Merge pull request #33 from jrzaurin/tabtransformer
Tabtransformer
Showing
99.7 KB
{kind=link}
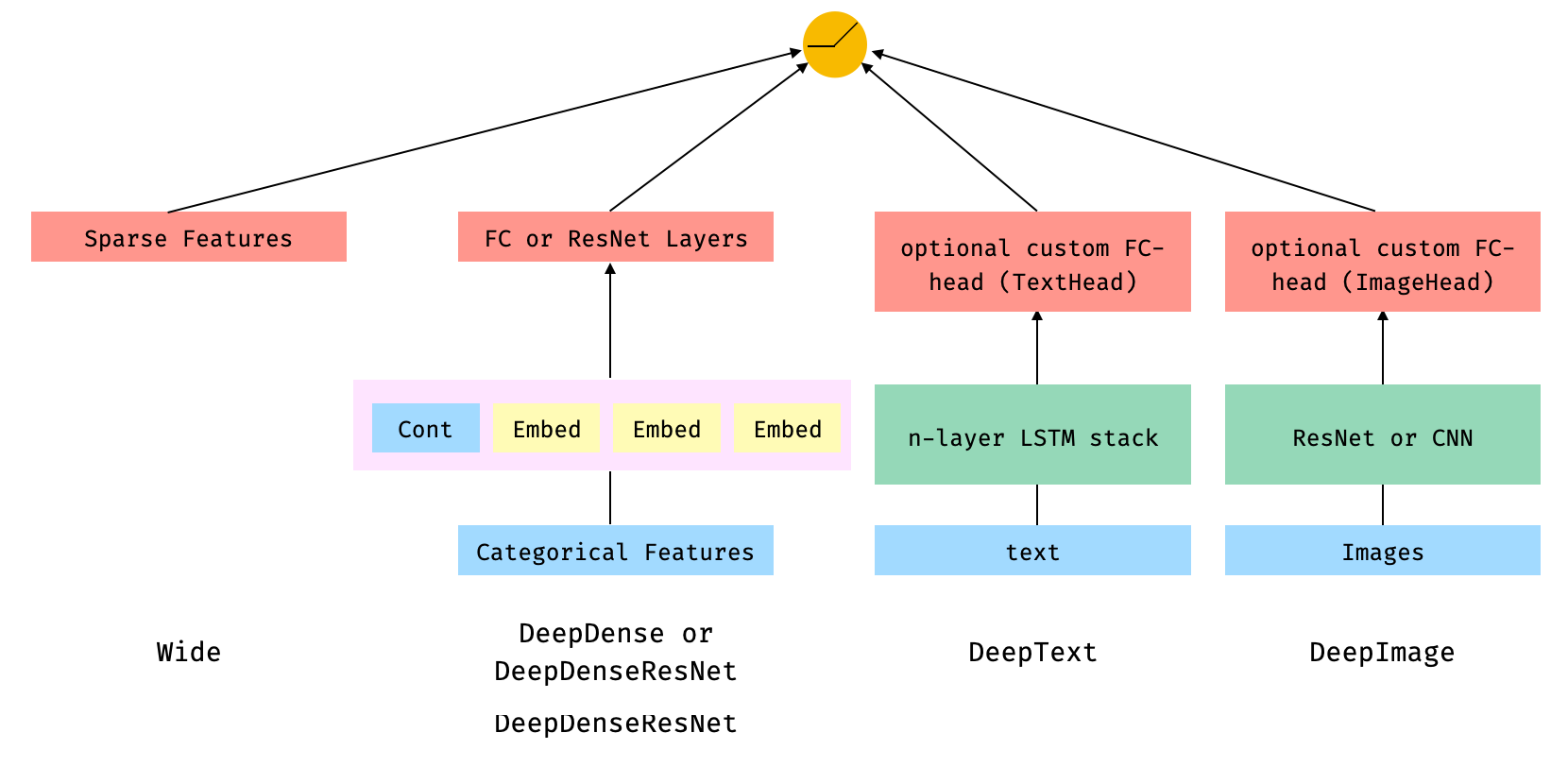
117.8 KB
{kind=link}
{kind=link}
