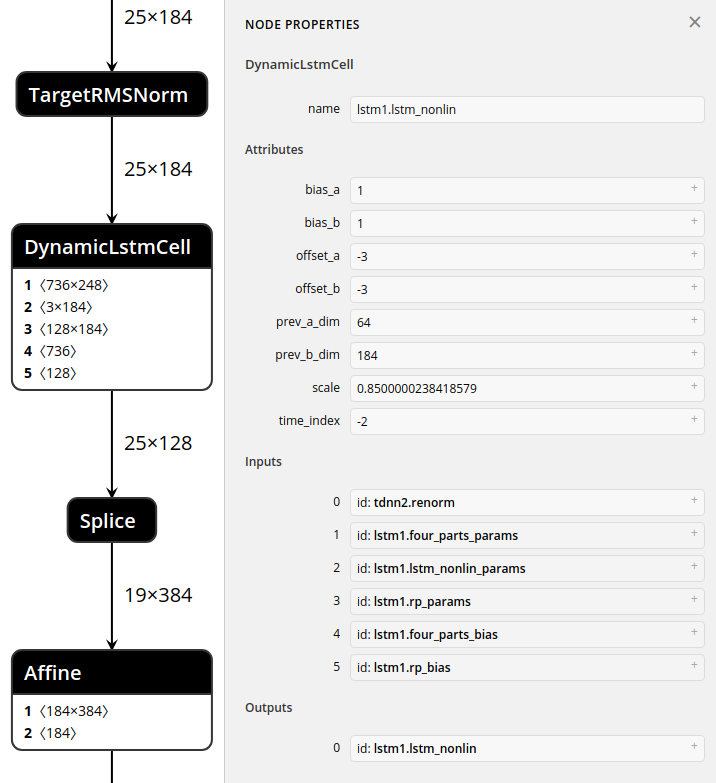
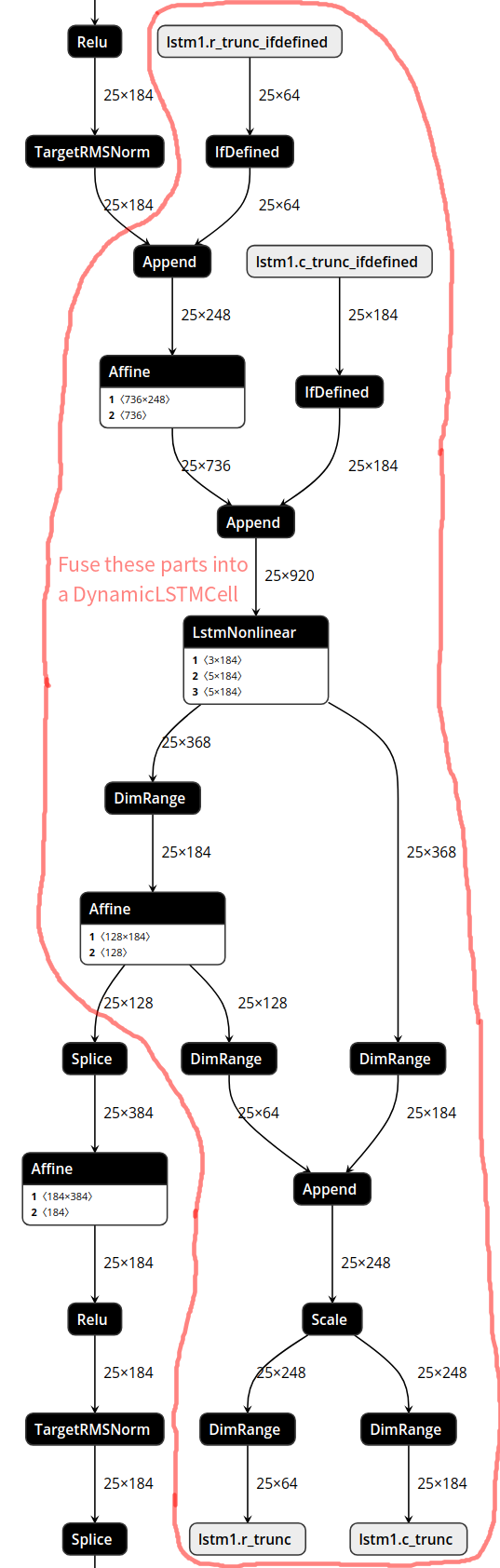
add dynamic lstm cell
support kaldi tdnn-lstm support logsoftmax add ifdefined op add dynamic lstm docs
Showing
docs/development/dynamic_lstm.md
0 → 100644
{kind=link}
60.0 KB
{kind=link}
112.6 KB
mace/ops/common/lstm.cc
0 → 100644
mace/ops/common/lstm.h
0 → 100644
mace/ops/dynamic_lstm.cc
0 → 100644
mace/ops/lstm_nonlinear.cc
0 → 100644
mace/ops/pad_context_benchmark.cc
0 → 100644
mace/ops/slice_benchmark.cc
0 → 100644