更新了部分文档和代码
Showing
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
Day41-55/41.Django快速上手.md
0 → 100644
此差异已折叠。
Day41-55/41.快速上手.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
{kind=link}

1.9 KB
{kind=link}
1.4 KB
{kind=link}

124.6 KB
{kind=link}

110.0 KB
{kind=link}

166.0 KB
{kind=link}

106.3 KB
{kind=link}

122.1 KB
{kind=link}

130.8 KB
Day41-55/code/shop/manage.py
已删除
100644 → 0
{kind=link}

46.4 KB
{kind=link}

13.3 KB
{kind=link}

22.8 KB
{kind=link}

32.3 KB
{kind=link}

32.4 KB
{kind=link}

10.2 KB
{kind=link}

46.4 KB
{kind=link}

13.3 KB
{kind=link}

22.8 KB
{kind=link}

32.3 KB
{kind=link}

32.4 KB
{kind=link}

10.2 KB
Day41-55/res/admin-login.png
已删除
100644 → 0
{kind=link}
12.2 KB
{kind=link}
40.9 KB
{kind=link}
44.9 KB
{kind=link}
49.2 KB
{kind=link}
73.1 KB
{kind=link}
63.7 KB
{kind=link}
43.5 KB
Day41-55/res/admin-model.png
已删除
100644 → 0
{kind=link}

42.4 KB
{kind=link}
34.2 KB
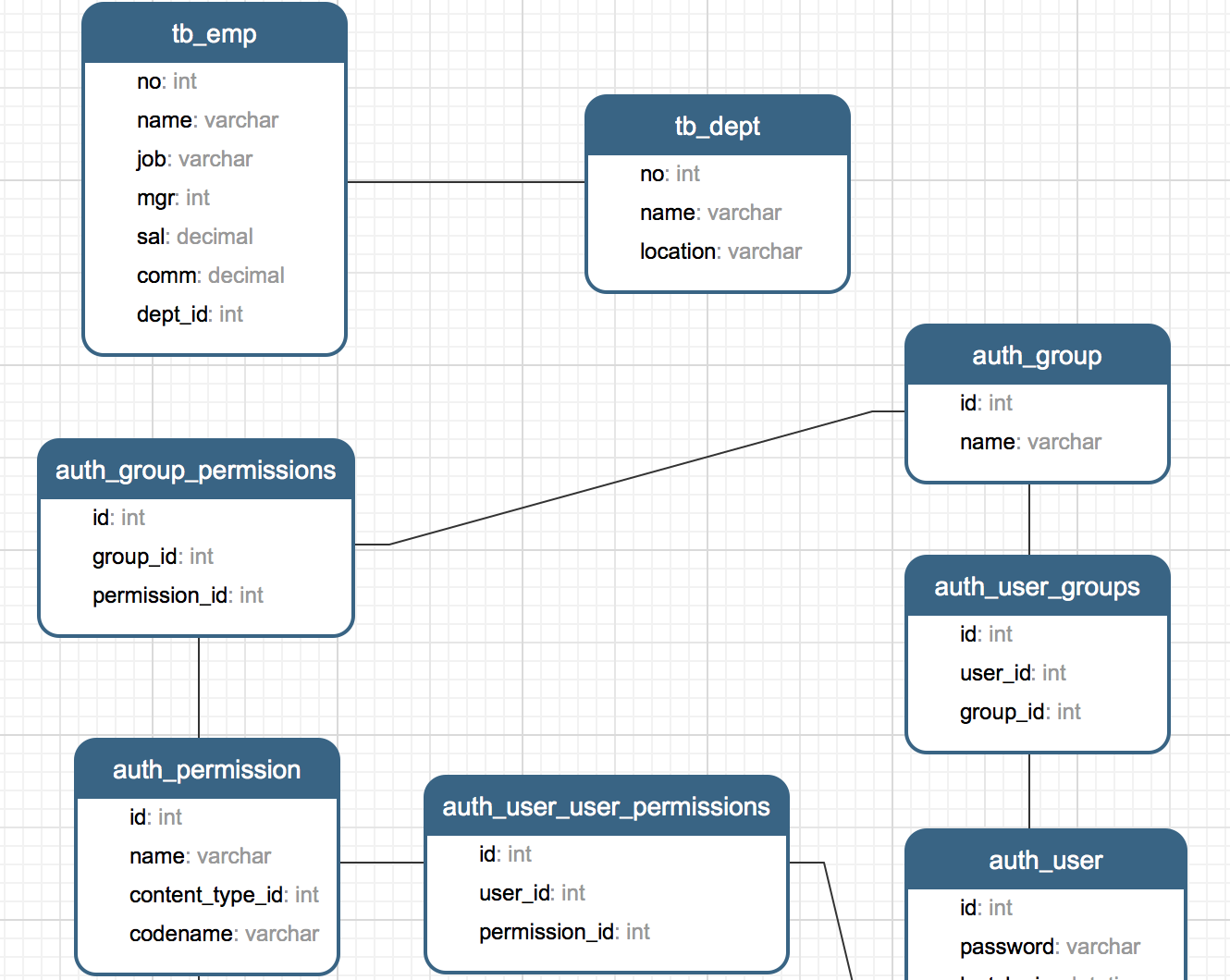
Day41-55/res/er-graph.png
已删除
100644 → 0
{kind=link}
84.9 KB
{kind=link}
163.4 KB
{kind=link}

322.5 KB
{kind=link}
294.1 KB
{kind=link}
463.8 KB
{kind=link}
698.0 KB
{kind=link}

344.3 KB
{kind=link}
243.7 KB
Day41-55/res/show-depts.png
已删除
100644 → 0
{kind=link}

11.0 KB
{kind=link}

124.6 KB
{kind=link}

252.7 KB
Day66-75/75.爬虫项目实战.md
已删除
100644 → 0
{kind=link}
此差异已折叠。