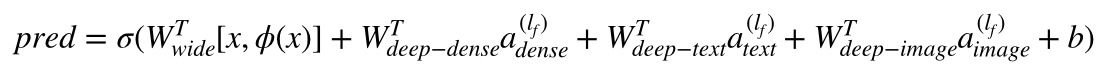
| W: | H:
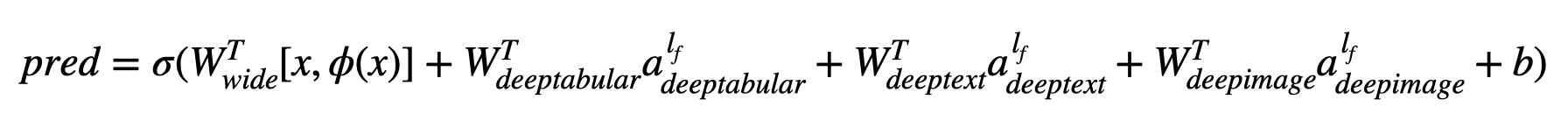
| W: | H:
{kind=link}
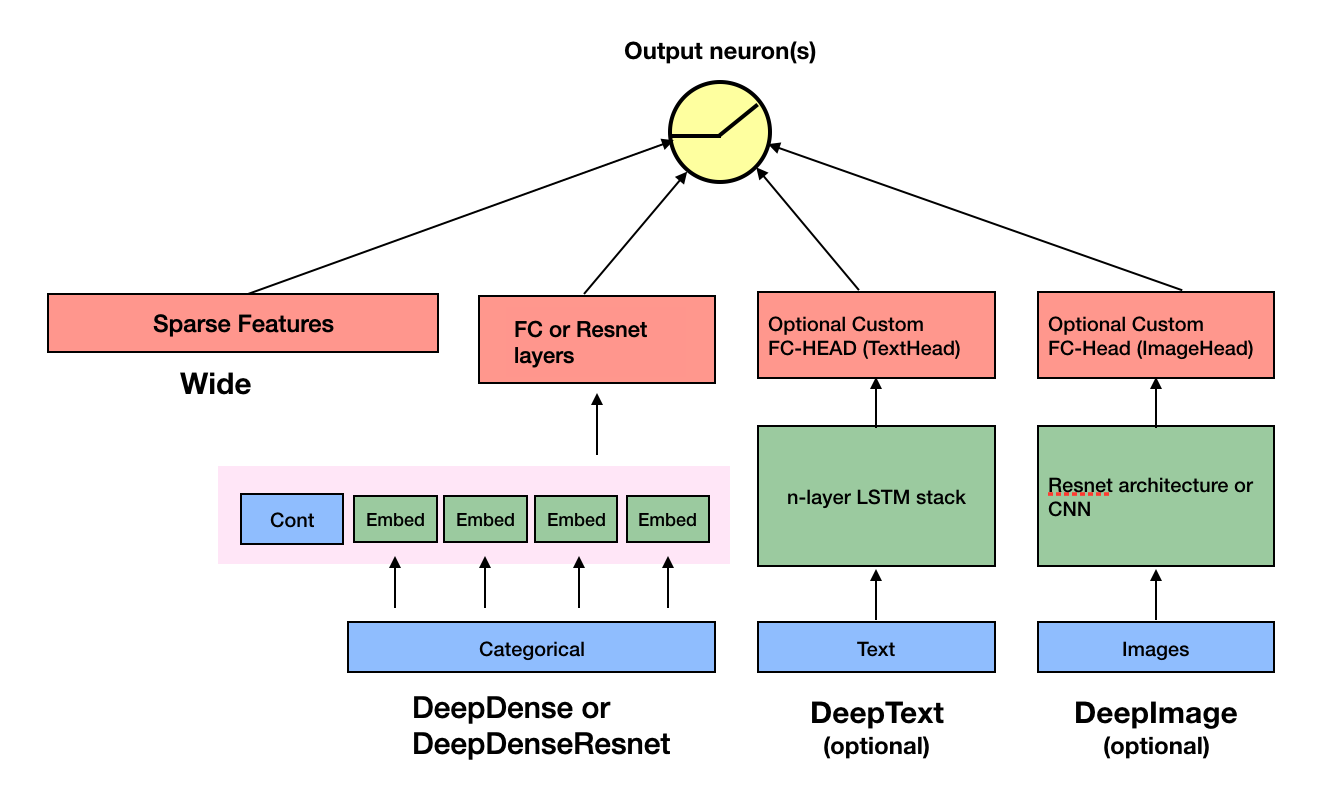
116.7 KB
{kind=link}
