Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
honey05917
Python-100-Days
提交
e86dece2
P
Python-100-Days
项目概览
honey05917
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
e86dece2
编写于
5月 28, 2018
作者:
骆昊的技术专栏
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了爬虫第1天的代码和文档
上级
a97f4ac4
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
189 addition
and
49 deletion
+189
-49
Day66-75/01.网络爬虫和相关工具.md
Day66-75/01.网络爬虫和相关工具.md
+129
-4
Day66-75/code/example01.py
Day66-75/code/example01.py
+60
-45
Day66-75/res/crawler-workflow.png
Day66-75/res/crawler-workflow.png
+0
-0
未找到文件。
Day66-75/01.网络爬虫和相关工具.md
浏览文件 @
e86dece2
...
...
@@ -173,10 +173,135 @@ HTTP响应(响应行+响应头+空行+消息体):
### 一个简单的爬虫
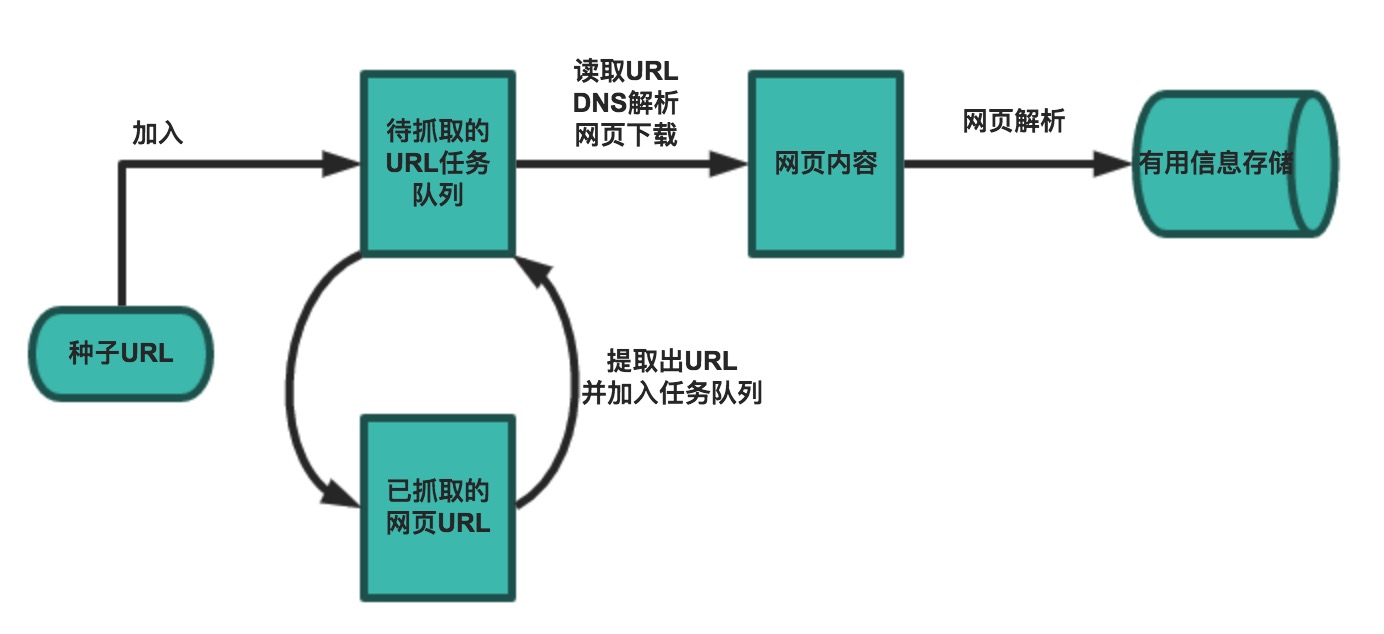
构造一个爬虫一般分为数据采集、数据处理和数据存储三个部分的内容。
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分的内容,当然更为高级的爬虫在数据采集和处理时会使用并发编程或分布式技术,其中可能还包括调度器和后台管理程序(监控爬虫的工作状态以及检查数据抓取的结果)。

1.
设定抓取目标(种子页面)并获取网页。
2.
当服务器无法访问时,设置重试次数。
3.
在需要的时候设置用户代理(否则无法访问页面)。
4.
对获取的页面进行必要的解码操作。
5.
通过正则表达式获取页面中的链接。
6.
对链接进行进一步的处理(获取页面并重复上面的动作)。
7.
