Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
haomaomaohu
Python-100-Days
提交
9385d438
P
Python-100-Days
项目概览
haomaomaohu
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
9385d438
编写于
6月 03, 2018
作者:
骆昊的技术专栏
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了部分代码
上级
8e861a8a
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
221 addition
and
4 deletion
+221
-4
Day66-75/04.并发下载.md
Day66-75/04.并发下载.md
+143
-0
Day66-75/07.数据清洗.md
Day66-75/07.数据清洗.md
+0
-2
Day66-75/Scrapy的应用01.md
Day66-75/Scrapy的应用01.md
+76
-0
Day66-75/code/main.py
Day66-75/code/main.py
+1
-1
Day66-75/code/main_redis.py
Day66-75/code/main_redis.py
+1
-1
Day66-75/res/scrapy-architecture.jpg
Day66-75/res/scrapy-architecture.jpg
+0
-0
未找到文件。
Day66-75/04.并发下载.md
浏览文件 @
9385d438
## 并发下载
### 多线程和多进程回顾
### 实例 - 多线程下载“手机搜狐网”所有页面。
```
Python
from enum import Enum, unique
from queue import Queue
from random import random
from threading import Thread, current_thread
from time import sleep
from urllib.parse import urlparse
import requests
from bs4 import BeautifulSoup
@unique
class SpiderStatus(Enum):
IDLE = 0
WORKING = 1
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
return page_html
class Retry(object):
def __init__(self, *, retry_times=3,
wait_secs=5, errors=(Exception, )):
self.retry_times = retry_times
self.wait_secs = wait_secs
self.errors = errors
def __call__(self, fn):
def wrapper(*args, **kwargs):
for _ in range(self.retry_times):
try:
return fn(*args, **kwargs)
except self.errors as e:
print(e)
sleep((random() + 1) * self.wait_secs)
return None
return wrapper
class Spider(object):
def __init__(self):
self.status = SpiderStatus.IDLE
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ),
user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
def parse(self, html_page, *, domain='m.sohu.com'):
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
for a_tag in soup.body.select('a[href]'):
parser = urlparse(a_tag.attrs['href'])
scheme = parser.scheme or 'http'
netloc = parser.netloc or domain
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
url_links.append(full_url)
return url_links
def extract(self, html_page):
pass
def store(self, data_dict):
pass
class SpiderThread(Thread):
def __init__(self, name, spider, tasks_queue):
super().__init__(name=name, daemon=True)
self.spider = spider
self.tasks_queue = tasks_queue
def run(self):
while True:
current_url = self.tasks_queue.get()
visited_urls.add(current_url)
self.spider.status = SpiderStatus.WORKING
html_page = self.spider.fetch(current_url)
if html_page not in [None, '']:
url_links = self.spider.parse(html_page)
for url_link in url_links:
self.tasks_queue.put(url_link)
self.spider.status = SpiderStatus.IDLE
def is_any_alive(spider_threads):
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
visited_urls = set()
def main():
task_queue = Queue()
task_queue.put('http://m.sohu.com/')
spider_threads = [SpiderThread('thread-%d' % i, Spider(), task_queue)
for i in range(10)]
for spider_thread in spider_threads:
spider_thread.start()
while not task_queue.empty() or is_any_alive(spider_threads):
sleep(5)
print('Over!')
if __name__ == '__main__':
main()
```
Day66-75/07.数据清洗.md
已删除
100644 → 0
浏览文件 @
8e861a8a
## 数据清洗
Day66-75/Scrapy的应用01.md
浏览文件 @
9385d438
## Scrapy的应用(01)
### Scrapy概述
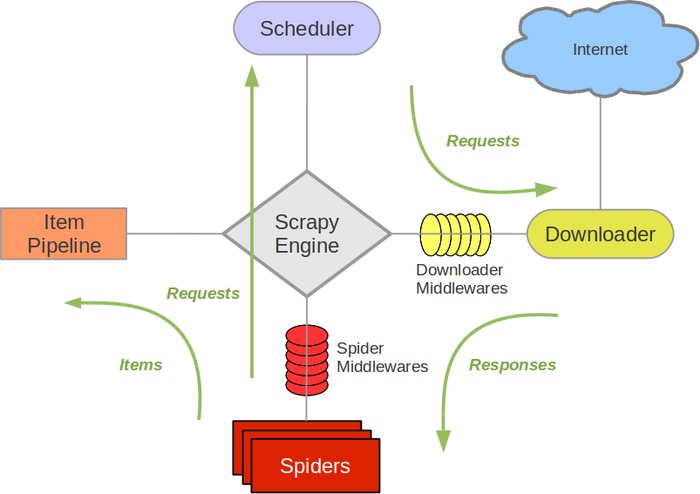
Scrapy是Python开发的一个非常流行的网络爬虫框架,可以用来抓取Web站点并从页面中提取结构化的数据,被广泛的用于数据挖掘、数据监测和自动化测试等领域。下图展示了Scrapy的基本架构,其中包含了主要组件和系统的数据处理流程(图中的绿色箭头)。

#### 组件
1.
