0.11953
Showing
analysis.py
0 → 100644
images/0.026778_85_krr.png
0 → 100644
{kind=link}
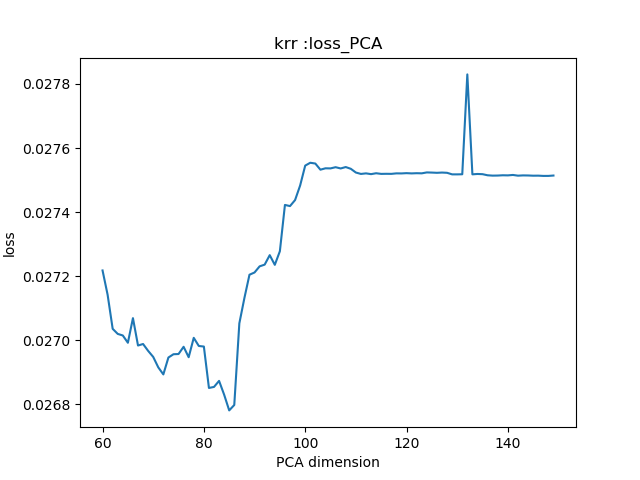
25.8 KB
images/0.028606_114_model_svr.png
0 → 100644
{kind=link}
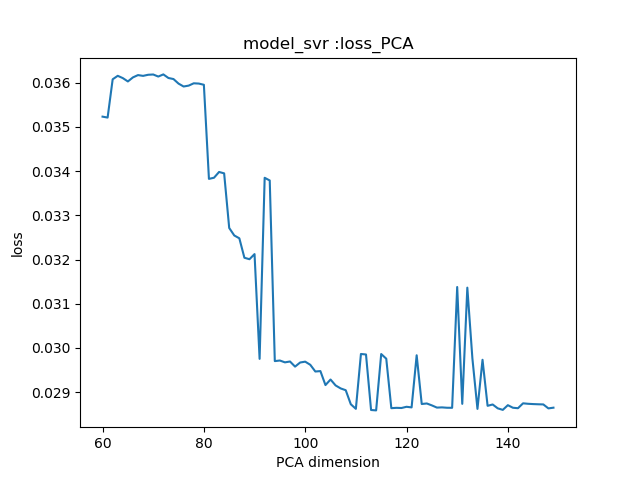
32.5 KB
images/0.029568_138_bay.png
0 → 100644
{kind=link}
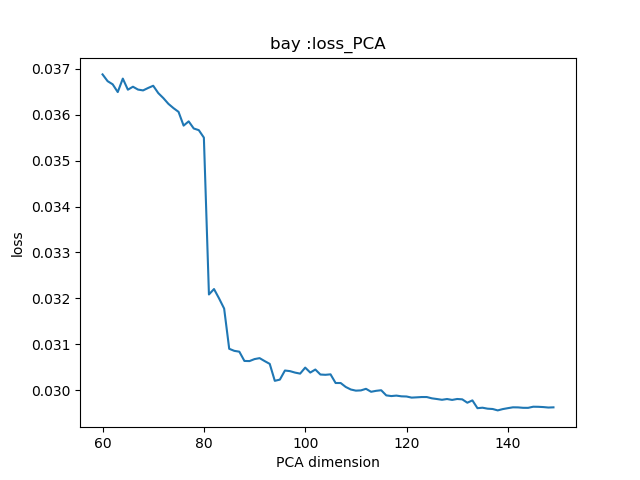
25.3 KB
images/0.030053_137_las.png
0 → 100644
{kind=link}
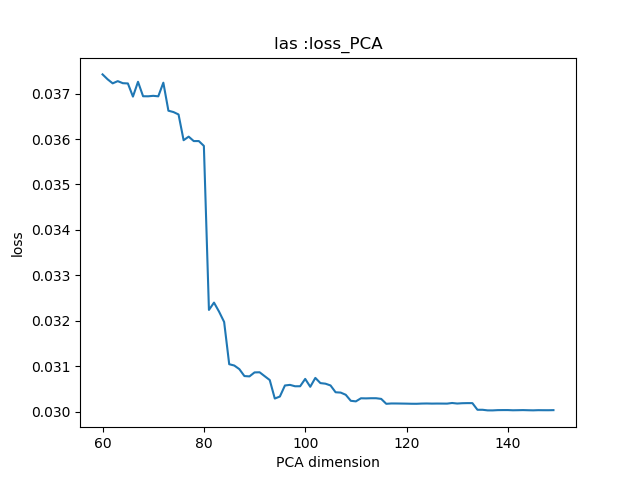
24.7 KB
