{: .align-center}
{: .align-center}
{: .align-center}
{: .align-center}
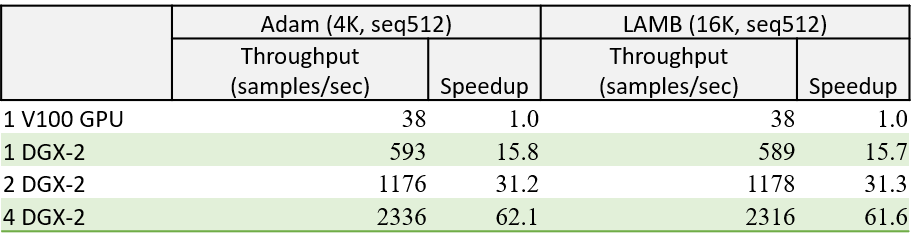
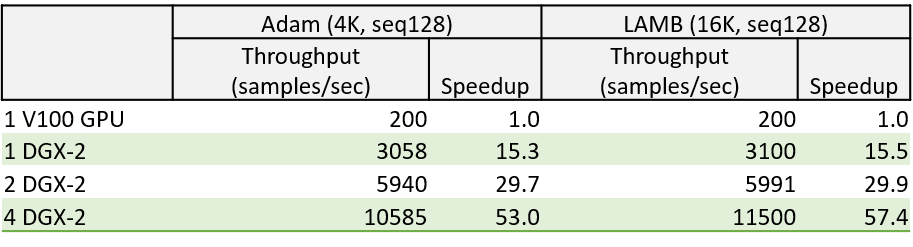
Compared to SOTA, DeepSpeed significantly improves single GPU performance for transformer-based model like BERT. Figure above shows the single GPU throughput of training BertBERT-Large optimized through DeepSpeed, compared with two well-known Pytorch implementations, NVIDIA BERT and HuggingFace BERT. DeepSpeed reaches as high as 64 and 53 teraflops throughputs (corresponding to 272 and 52 samples/second) for sequence lengths of 128 and 512, respectively, exhibiting up to 28% throughput improvements over NVIDIA BERT and up to 62% over HuggingFace BERT. We also support up to 1.8x larger batch size without running out of memory.
{kind=link}
{kind=link}