
<br>
| English |
[
中文版
](
./README_CN.md
)
|
<br>
<br>
A time series signal analysis and classification framework.
<br>
It contain multiple network and provide data preprocessing, reading, training, evaluation, testing and other functions.
<br>
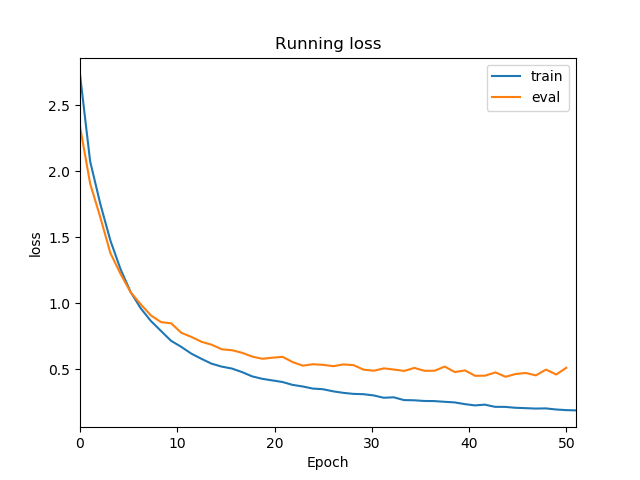
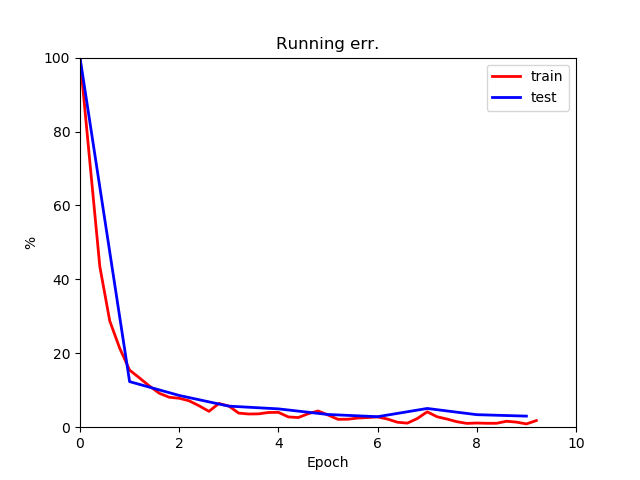
Some output examples:
[
heatmap
](
./image/heatmap_eg.png
)
[
running_err
]
(./image/running_err_eg.png)
[
log.txt
](
./docs/log_eg.txt
)
<br>
Supported network:
<br>
Some output examples:
[
heatmap
](
./image/heatmap_eg.png
)
[
running_loss
]
(./image/running_loss_eg.png)
[
log.txt
](
./docs/log_eg.txt
)
<br>
Supported network:
<br>
>1d
>
...
...
README_CN.md
浏览文件 @
5ee4d56d
...
...
@@ -4,10 +4,10 @@
# candock
|
[
English
](
./README.md
)
| 中文版 |
<br>
|
[
English
](
./README.md
)
| 中文版 |
<br>
<br>
一个通用的一维时序信号分析,分类框架.
<br>
它将包含多种网络结构,并提供数据预处理,读取,训练,评估,测试等功能.
<br>
一些训练时的输出样例:
[
heatmap
](
./image/heatmap_eg.png
)
[
running_
err
]
(./image/running_err
_eg.png)
[
log.txt
](
./docs/log_eg.txt
)
<br>
一些训练时的输出样例:
[
heatmap
](
./image/heatmap_eg.png
)
[
running_
loss
]
(./image/running_loss
_eg.png)
[
log.txt
](
./docs/log_eg.txt
)
<br>
目前支持的网络结构:
<br>
>1d
>
...
...
imgs/running_err_eg.png
已删除
100644 → 0
浏览文件 @
49bbc039
20.6 KB
imgs/running_loss_eg.png
0 → 100644
浏览文件 @
5ee4d56d
24.0 KB
models/core.py
浏览文件 @
5ee4d56d
...
...
