DeepSpeed-Triton for Inference (#3748)
Co-authored-by: NStephen Youn <styoun@microsoft.com> Co-authored-by: NArash Bakhtiari <arash@bakhtiari.org> Co-authored-by: NCheng Li <pistasable@gmail.com> Co-authored-by: NEthan Doe <yidoe@microsoft.com> Co-authored-by: Nyidoe <68296935+yidoe@users.noreply.github.com> Co-authored-by: NJeff Rasley <jerasley@microsoft.com>
Showing
{kind=link}
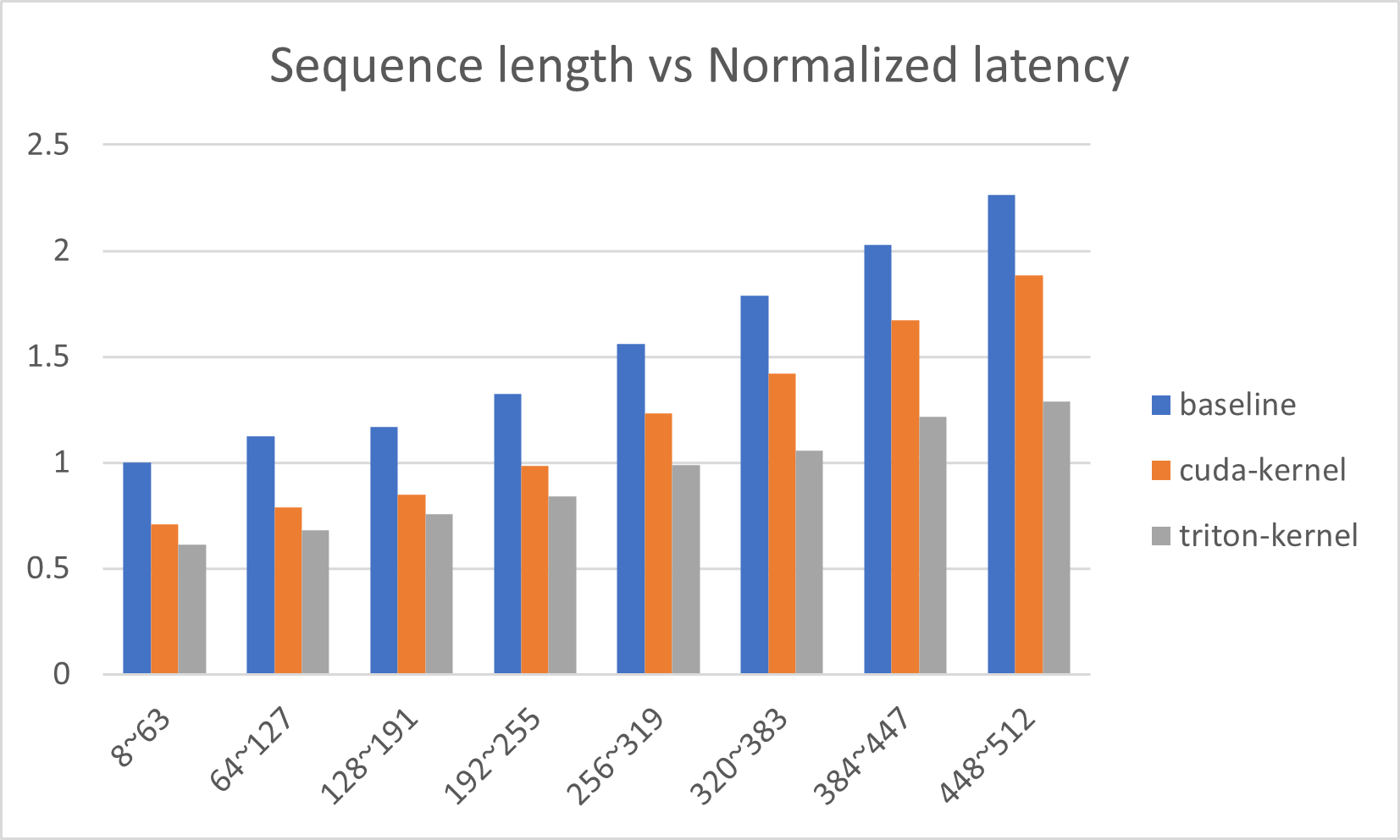
30.6 KB
{kind=link}
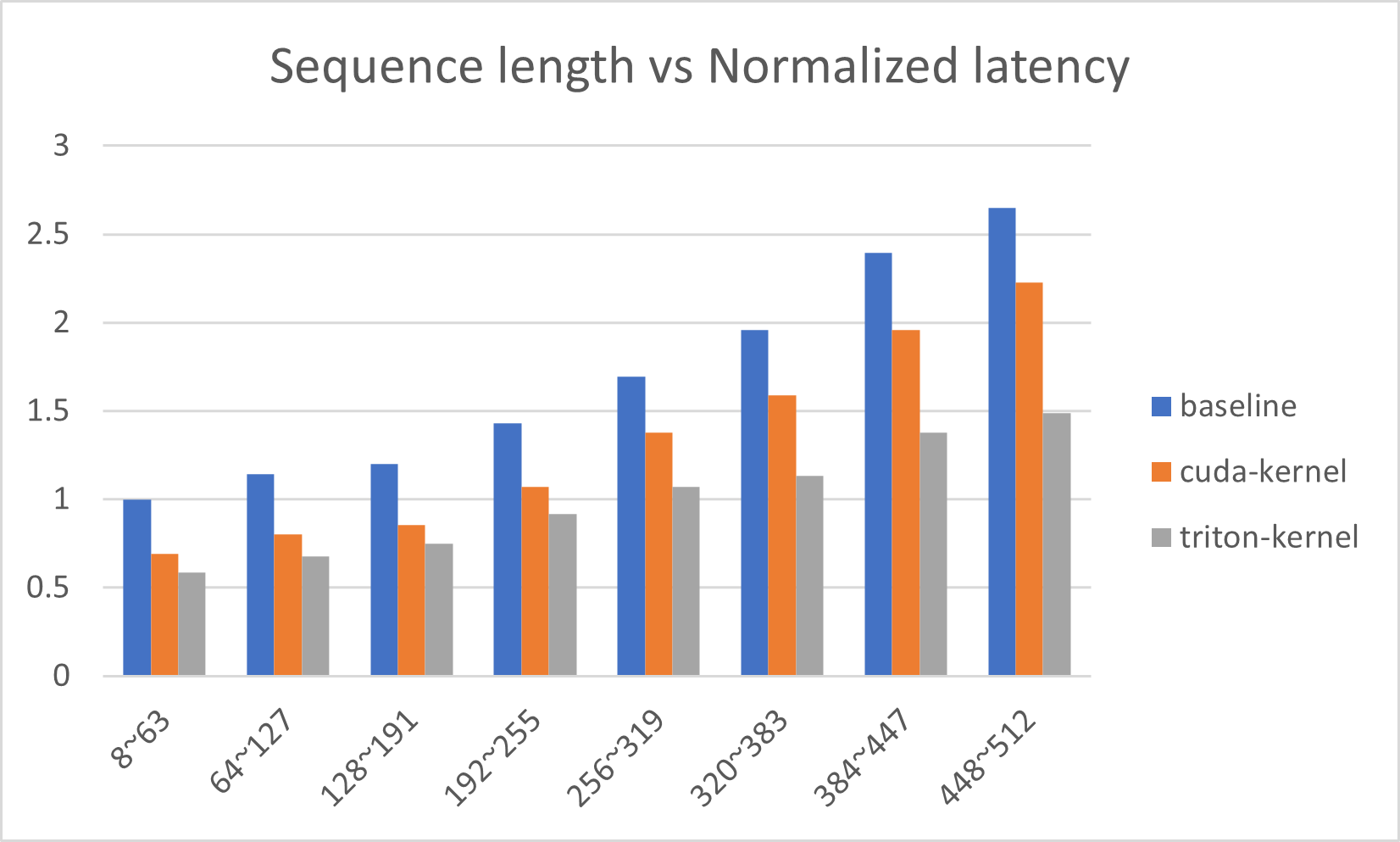
32.2 KB
blogs/deepspeed-triton/README.md
0 → 100644