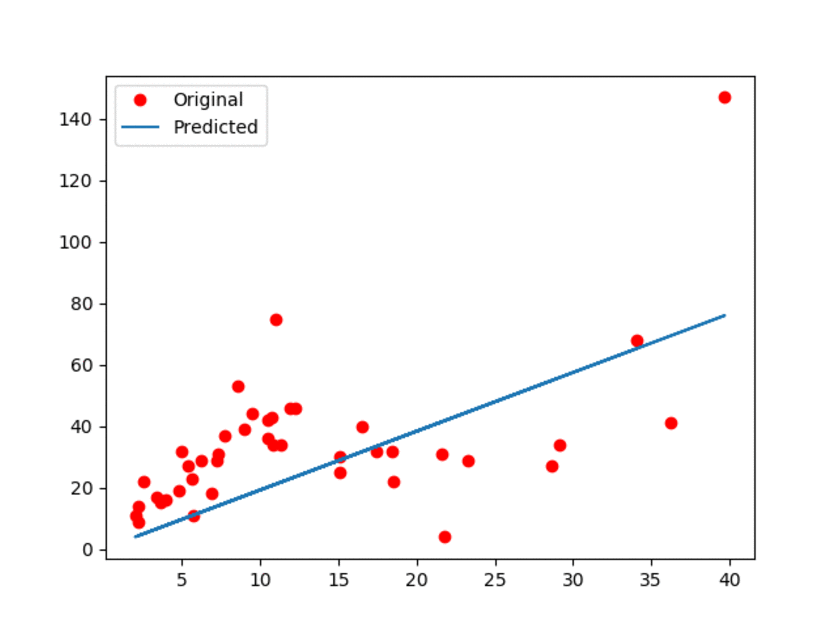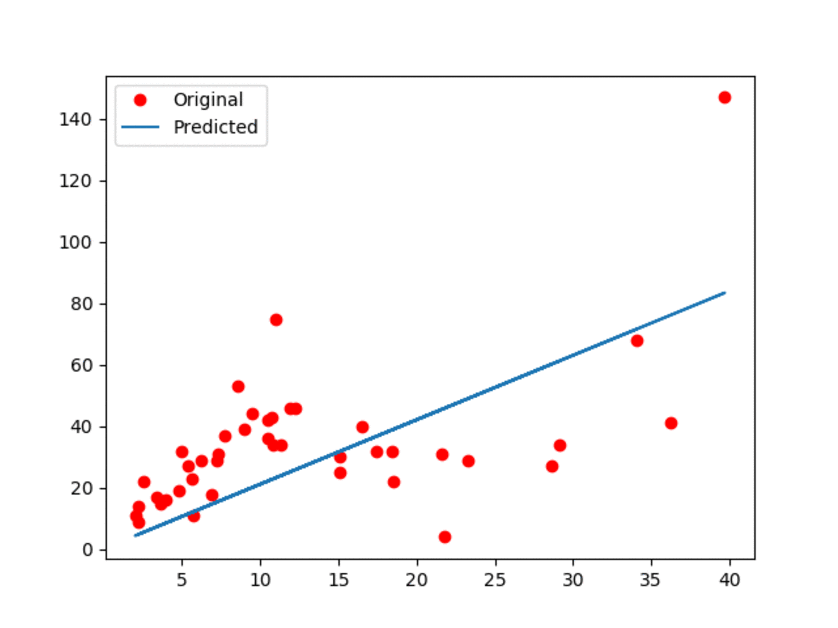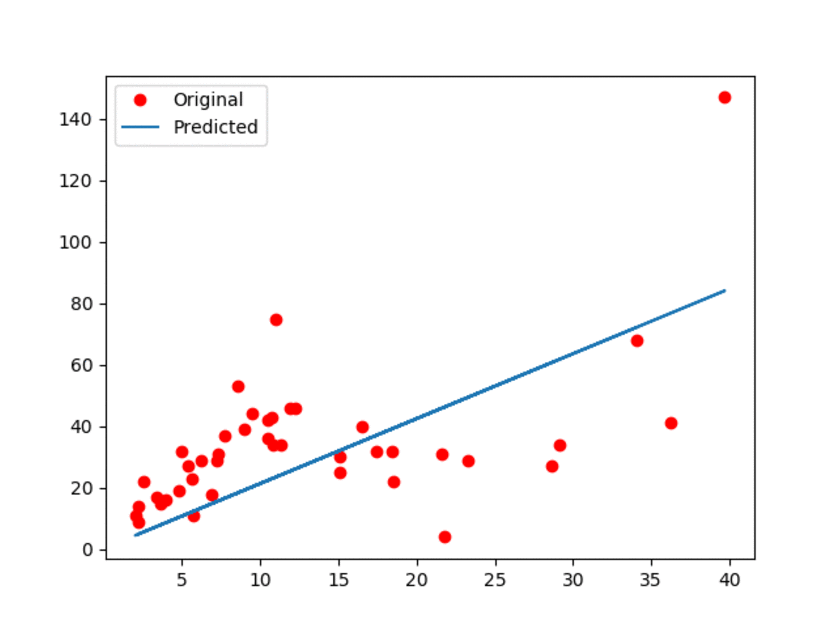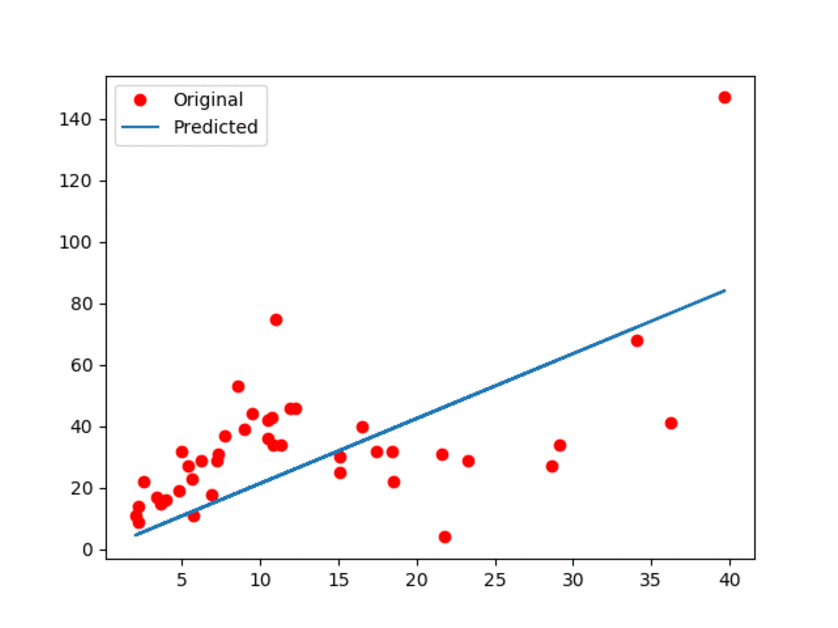
This document is dedicated to explain how to run the python script for this tutorial. The documentation is available `here <Documentationlinearregression_>`_. Alternatively, you can check this ``Linear Regression using TensorFlow`` `blog post <blogpostlinearregression_>`_ for further details.
``WARNING:`` If TensorFlow is installed in any environment(virtual environment, ...), it must be activated at first. So at first make sure the tensorFlow is available in the current environment using the following script:
--------------------------------
How to run the code in Terminal?
--------------------------------
Please root to the ``code/`` directory and run the python script as the general form of below:
.. code:: shell
python [python_code_file.py]
As an example the code can be executed as follows:
.. code:: shell
python linear_regression.py --num_epochs=50
The ``--num_epochs`` flag is to provide the number of epochs that will be used for training. The ``--num_epochs`` flag is not required because its default value is ``50`` and is provided in the source code as follows:
.. code:: python
tf.app.flags.DEFINE_integer(
'num_epochs', 50, 'The number of epochs for training the model. Default=50')
----------------------------
How to run the code in IDEs?
----------------------------
Since the code is ready-to-go, as long as the TensorFlow can be called in the IDE editor(Pycharm, Spyder,..), the code can be executed successfully.
This document is dedicated to explain how to run the python script for this tutorial. For this tutorial, we will create a linear SVM for separation of the data. The data that is used for this code is linearly separable.
-------------------
Python Environment
-------------------
``WARNING:`` If TensorFlow is installed in any environment(virtual environment, ...), it must be activated at first. So at first make sure the tensorFlow is available in the current environment using the following script:
--------------------------------
How to run the code in Terminal?
--------------------------------
Please root to the ``code/`` directory and run the python script as the general form of below:
.. code:: shell
python [python_code_file.py]
As an example the code can be executed as follows:
.. code:: shell
python linear_svm.py
