Integrate doc en/cn into single doc
Showing
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/api/index_cn.rst
0 → 100644
文件已移动
doc/getstarted/index_cn.rst
0 → 100644
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
doc/howto/deep_model/index_cn.rst
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/howto/index_cn.rst
0 → 100644
doc/index_cn.rst
0 → 100644
{kind=link}

455.6 KB
{kind=link}
51.4 KB
{kind=link}
48.7 KB
{kind=link}
30.3 KB
doc/tutorials/index_cn.md
0 → 100644
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
30.5 KB
{kind=link}
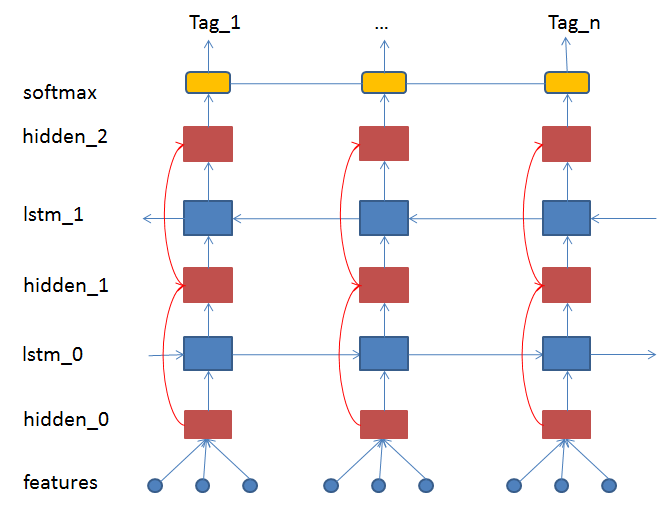
27.2 KB
此差异已折叠。
{kind=link}
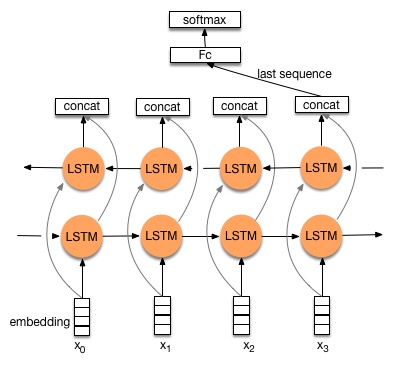
34.8 KB
{kind=link}
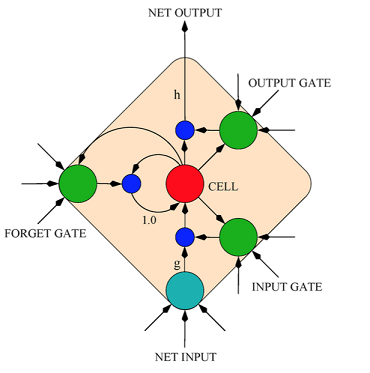
49.5 KB
{kind=link}
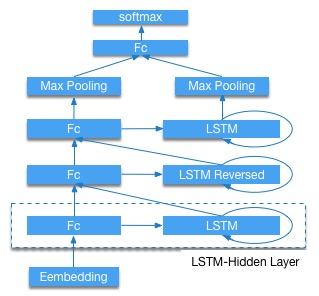
30.3 KB
doc_cn/CMakeLists.txt
已删除
100644 → 0
doc_cn/cluster/index.rst
已删除
100644 → 0
此差异已折叠。
doc_cn/demo/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/index.rst
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/ui/cmd/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc_cn/ui/index.rst
已删除
100644 → 0
此差异已折叠。