@@ -34,15 +34,15 @@ class Core(object):
self
.
net
=
creatnet
.
creatnet
(
self
.
opt
)
self
.
optimizer
=
torch
.
optim
.
Adam
(
self
.
net
.
parameters
(),
lr
=
self
.
opt
.
lr
)
self
.
criterion_class
=
nn
.
CrossEntropyLoss
(
self
.
opt
.
weight
)
self
.
criterion_auto
=
nn
.
MSELoss
()
self
.
criterion_class
ifier
=
nn
.
CrossEntropyLoss
(
self
.
opt
.
weight
)
self
.
criterion_auto
encoder
=
nn
.
MSELoss
()
self
.
epoch
=
1
self
.
plot_result
=
{
'train'
:[],
'eval'
:[],
'F1'
:[]}
self
.
confusion_mats
=
[]
self
.
test_flag
=
True
if
printflag
:
#
util.writelog('network:\n'+str(self.net),self.opt,True)
util
.
writelog
(
'network:
\n
'
+
str
(
self
.
net
),
self
.
opt
,
True
)
show_paramsnumber
(
self
.
net
,
self
.
opt
)
if
self
.
opt
.
pretrained
!=
''
:
...
...
@@ -97,31 +97,33 @@ class Core(object):
def
forward
(
self
,
signal
,
label
,
features
,
confusion_mat
):
if
self
.
opt
.
model_name
==
'autoencoder'
:
out
,
feature
=
self
.
net
(
signal
)
loss
=
self
.
criterion_auto
(
out
,
signal
)
features
[
i
*
self
.
opt
.
batchsize
:(
i
+
1
)
*
self
.
opt
.
batchsize
,:
self
.
opt
.
feature
]
=
(
feature
.
data
.
cpu
().
numpy
()).
reshape
(
self
.
opt
.
batchsize
,
-
1
)
features
[
i
*
self
.
opt
.
batchsize
:(
i
+
1
)
*
self
.
opt
.
batchsize
,
self
.
opt
.
feature
]
=
label
.
data
.
cpu
().
numpy
()
loss
=
self
.
criterion_autoencoder
(
out
,
signal
)
label
=
label
.
data
.
cpu
().
numpy
()
feature
=
(
feature
.
data
.
cpu
().
numpy
()).
reshape
(
self
.
opt
.
batchsize
,
-
1
)
for
i
in
range
(
self
.
opt
.
batchsize
):
features
.
append
(
np
.
concatenate
((
feature
[
i
],
[
label
[
i
]])))
else
:
out
=
self
.
net
(
signal
)
loss
=
self
.
criterion_class
(
out
,
label
)
loss
=
self
.
criterion_class
ifier
(
out
,
label
)
pred
=
(
torch
.
max
(
out
,
1
)[
1
]).
data
.
cpu
().
numpy
()
label
=
label
.
data
.
cpu
().
numpy
()
label
=
label
.
data
.
cpu
().
numpy
()
for
x
in
range
(
len
(
pred
)):
confusion_mat
[
label
[
x
]][
pred
[
x
]]
+=
1
return
loss
,
features
,
confusion_mat
return
out
,
loss
,
features
,
confusion_mat
def
train
(
self
,
signals
,
labels
,
sequences
):
self
.
net
.
train
()
self
.
test_flag
=
False
features
=
[]
epoch_loss
=
0
confusion_mat
=
np
.
zeros
((
self
.
opt
.
label
,
self
.
opt
.
label
),
dtype
=
int
)
features
=
np
.
zeros
((
len
(
sequences
)
//
self
.
opt
.
batchsize
*
self
.
opt
.
batchsize
,
self
.
opt
.
feature
+
1
))
np
.
random
.
shuffle
(
sequences
)
self
.
process_pool_init
(
signals
,
labels
,
sequences
)
for
i
in
range
(
len
(
sequences
)
//
self
.
opt
.
batchsize
):
signal
,
label
=
self
.
queue
.
get
()
signal
,
label
=
transformer
.