----------------------------
How to run the code in IDEs?
----------------------------
Since the code is ready-to-go, as long as the TensorFlow can be called in the IDE editor(Pycharm, Spyder,..), the code can be executed successfully.
This document is dedicated to explaining how to run the python script for this tutorial. ``Logistic regression`` is a binary
classification algorithm in which `yes` or `no` are the only possible responses. The linear output is transformed to a probability of course between zero and 1. The decision is made by thresholding the probability and saying it belongs to which class. We consider ``Softmax`` with ``cross entropy`` loss for minimizing the loss.
-------------------
Python Environment
-------------------
``WARNING:`` If TensorFlow is installed in any environment(virtual environment, ...), it must be activated at first. So at first make sure the tensorFlow is available in the current environment using the following script:
--------------------------------
How to run the code in Terminal?
--------------------------------
Please root to the ``code/`` directory and run the python script as the general form of below:
.. code:: shell
python [python_code_file.py]
As an example the code can be executed as follows:
This document is dedicated to explain how to run the python script for this tutorial. For this tutorial, we will create a Kernel SVM for separation of the data. The data that is used for this code is MNIST dataset. This document is inspired on `Implementing Multiclass SVMs <Multiclasssvm_>`_ open source code. However, in ours, we extend it to MNIST dataset and modify its method.
``WARNING:`` If TensorFlow is installed in any environment(virtual environment, ...), it must be activated at first. So at first make sure the tensorFlow is available in the current environment using the following script:
--------------------------------
How to run the code in Terminal?
--------------------------------
Please root to the ``code/`` directory and run the python script as the general form of below:
.. code:: shell
python [python_code_file.py]
As an example the code can be executed as follows:
.. code:: shell
python multiclass_SVM.py
----------------------------
How to run the code in IDEs?
----------------------------
Since the code is ready-to-go, as long as the TensorFlow can be called in the IDE editor(Pycharm, Spyder,..), the code can be executed successfully.
{kind=link}