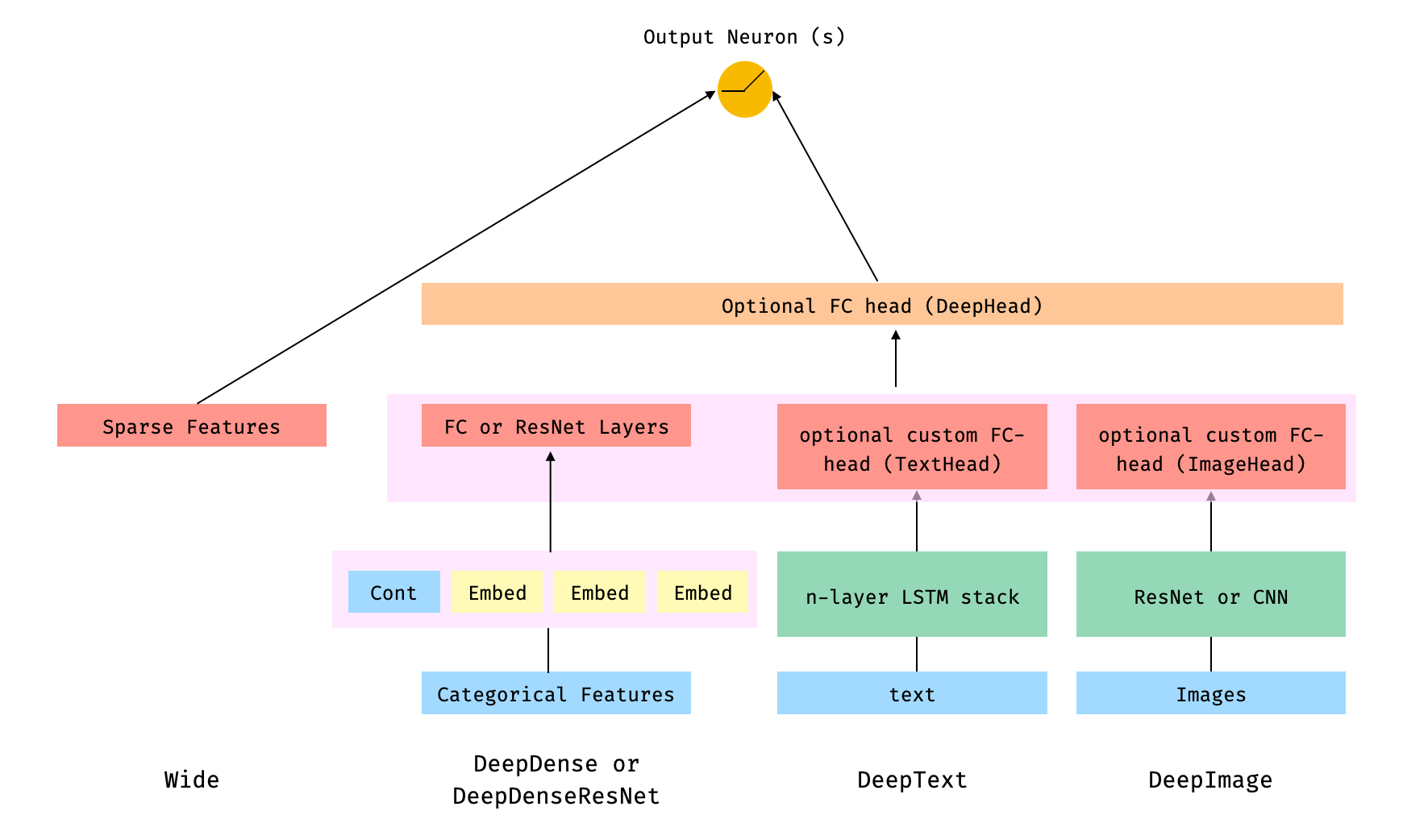
144.8 KB
{kind=link}
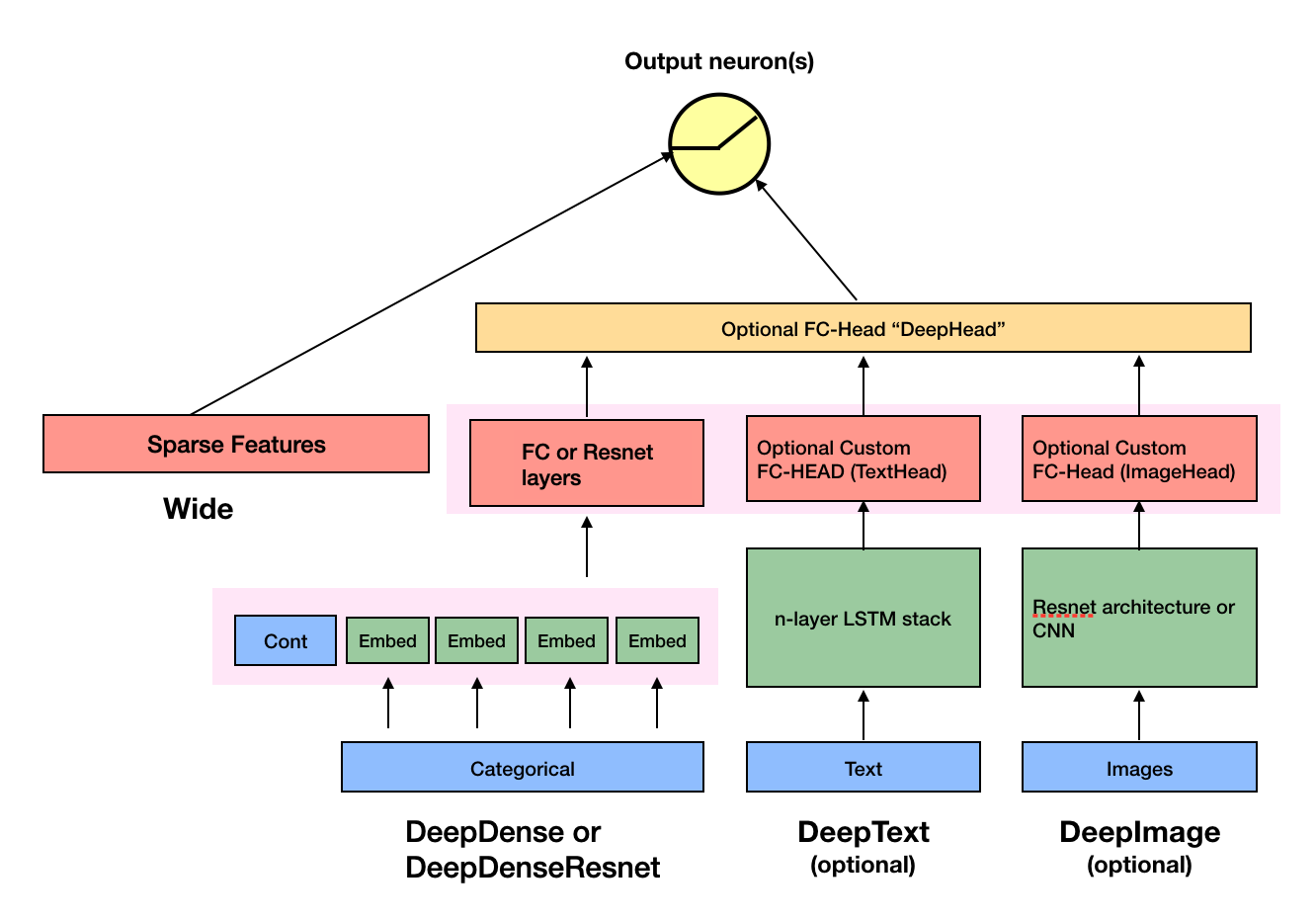
126.4 KB
{kind=link}
{kind=link}
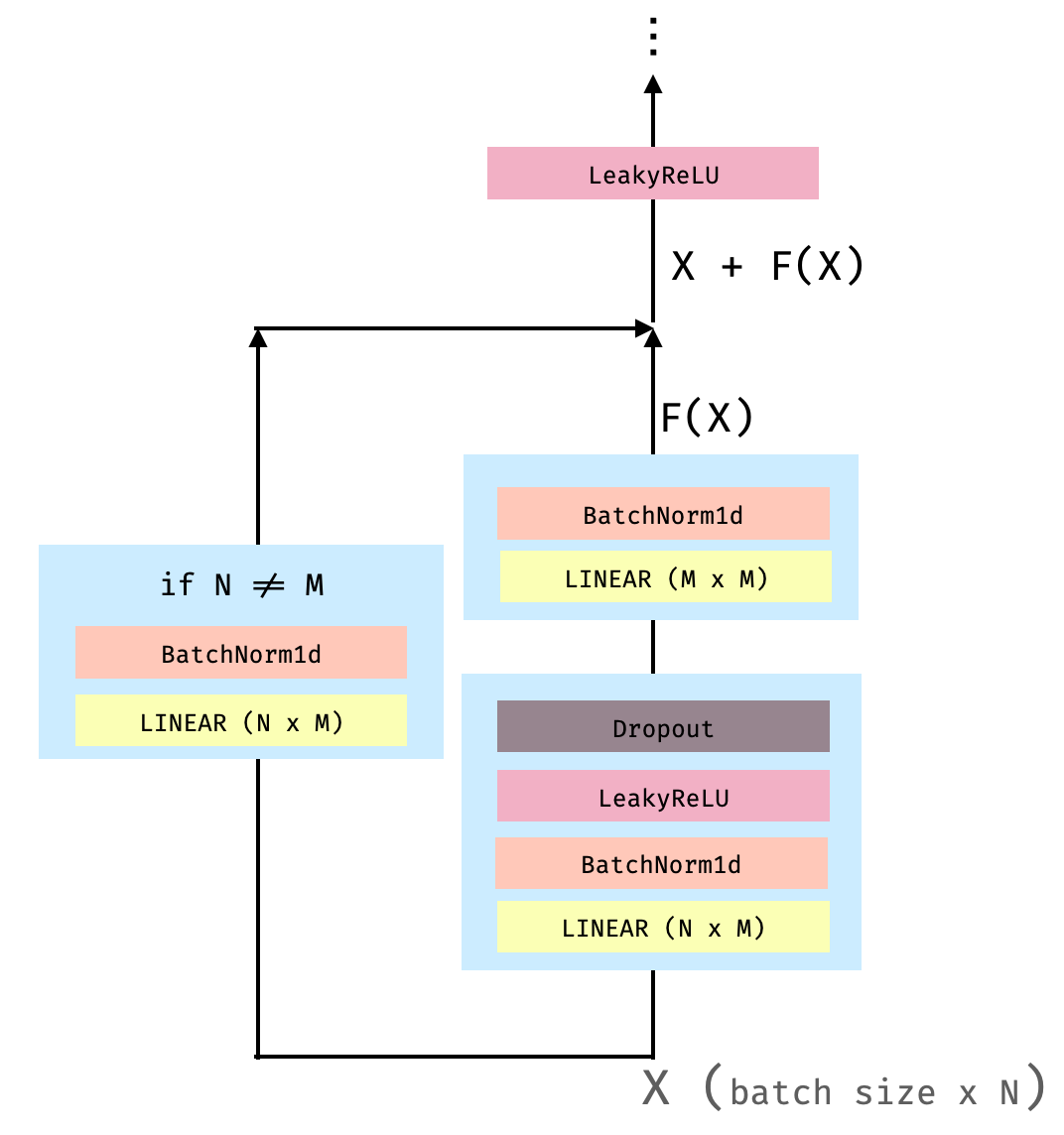