ToTensor
(
signal
,
label
,
gpu_id
=
self
.
opt
.
gpu_id
)
loss
,
features
,
confusion_mat
=
self
.
forward
(
signal
,
label
,
features
,
confusion_mat
)
output
,
loss
,
features
,
confusion_mat
=
self
.
forward
(
signal
,
label
,
features
,
confusion_mat
)
epoch_loss
+=
loss
.
item
()
self
.
optimizer
.
zero_grad
()
...
...
@@ -136,27 +138,27 @@ class Core(object):
def
eval
(
self
,
signals
,
labels
,
sequences
):
self
.
test_flag
=
True
confusion_mat
=
np
.
zeros
((
self
.
opt
.
label
,
self
.
opt
.
label
),
dtype
=
int
)
features
=
np
.
zeros
((
len
(
sequences
)
//
self
.
opt
.
batchsize
*
self
.
opt
.
batchsize
,
self
.
opt
.
feature
+
1
))
features
=
[]
epoch_loss
=
0
confusion_mat
=
np
.
zeros
((
self
.
opt
.
label
,
self
.
opt
.
label
),
dtype
=
int
)
self
.
process_pool_init
(
signals
,
labels
,
sequences
)
for
i
in
range
(
len
(
sequences
)
//
self
.
opt
.
batchsize
):
signal
,
label
=
self
.
queue
.
get
()
signal
,
label
=
transformer
.
ToTensor
(
signal
,
label
,
gpu_id
=
self
.
opt
.
gpu_id
)
with
torch
.
no_grad
():
loss
,
features
,
confusion_mat
=
self
.
forward
(
signal
,
label
,
features
,
confusion_mat
)
output
,
loss
,
features
,
confusion_mat
=
self
.
forward
(
signal
,
label
,
features
,
confusion_mat
)
epoch_loss
+=
loss
.
item
()
if
self
.
opt
.
model_name
!=
'autoencoder'
:
if
self
.
opt
.
model_name
==
'autoencoder'
:
plot
.
draw_autoencoder_result
(
signal
.
data
.
cpu
().
numpy
(),
output
.
data
.
cpu
().
numpy
(),
self
.
opt
)
print
(
'epoch:'
+
str
(
self
.
epoch
),
' loss: '
+
str
(
round
(
epoch_loss
/
i
,
5
)))
plot
.
draw_scatter
(
features
,
self
.
opt
)
else
:
recall
,
acc
,
sp
,
err
,
k
=
statistics
.
report
(
confusion_mat
)
#plot.draw_heatmap(confusion_mat,self.opt,name = 'current_eval')
print
(
'epoch:'
+
str
(
self
.
epoch
),
' macro-prec,reca,F1,err,kappa: '
+
str
(
statistics
.
report
(
confusion_mat
)))
self
.
plot_result
[
'F1'
].
append
(
statistics
.
report
(
confusion_mat
)[
2
])
else
:
plot
.
draw_autoencoder_result
(
signal
.
data
.
cpu
().
numpy
(),
out
.
data
.
cpu
().
numpy
(),
self
.
opt
)
print
(
'epoch:'
+
str
(
self
.
epoch
),
' loss: '
+
str
(
round
(
epoch_loss
/
i
,
5
)))
plot
.
draw_scatter
(
features
,
self
.
opt
)
self
.
plot_result
[
'eval'
].
append
(
epoch_loss
/
i
)
...
...
tools/client.py
浏览文件 @
5ee4d56d
...
...
@@ -45,7 +45,7 @@ return: {'return' : 'done',
}
"""
data
=
{
'token'
:
opt
.
token
,
'mode'
:
'train'
}
r
=
requests
.
post
(
opt
.
url
,
data
)
r
=
requests
.
post
(
opt
.
url
,
data
,
timeout
=
60
)
rec_data
=
r
.
json
()
print
(
rec_data
[
'report'
])
...
...
tools/server.py
浏览文件 @
5ee4d56d
...
...
@@ -32,6 +32,7 @@ core.network_init(printflag=True)
# -----------------------------train-----------------------------
def
train
(
opt
):
core
.
network_init
(
printflag
=
True
)
categorys
=
os
.
listdir
(
opt
.
rec_tmp
)
categorys
.
sort
()
...
...
util/dsp.py
浏览文件 @
5ee4d56d
...
...