images/0.030281_138_ENet.png
0 → 100644
{kind=link}
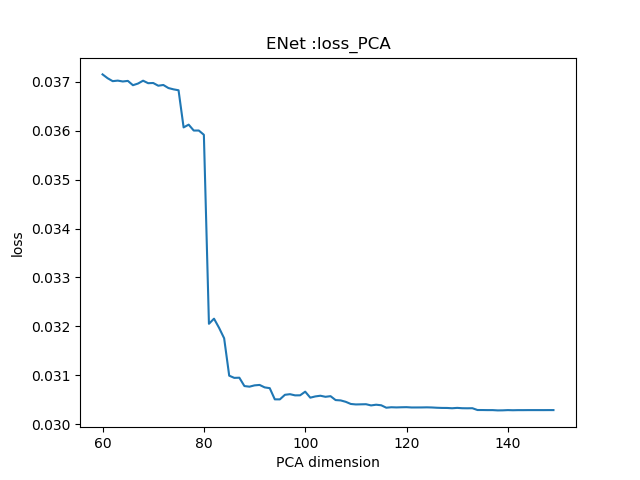
23.3 KB
images/0.033188_65_model_lgb.png
0 → 100644
{kind=link}
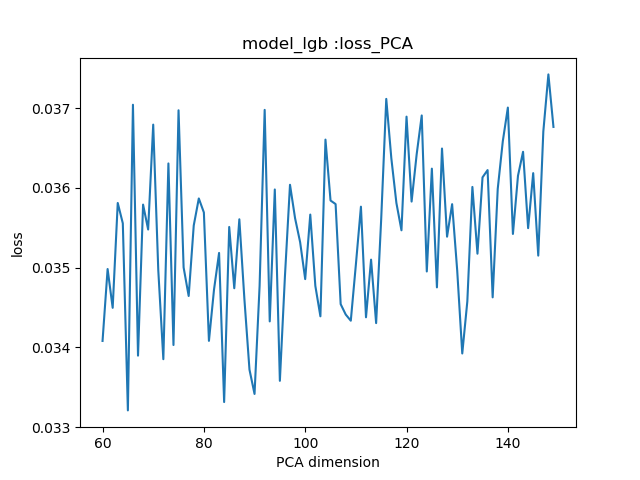
52.0 KB
images/0.036021_82_GBoost.png
0 → 100644
{kind=link}
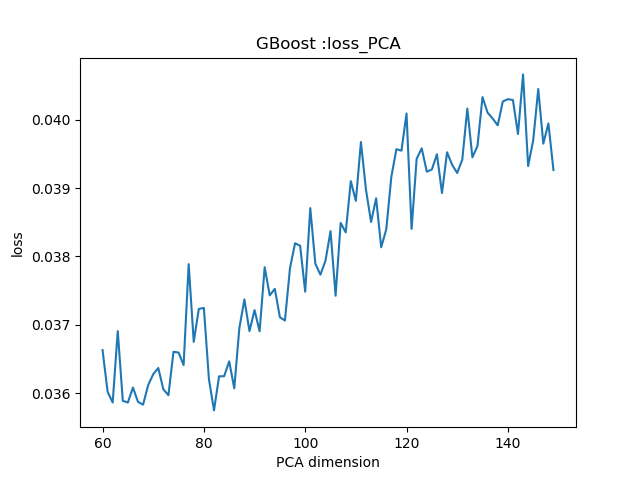
37.1 KB
images/0.040413_121_model_xgb.png
0 → 100644
{kind=link}
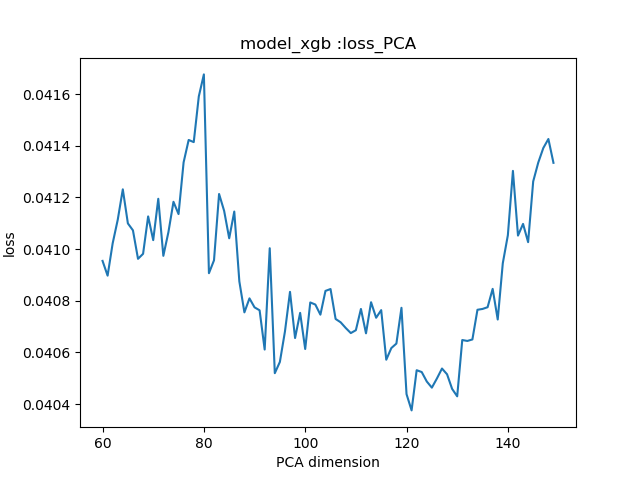
38.1 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。