| W: | H:
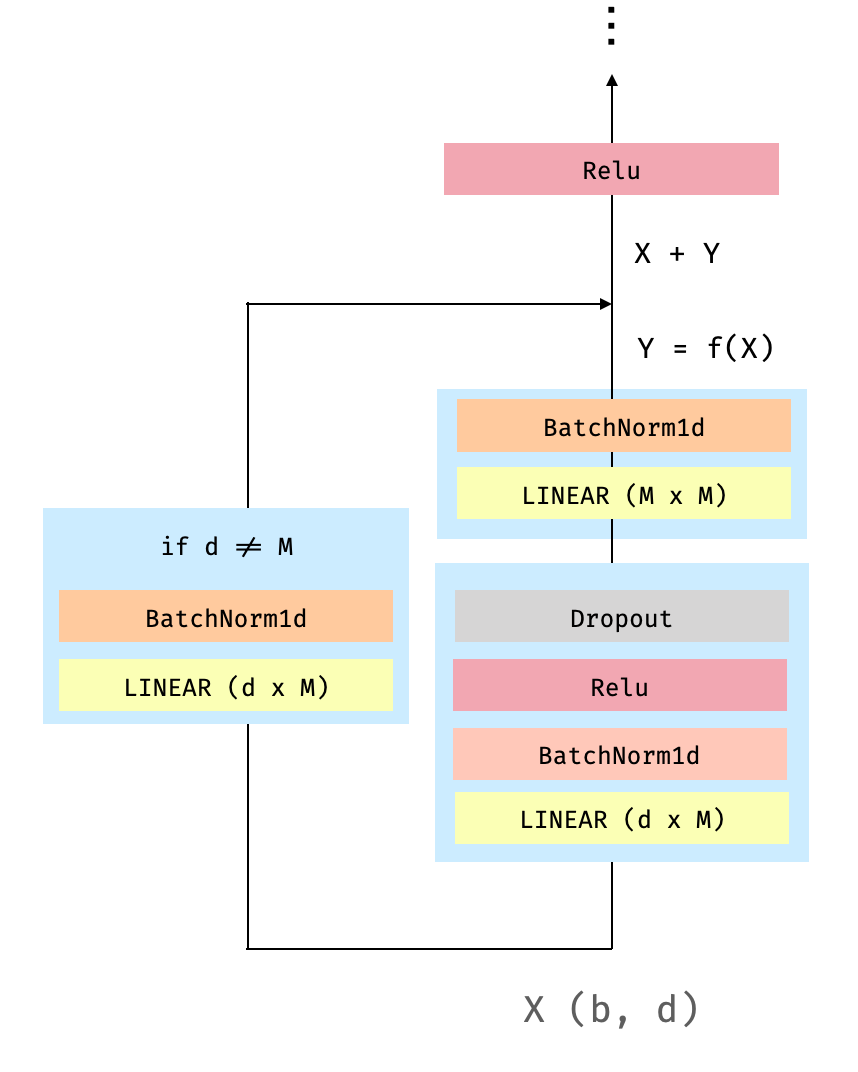
| W: | H:
docs/figures/tabmlp_arch.png
0 → 100644
{kind=link}
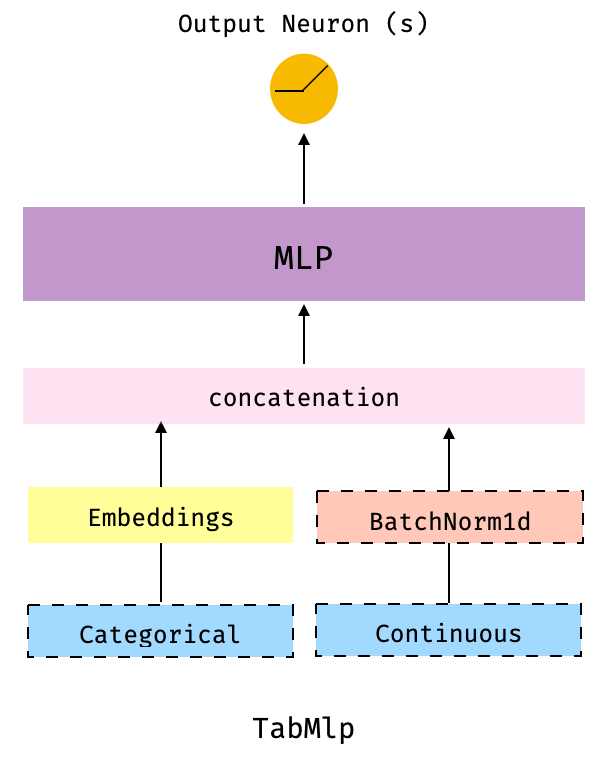
46.0 KB