@@ -94,15 +94,6 @@ def signal2spectrum(data,window_size, stride, n_downsample=1, log = True, log_al
spectrum
=
spectrum_new
spectrum
=
(
spectrum
-
0.05
)
/
0.25
# spectrum = np.log1p(spectrum)
# h = window_size//2+1
# tmp = np.linspace(0, h-1,num=h,dtype=np.int64)
# index = np.log2(tmp+1)*(h/np.log2(h+1))
# spectrum_new = np.zeros_like(spectrum)
# for i in range(h-1):
# spectrum_new[int(index[i]):int(index[i+1])] = spectrum[i]
# spectrum = spectrum_new
# spectrum = (spectrum-0.05)/0.25
else
:
spectrum
=
(
spectrum
-
0.02
)
/
0.05
...
...
util/plot.py
浏览文件 @
5ee4d56d
...
...
@@ -9,11 +9,11 @@ markers = ['o','^','.',',','v','<','>','1','2','3','4','s','p','*','h','H','+','
#---------------------------------heatmap---------------------------------
'''
"""
heatmap: https://matplotlib.org/gallery/images_contours_and_fields/image_annotated_heatmap.html#sphx-glr-gallery-images-contours-and-fields-image-annotated-heatmap-py
choose color:https://matplotlib.org/tutorials/colors/colormaps.html?highlight=wistia
recommend: YlGn Wistia Blues YlOrBr
'''
"""
def
create_heatmap
(
data
,
row_labels
,
col_labels
,
ax
=
None
,
cbar_kw
=
{},
cbarlabel
=
""
,
**
kwargs
):
"""
...
...
@@ -193,6 +193,8 @@ def label_statistics(labels):
return
label_cnt
,
label_cnt_per
,
label_num
def
draw_scatter
(
data
,
opt
):
data
=
np
.
array
(
data
)
data
=
data
[
np
.
argsort
(
data
[:,
-
1
])]
label_cnt
,
_
,
label_num
=
label_statistics
(
data
[:,
-
1
])
fig
=
plt
.
figure
(
figsize
=
(
12
,
9
))
cnt
=
0
...
...
@@ -205,23 +207,36 @@ def draw_scatter(data,opt):
data_dimension
=
3
if
data_dimension
==
2
:
plt
.
xlim
(
-
1.5
,
1.5
)
plt
.
ylim
(
-
1.5
,
1.5
)
for
i
in
range
(
label_num
):
plt
.
scatter
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
0
],
data
[
cnt
:
cnt
+
label_cnt
[
i
],
1
],
plt
.
scatter
(
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
0
])[:
100
],
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
1
])[:
100
],
label
=
str
(
i
),
)
cnt
+=
label_cnt
[
i
]
elif
data_dimension
==
3
:
ax
=
fig
.
add_subplot
(
111
,
projection
=
'3d'
)
ax
.
set_zlim3d
(
-
1.5
,
1.5
)
ax
.
set_ylim3d
(
-
1.5
,
1.5
)
ax
.
set_xlim3d
(
-
1.5
,
1.5
)
for
i
in
range
(
label_num
):
ax
.
scatter
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
0
],
data
[
cnt
:
cnt
+
label_cnt
[
i
],
1
],
data
[
cnt
:
cnt
+
label_cnt
[
i
],
2
],
ax
.
scatter
(
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
0
])[:
100
],
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
1
])[:
100
],
(
data
[
cnt
:
cnt
+
label_cnt
[
i
],
2
])[:
100
],
label
=
str
(
i
),
)
cnt
+=
label_cnt
[
i
]
plt
.
title
(
'Autoencoder Embedding Result'
)
plt
.
legend
(
loc
=
2
)
plt
.
savefig
(
os
.
path
.
join
(
opt
.
save_dir
,
'feature_scatter.png'
))
np
.
save
(
os
.
path
.
join
(
opt
.
save_dir
,
'feature_scatter.npy'
),
data
)
plt
.
close
(
'all'
)
def
draw_autoencoder_result
(
true_signal
,
pred_signal
,
opt
):
plt
.
subplot
(
211
)
plt
.
plot
(
true_signal
[
0
][
0
])
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}