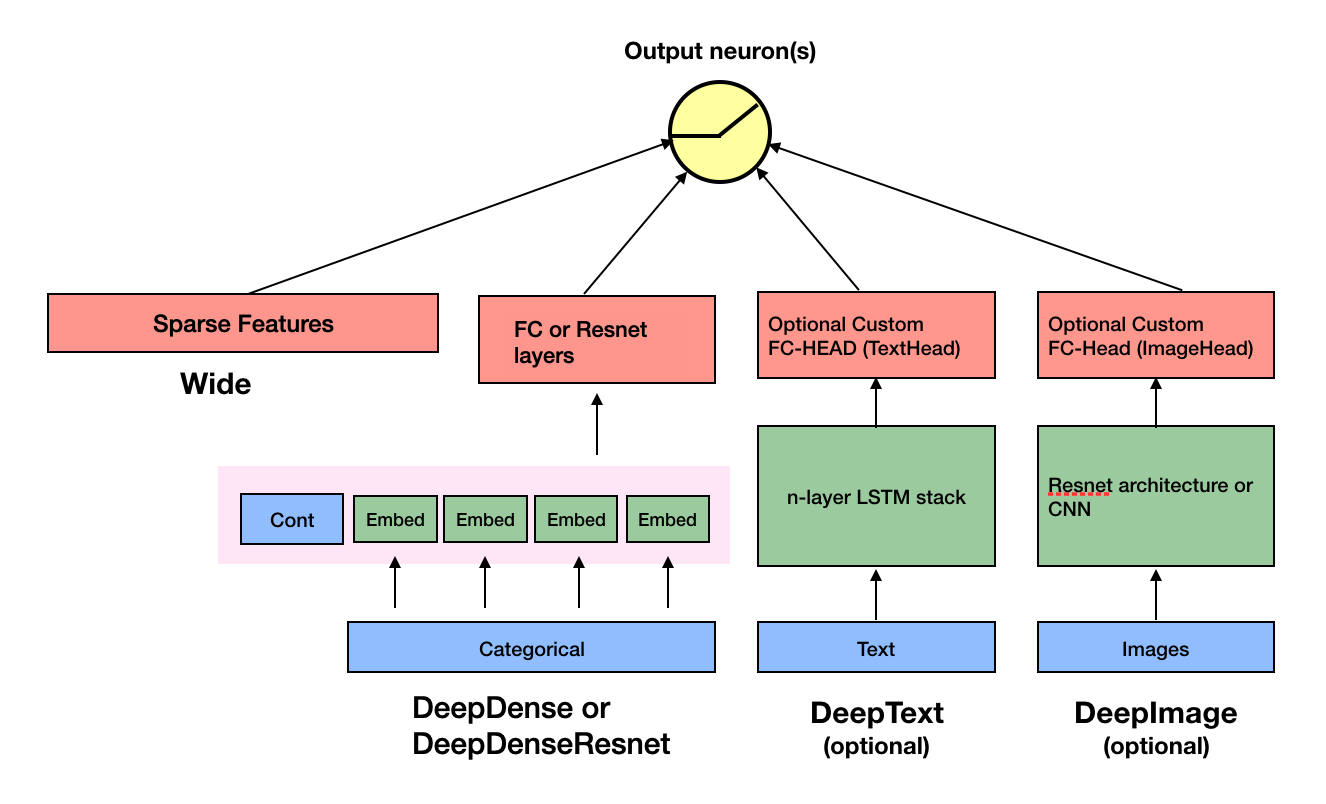
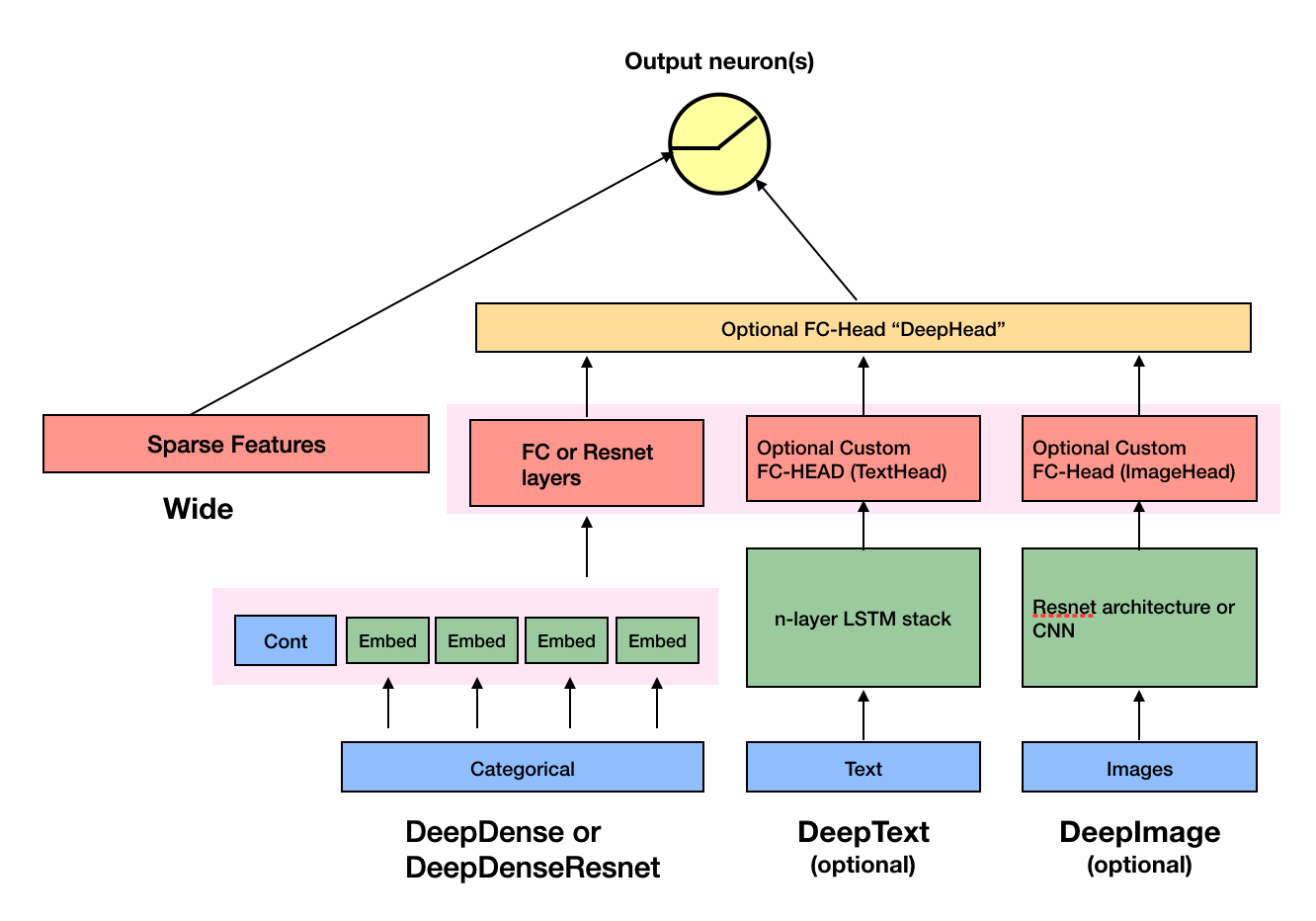
changed the dense layer to be almost identical to that of fastai, which I...
changed the dense layer to be almost identical to that of fastai, which I really like. Changed the code accordingly. Changed the name of DeepDense and DeepDenseResnet to TabMlp and TabResnet. Change the tests acccordingly
Showing
{kind=link}
116.7 KB
{kind=link}
126.4 KB
{kind=link}
72.8 KB
{kind=link}
38.0 KB
{kind=link}
86.5 KB
文件已移动