将有用的信息进行持久化(以备后续的处理)。
```
Python
from urllib.error import URLError
from urllib.request import urlopen
import re
import pymysql
import ssl
from pymysql import Error
# 通过指定的字符集对页面进行解码(不是每个网站都将字符集设置为utf-8)
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
# logging.error('Decode:', error)
return page_html
# 获取页面的HTML代码(通过递归实现指定次数的重试操作)
def get_page_html(seed_url, *, retry_times=3, charsets=('utf-8',)):
page_html = None
try:
page_html = decode_page(urlopen(seed_url).read(), charsets)
except URLError:
# logging.error('URL:', error)
if retry_times > 0:
return get_page_html(seed_url, retry_times=retry_times - 1,
charsets=charsets)
return page_html
# 从页面中提取需要的部分(通常是链接也可以通过正则表达式进行指定)
def get_matched_parts(page_html, pattern_str, pattern_ignore_case=re.I):
pattern_regex = re.compile(pattern_str, pattern_ignore_case)
return pattern_regex.findall(page_html) if page_html else []
# 开始执行爬虫程序并对指定的数据进行持久化操作
def start_crawl(seed_url, match_pattern, *, max_depth=-1):
conn = pymysql.connect(host='localhost', port=3306,
database='crawler', user='root',
password='123456', charset='utf8')
try:
with conn.cursor() as cursor:
url_list = [seed_url]
# 通过下面的字典避免重复抓取并控制抓取深度
visited_url_list = {seed_url: 0}
while url_list:
current_url = url_list.pop(0)
depth = visited_url_list[current_url]
if depth != max_depth:
page_html = get_page_html(current_url, charsets=('utf-8', 'gbk', 'gb2312'))
links_list = get_matched_parts(page_html, match_pattern)
param_list = []
for link in links_list:
if link not in visited_url_list:
visited_url_list[link] = depth + 1
page_html = get_page_html(link, charsets=('utf-8', 'gbk', 'gb2312'))
headings = get_matched_parts(page_html, r'<h1>(.*)<span')
if headings:
param_list.append((headings[0], link))
cursor.executemany('insert into tb_result values (default, %s, %s)',
param_list)
conn.commit()
except Error:
pass
# logging.error('SQL:', error)
finally:
conn.close()
def main():
ssl._create_default_https_context = ssl._create_unverified_context
start_crawl('http://sports.sohu.com/nba_a.shtml',
r'<a[^>]+test=a\s[^>]*href=["\'](.*?)["\']',
max_depth=2)
if __name__ == '__main__':
main()
首先我们要设定抓取的目标并获取网页。
```
注意事项:
1.
处理相对链接。有的时候我们从页面中获取的链接不是一个完整的绝对链接而是一个相对链接,这种情况下需要将其与URL前缀进行拼接(urllib.parse中的urljoin函数可以完成此项操作)。
2.
设置代理服务。有些网站会限制访问的区域(例如美国的Netflix屏蔽了很多国家的访问),有些爬虫需要隐藏自己的身份,在这种情况下可以设置代理服务器(urllib.request中的ProxyHandler就是用来进行此项操作)。
3.
限制下载速度。如果我们的爬虫获取网页的速度过快,可能就会面临被封禁或者产生“损害动产”的风险(这个可能会导致吃官司且败诉哦),可以在两次下载之间添加延时从而对爬虫进行限速。
4.
避免爬虫陷阱。有些网站会动态生成页面内容,这会导致产生无限多的页面(例如在线万年历等)。可以通过记录到达当前页面经过了多少个链接(链接深度)来解决该问题,当达到事先设定的最大深度时爬虫就不再像队列中添加该网页中的链接了。
5.
SSL相关问题。在使用
`urlopen`
打开一个HTTPS链接时会验证一次SSL证书,如果不做出处理会产生错误提示“SSL: CERTIFICATE_VERIFY_FAILED”,可以通过以下两种方式加以解决:
-
使用未经验证的上下文
```Python
import ssl
request = urllib.request.Request(url='...', headers={...})
context = ssl._create_unverified_context()
web_page = urllib.request.urlopen(request, context=context)
```
-
设置全局的取消证书验证
1.
设置重试次数。
2.
设置用户代理。
```Python
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
```
Day66-75/code/example01.py
浏览文件 @
e86dece2
...
...
