Deepspeed-Ulysses blog (#4201)
Showing
blogs/deepspeed-ulysses/README.md
0 → 100644
{kind=link}
41.2 KB
{kind=link}
49.3 KB
{kind=link}
56.9 KB
{kind=link}
56.9 KB
{kind=link}
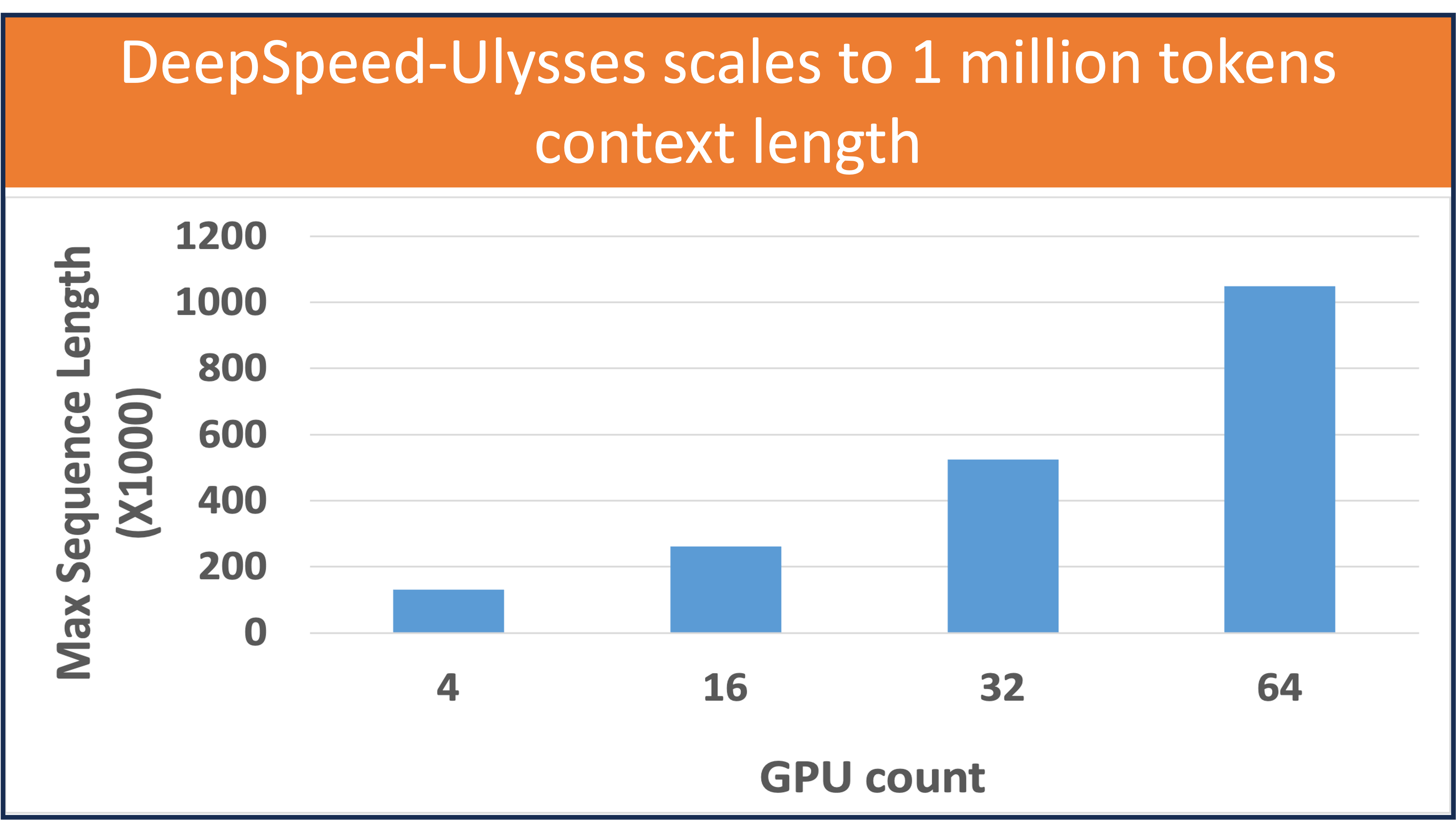