docs/figures/tabresnet_arch.png
0 → 100644
{kind=link}
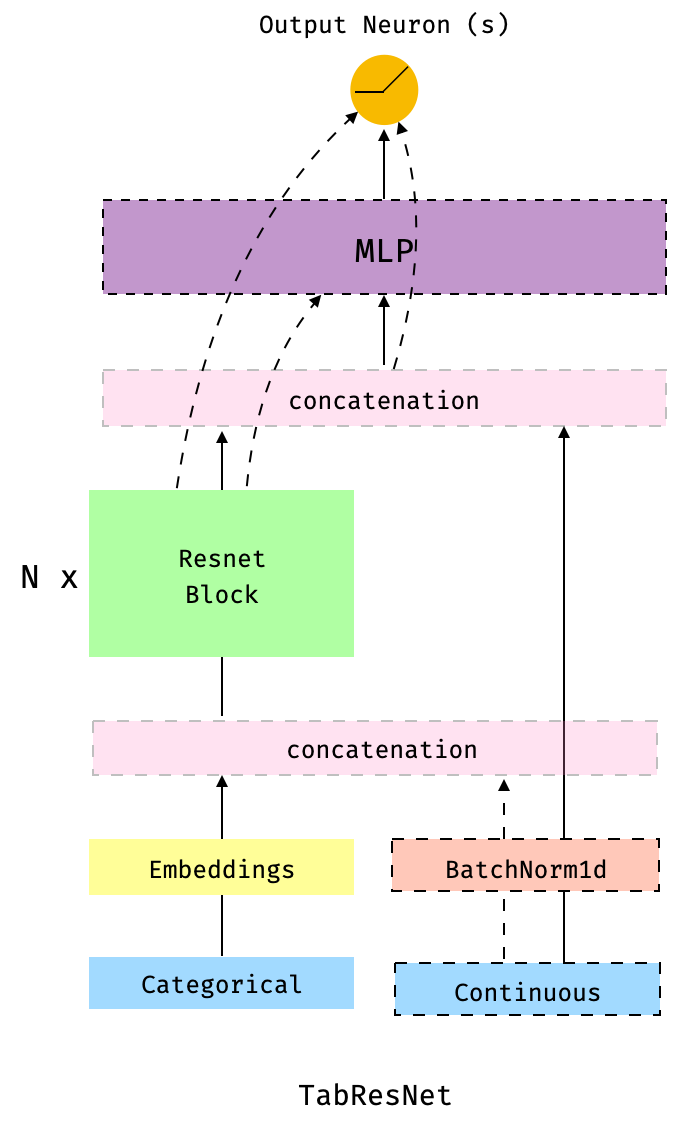
78.6 KB
{kind=link}
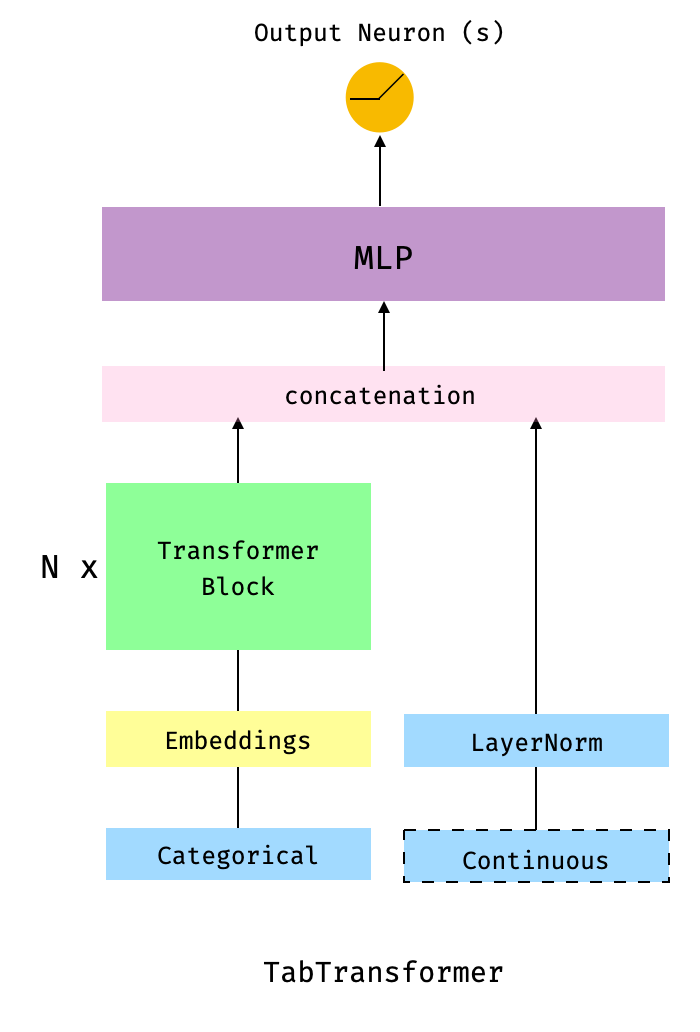
63.1 KB
{kind=link}