@@ -3,58 +3,73 @@ from urllib.request import urlopen
import
re
import
pymysql
import
ssl
from
pymysql
import
Error
def
get_page_code
(
start_url
,
*
,
retry_times
=
3
,
charsets
=
(
'utf-8'
,
)):
def
decode_page
(
page_bytes
,
charsets
=
(
'utf-8'
,
)):
page_html
=
None
for
charset
in
charsets
:
try
:
page_html
=
page_bytes
.
decode
(
charset
)
break
except
UnicodeDecodeError
:
pass
# logging.error('Decode:', error)
return
page_html
def
get_page_html
(
seed_url
,
*
,
retry_times
=
3
,
charsets
=
(
'utf-8'
,
)):
page_html
=
None
try
:
for
charset
in
charsets
:
try
:
html
=
urlopen
(
start_url
).
read
().
decode
(
charset
)
break
except
UnicodeDecodeError
:
html
=
None
except
URLError
as
ex
:
print
(
'Error:'
,
ex
)
return
get_page_code
(
start_url
,
retry_times
=
retry_times
-
1
,
charsets
=
charsets
)
if
\
retry_times
>
0
else
None
return
html
page_html
=
decode_page
(
urlopen
(
seed_url
).
read
(),
charsets
)
except
URLError
:
# logging.error('URL:', error)
if
retry_times
>
0
:
return
get_page_html
(
seed_url
,
retry_times
=
retry_times
-
1
,
charsets
=
charsets
)
return
page_html
def
get_matched_parts
(
page_html
,
pattern_str
,
pattern_ignore_case
=
re
.
I
):
pattern_regex
=
re
.
compile
(
pattern_str
,
pattern_ignore_case
)
return
pattern_regex
.
findall
(
page_html
)
if
page_html
else
[]
def
start_crawl
(
seed_url
,
match_pattern
):
conn
=
pymysql
.
connect
(
host
=
'localhost'
,
port
=
3306
,
database
=
'crawler'
,
user
=
'root'
,
password
=
'123456'
,
charset
=
'utf8'
)
try
:
with
conn
.
cursor
()
as
cursor
:
url_list
=
[
seed_url
]
while
url_list
:
current_url
=
url_list
.
pop
(
0
)
page_html
=
get_page_html
(
current_url
,
charsets
=
(
'utf-8'
,
'gbk'
,
'gb2312'
))
links_list
=
get_matched_parts
(
page_html
,
match_pattern
)
url_list
+=
links_list
param_list
=
[]
for
link
in
links_list
:
page_html
=
get_page_html
(
link
,
charsets
=
(
'utf-8'
,
'gbk'
,
'gb2312'
))
headings
=
get_matched_parts
(
page_html
,
r
'<h1>(.*)<span'
)
if
headings
:
param_list
.
append
((
headings
[
0
],
link
))
cursor
.
executemany
(
'insert into tb_result values (default, %s, %s)'
,
param_list
)
conn
.
commit
()
except
Error
:
pass
# logging.error('SQL:', error)
finally
:
conn
.
close
()
def
main
():
url_list
=
[
'http://sports.sohu.com/nba_a.shtml'
]
visited_list
=
set
({})
while
len
(
url_list
)
>
0
:
current_url
=
url_list
.
pop
(
0
)
visited_list
.
add
(
current_url
)
print
(
current_url
)
html
=
get_page_code
(
current_url
,
charsets
=
(
'utf-8'
,
'gbk'
,
'gb2312'
))
if
html
:
link_regex
=
re
.
compile
(
r
'<a[^>]+href=["\'](.*?)["\']'
,
re
.
IGNORECASE
)
link_list
=
re
.
findall
(
link_regex
,
html
)
url_list
+=
link_list
conn
=
pymysql
.
connect
(
host
=
'localhost'
,
port
=
3306
,
db
=
'crawler'
,
user
=
'root'
,
passwd
=
'123456'
,
charset
=
'utf8'
)
try
:
for
link
in
link_list
:
if
link
not
in
visited_list
:
visited_list
.
add
(
link
)
print
(
link
)
html
=
get_page_code
(
link
,
charsets
=
(
'utf-8'
,
'gbk'
,
'gb2312'
))
if
html
:
title_regex
=
re
.
compile
(
r
'<h1>(.*)<span'
,
re
.
IGNORECASE
)
match_list
=
title_regex
.
findall
(
html
)
if
len
(
match_list
)
>
0
:
title
=
match_list
[
0
]
with
conn
.
cursor
()
as
cursor
:
cursor
.
execute
(
'insert into tb_result (rtitle, rurl) values (%s, %s)'
,
(
title
,
link
))
conn
.
commit
()
finally
:
conn
.
close
()
print
(
'执行完成!'
)
ssl
.
_create_default_https_context
=
ssl
.
_create_unverified_context
start_crawl
(
'http://sports.sohu.com/nba_a.shtml'
,
r
'<a[^>]+test=a\s[^>]*href=["\'](.*?)["\']'
)
if
__name__
==
'__main__'
:
main
()
Day66-75/res/crawler-workflow.png
0 → 100644
浏览文件 @
e86dece2
74.1 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}