511.6 KB
{kind=link}
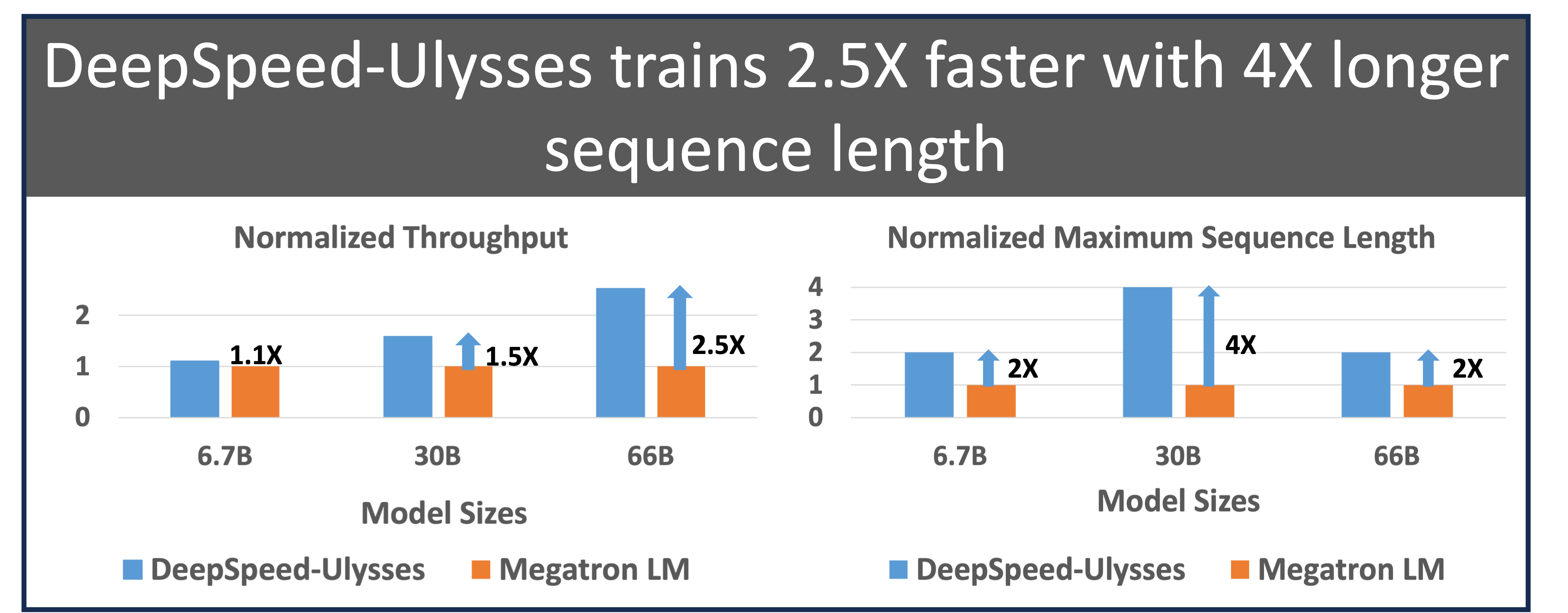
488.0 KB
{kind=link}
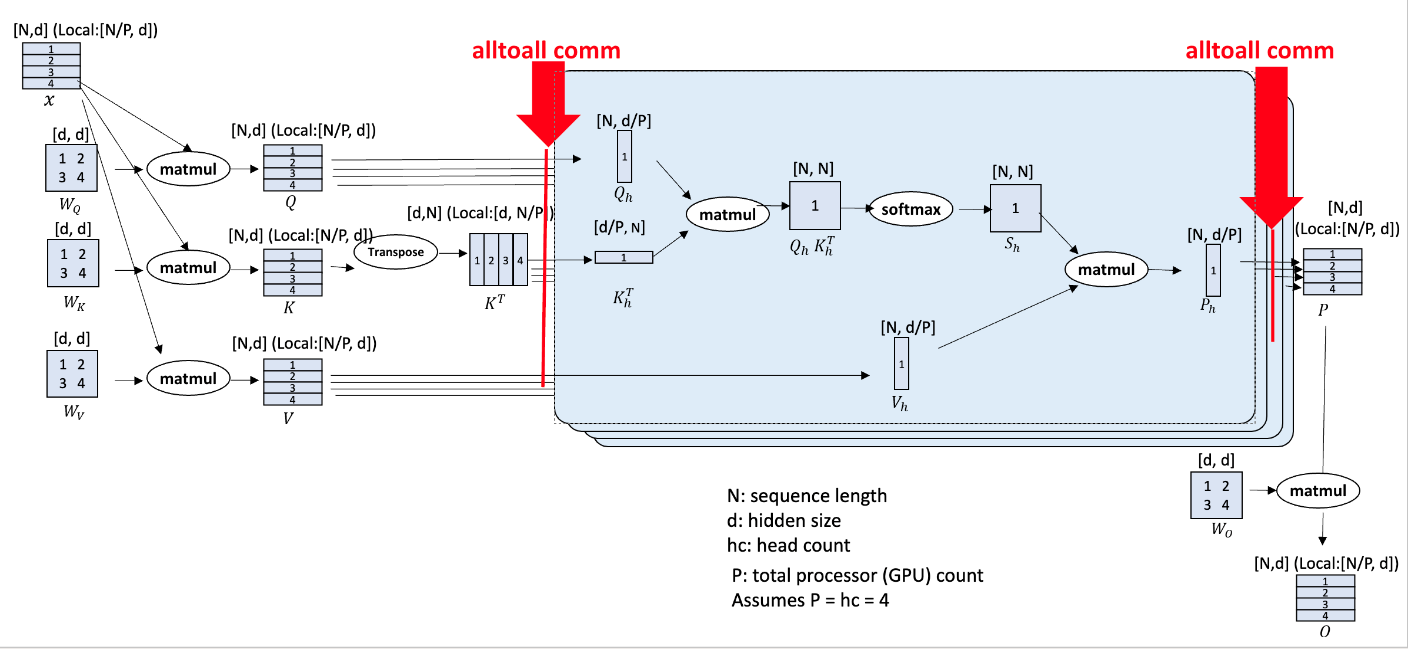
111.6 KB
41.2 KB
49.3 KB
56.9 KB
56.9 KB
511.6 KB
488.0 KB
111.6 KB