README update
Showing
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
codes/python/0-welcome/README.rst
0 → 100644
文件已移动
文件已移动
codes/python/1-basics/readme.rst
0 → 100644
文件已移动
文件已移动
{kind=link}
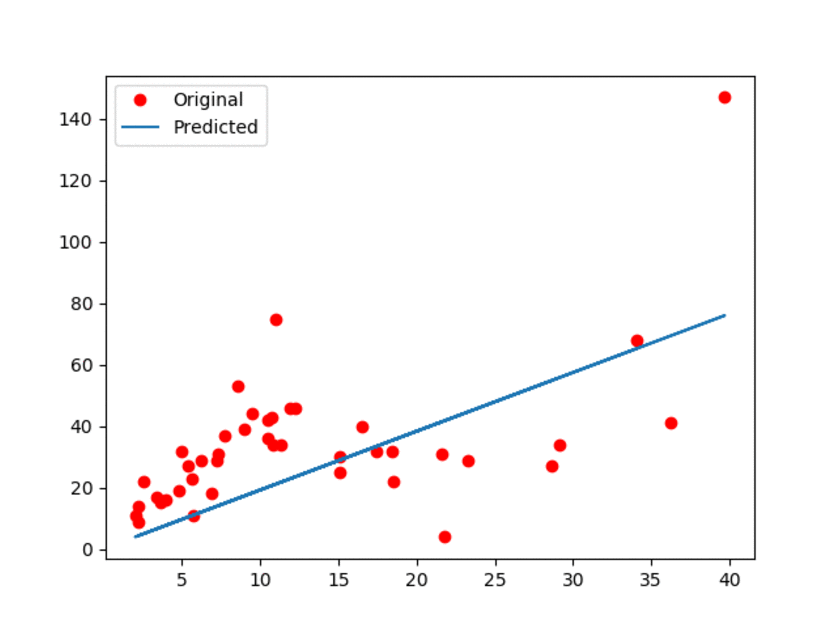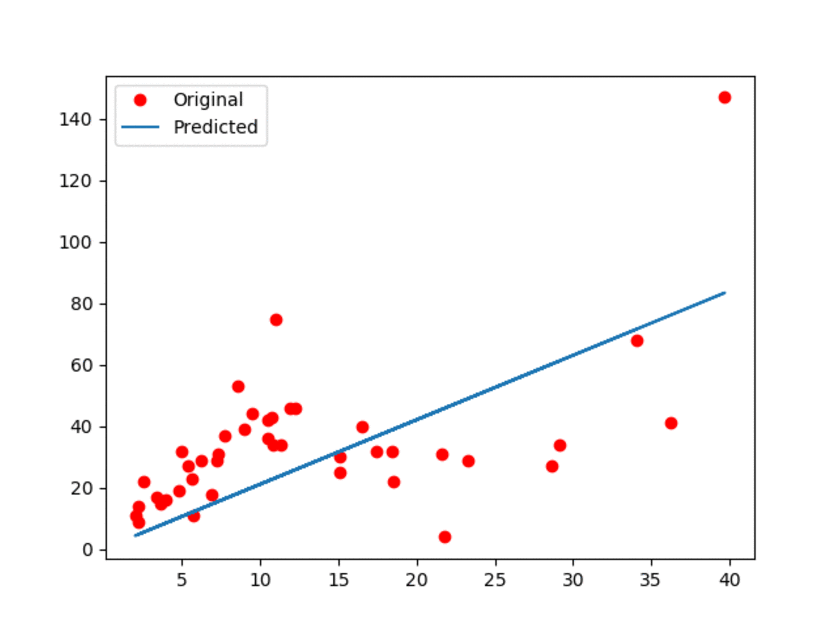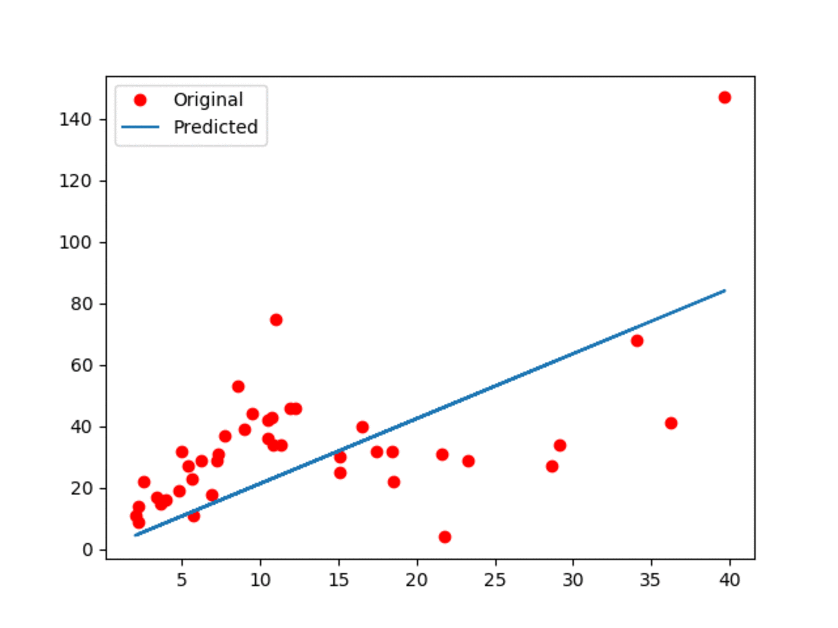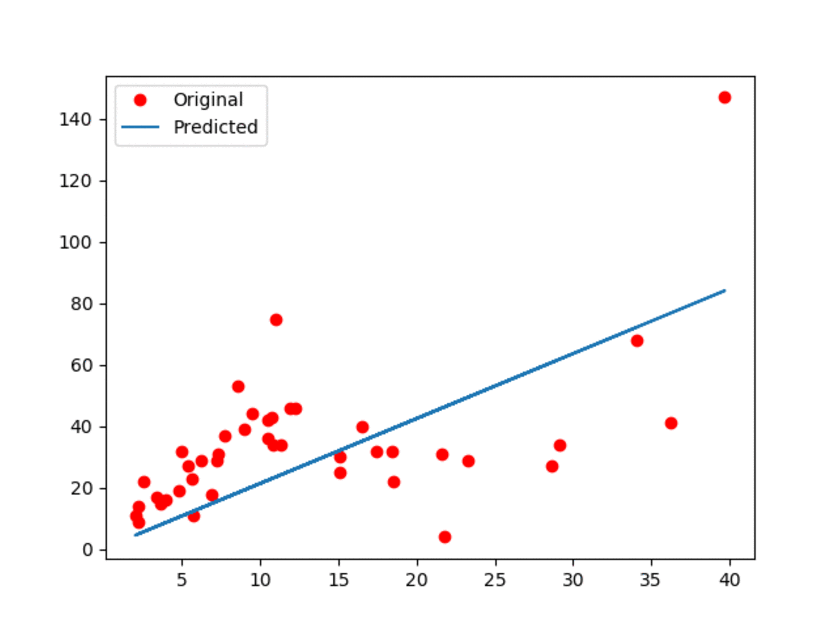
91.0 KB
文件已移动
文件已移动
文件已移动
文件已添加
文件已添加
文件已添加