Conv mixer (#100)
Showing
docs/conv_mixer/conv_mixer.png
0 → 100644
{kind=link}
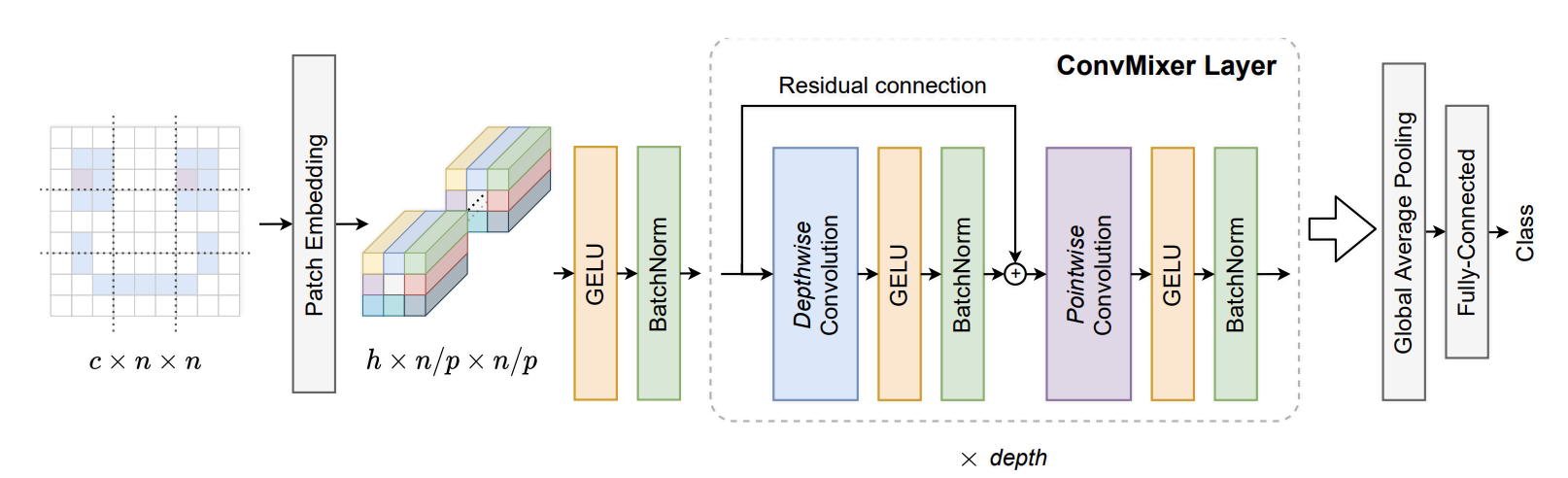
170.2 KB
docs/conv_mixer/experiment.html
0 → 100644
docs/conv_mixer/index.html
0 → 100644
此差异已折叠。
labml_nn/conv_mixer/__init__.py
0 → 100644
labml_nn/conv_mixer/experiment.py
0 → 100644