Scrapy引擎(Engine):Scrapy引擎是用来控制整个系统的数据处理流程。
2.
调度器(Scheduler):调度器从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给它们。
3.
下载器(Downloader):下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
4.
蜘蛛(Spiders):蜘蛛是有Scrapy用户自定义的用来解析网页并抓取特定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名,简单的说就是用来定义特定网站的抓取和解析规则。
5.
条目管道(Item Pipeline):条目管道的主要责任是负责处理有蜘蛛从网页中抽取的数据条目,它的主要任务是清理、验证和存储数据。当页面被蜘蛛解析后,将被发送到条目管道,并经过几个特定的次序处理数据。每个条目管道组件都是一个Python类,它们获取了数据条目并执行对数据条目进行处理的方法,同时还需要确定是否需要在条目管道中继续执行下一步或是直接丢弃掉不处理。条目管道通常执行的任务有:清理HTML数据、验证解析到的数据(检查条目是否包含必要的字段)、检查是不是重复数据(如果重复就丢弃)、将解析到的数据存储到数据库(关系型数据库或NoSQL数据库)中。
6.
中间件(Middlewares):中间件是介于Scrapy引擎和其他组件之间的一个钩子框架,主要是为了提供自定义的代码来拓展Scrapy的功能,包括下载器中间件和蜘蛛中间件。
#### 数据处理流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,通常的运转流程包括以下的步骤:
1.
引擎询问蜘蛛需要处理哪个网站,并让蜘蛛将第一个需要处理的URL交给它。
2.
引擎让调度器将需要处理的URL放在队列中。
3.
引擎从调度那获取接下来进行爬取的页面。
4.
调度将下一个爬取的URL返回给引擎,引擎将它通过下载中间件发送到下载器。
5.
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎;如果下载失败了,引擎会通知调度器记录这个URL,待会再重新下载。
6.
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
7.
蜘蛛处理响应并返回爬取到的数据条目,此外还要将需要跟进的新的URL发送给引擎。
8.
引擎将抓取到的数据条目送入条目管道,把新的URL发送给调度器放入队列中。
9.
上述操作会一直重复直到调度器中没有需要请求的URL,爬虫停止工作。
### 安装和使用Scrapy
可以先创建虚拟环境并在虚拟环境下使用pip安装scrapy。
```
Shell
$
```
项目的目录结构如下图所示。
```
Shell
(venv) $ tree
.
|____ scrapy.cfg
|____ qianmu
| |____ spiders
| | |____ __init__.py
| | |____ __pycache__
| |____ __init__.py
| |____ __pycache__
| |____ middlewares.py
| |____ settings.py
| |____ items.py
| |____ pipelines.py
```
> 说明:Windows系统的命令行提示符下有tree命令,但是Linux和MacOS的终端是没有tree命令的,可以用下面给出的命令来定义tree命令,其实是对find命令进行了定制并别名为tree。
>
> `alias tree="find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"`
>
> Linux系统也可以通过yum或其他的包管理工具来安装tree。
>
> `yum install tree`
根据刚才描述的数据处理流程,基本上需要我们做的有以下几件事情:
1.
在items.py文件中定义字段,这些字段用来保存数据,方便后续的操作。
2.
在spiders文件夹中编写自己的爬虫。
3.
在pipelines.py中完成对数据进行持久化的操作。
4.
修改settings.py文件对项目进行配置。
Day66-75/code/main.py
浏览文件 @
9385d438
...
...
@@ -123,7 +123,7 @@ def main():
spider_thread
.
start
()
while
not
task_queue
.
empty
()
or
is_any_alive
(
spider_threads
):
pass
sleep
(
5
)
print
(
'Over!'
)
...
...
Day66-75/code/main_redis.py
浏览文件 @
9385d438
...
...
@@ -124,7 +124,7 @@ def is_any_alive(spider_threads):
for
spider_thread
in
spider_threads
])
redis_client
=
redis
.
Redis
(
host
=
'1
20.77.222.217
'
,
redis_client
=
redis
.
Redis
(
host
=
'1
.2.3.4
'
,
port
=
6379
,
password
=
'1qaz2wsx'
)
mongo_client
=
pymongo
.
MongoClient
(
host
=
'120.77.222.217'
,
port
=
27017
)
db
=
mongo_client
.
msohu
...
...
Day66-75/res/scrapy-architecture.jpg
0 → 100644
浏览文件 @
9385d438
54.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}