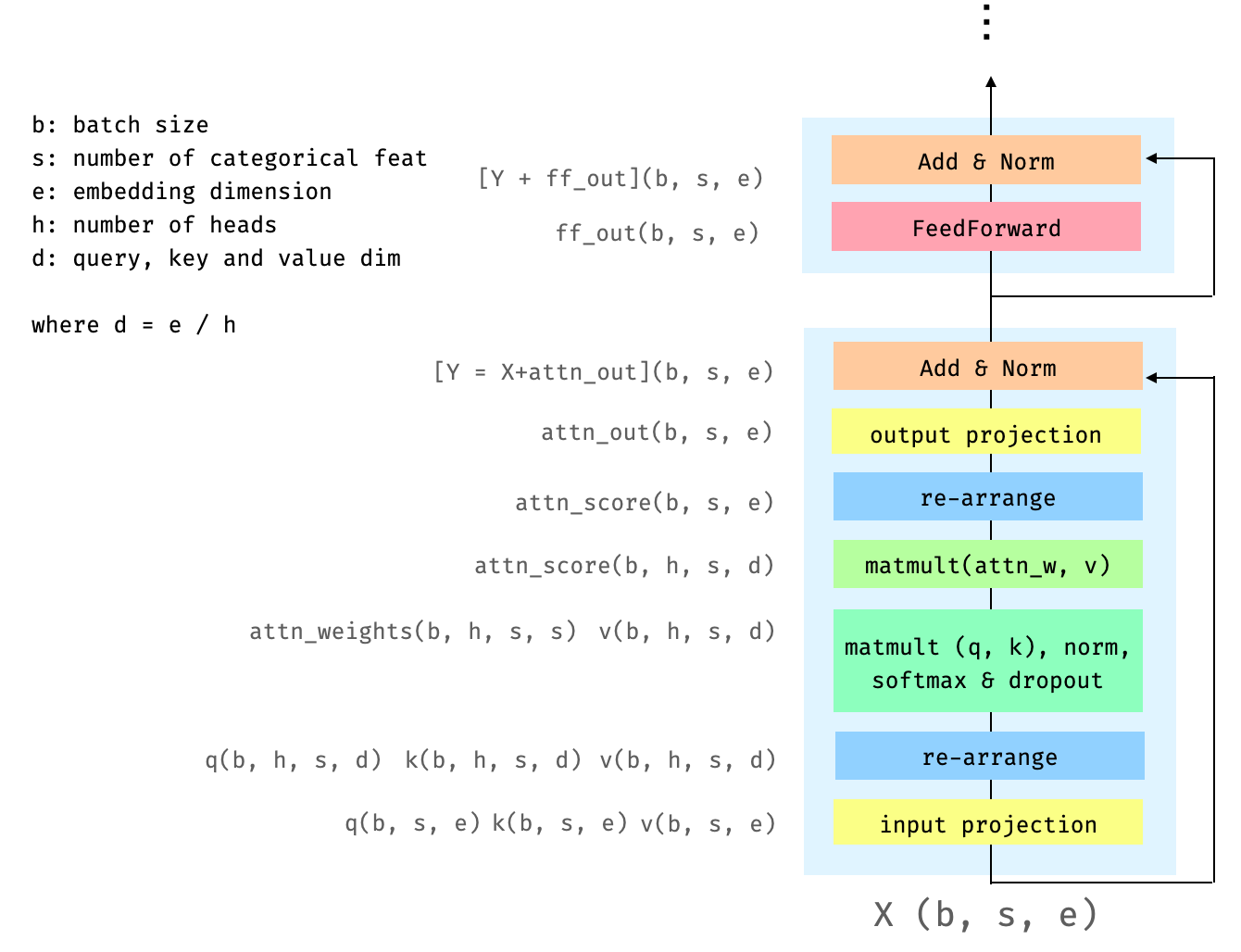
159.7 KB
docs/figures/widedeep_arch.png
0 → 100644
{kind=link}
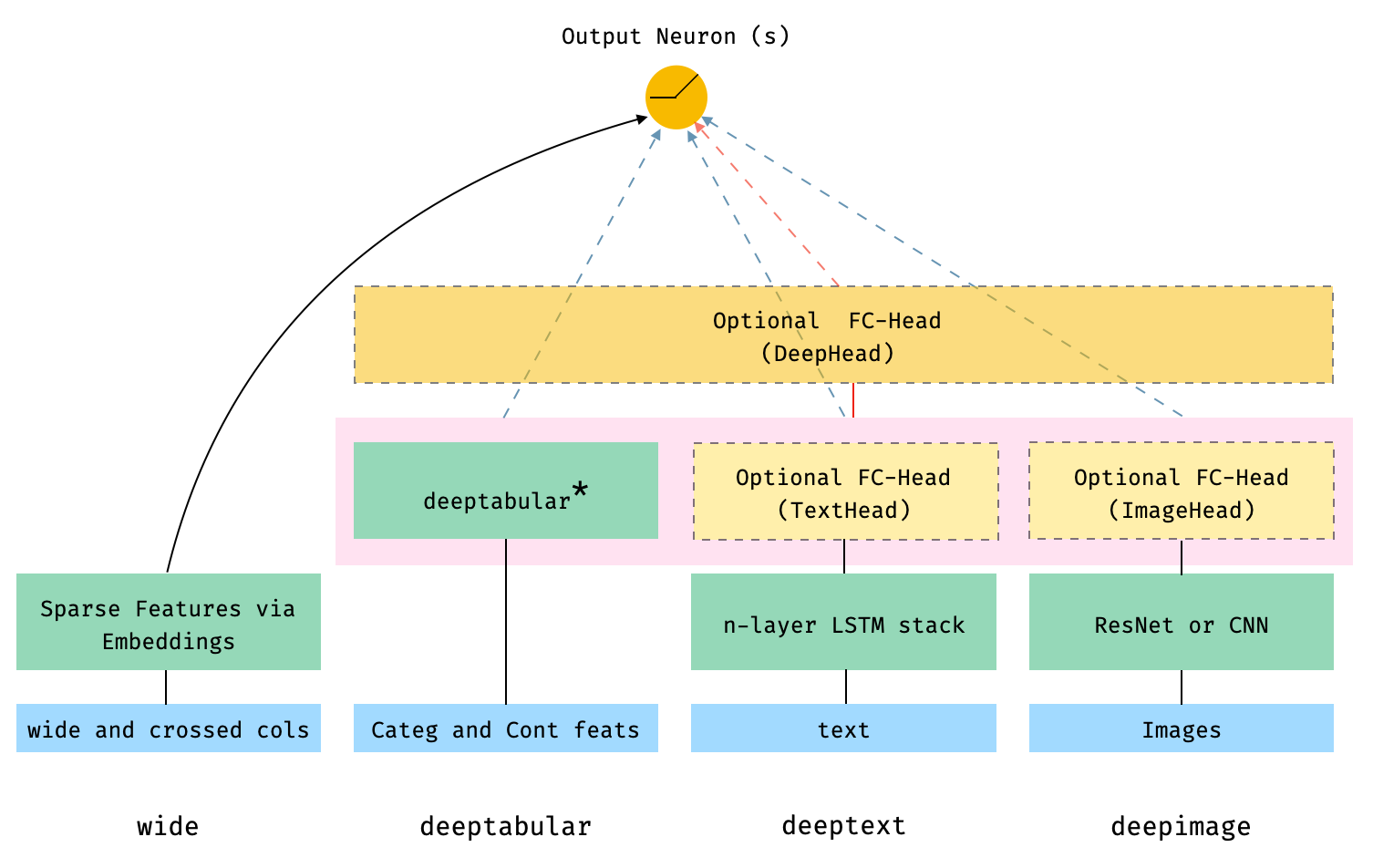
142.8 KB
{kind=link}
72.8 KB
{kind=link}
38.0 KB
{kind=link}
86.5 KB
docs/infinitoml.ico
已删除
100644 → 0
253.2 KB
docs/trainer.rst
0 → 100644
docs/utils/deeptabular_utils.rst
0 → 100644
docs/utils/dense_utils.rst
已删除
100644 → 0
docs/wide_deep.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/test_losses/test_losses.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。