docs - add pxf content into gpdb doc set (#3486)
* docs - integrate pxf markdown docs into gpdb dita * incorporate initial review edits from david * updates for david review (PART 2) * incorporate comments from shivram * hdfs/hive installcfg - copy cfg files from hdfs cluster * update hadoop cluster dir for copy example, cfg chg note * client inst/cfg - reiterate must be tarball in step
Showing
{kind=link}
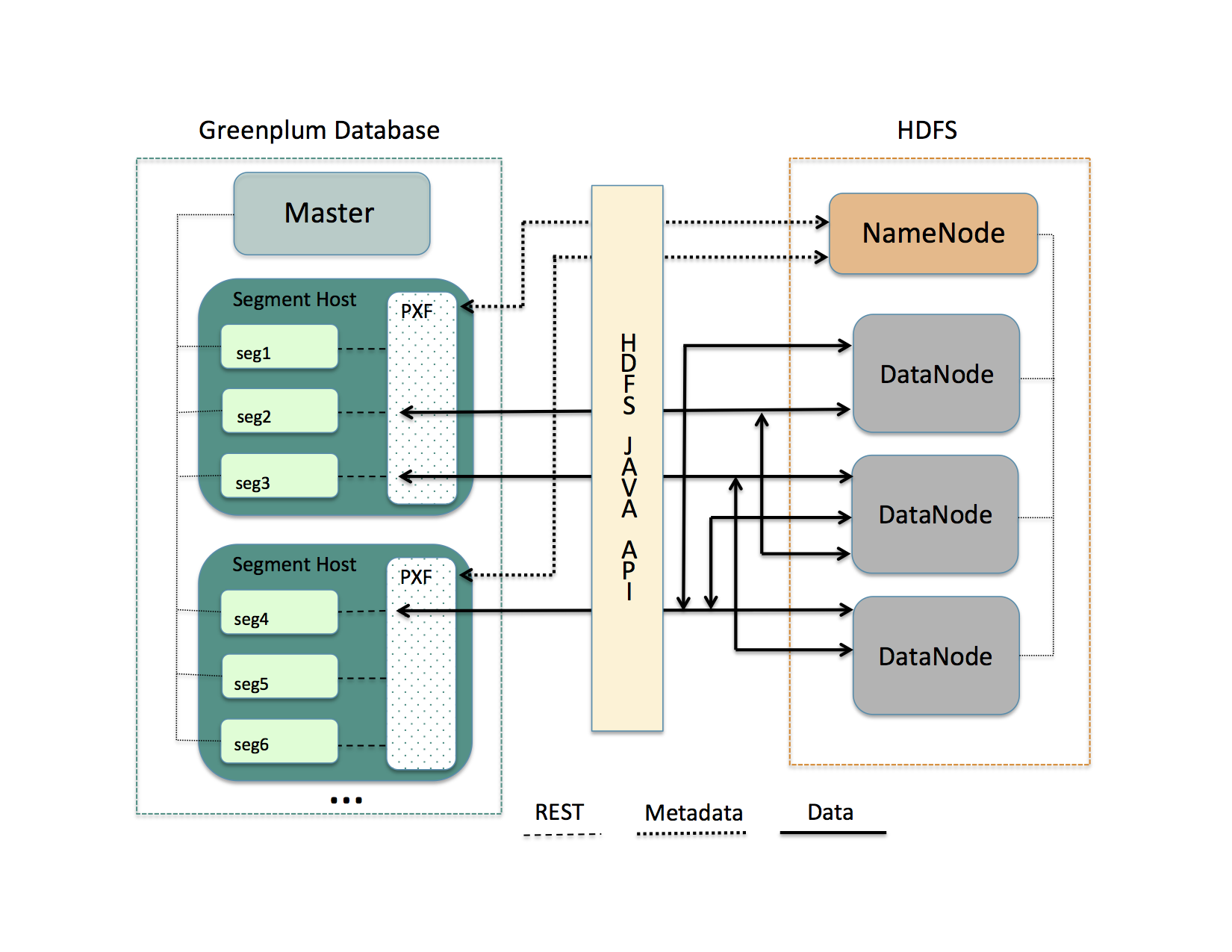
311.2 KB
此差异已折叠。
此差异已折叠。