first draft of project initial files
Showing
.dockerignore
0 → 100644
.env
0 → 100644
.gitattributes
0 → 100644
.gitignore
0 → 100644
.travis.yml
0 → 100644
AUTHORS
0 → 100644
CONTRIBUTORS
0 → 100644
Dockerfile
0 → 100644
Dockerfile.dev
0 → 100644
Makefile
0 → 100644
build/builder-docker/Dockerfile
0 → 100644
build/builder-docker/Makefile
0 → 100644
doc.go
0 → 100644
docker-compose.yml
0 → 100644
docs/README.md
0 → 100644
docs/design/README.md
0 → 100644
docs/design/arch.dot
0 → 100644
docs/development.md
0 → 100644
docs/devops.md
0 → 100644
docs/images/arch.png
0 → 100644
{kind=link}
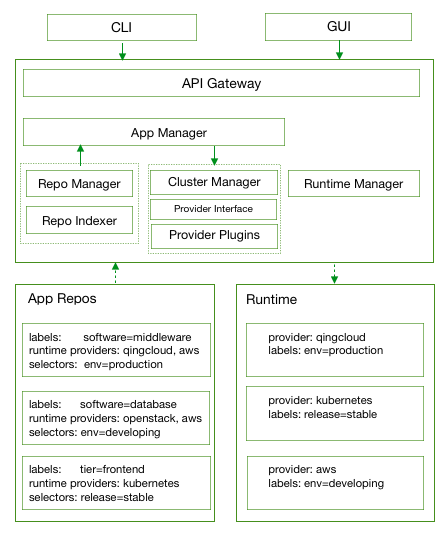
44.8 KB
docs/images/kubernetes.png
0 → 100644
{kind=link}
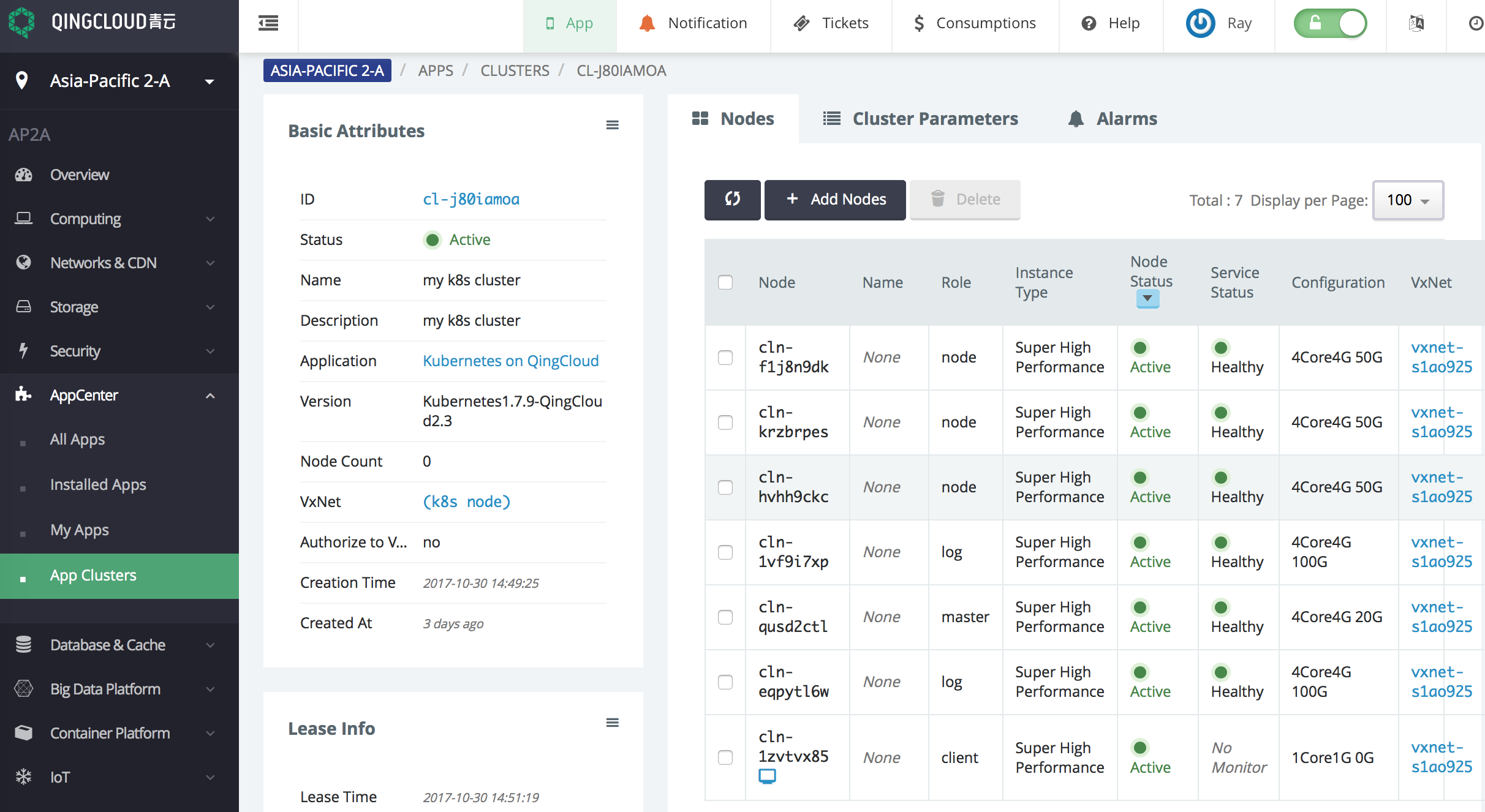
551.2 KB
docs/images/logo.png
0 → 100644
{kind=link}
7.4 KB
docs/images/openvpn.png
0 → 100644
{kind=link}
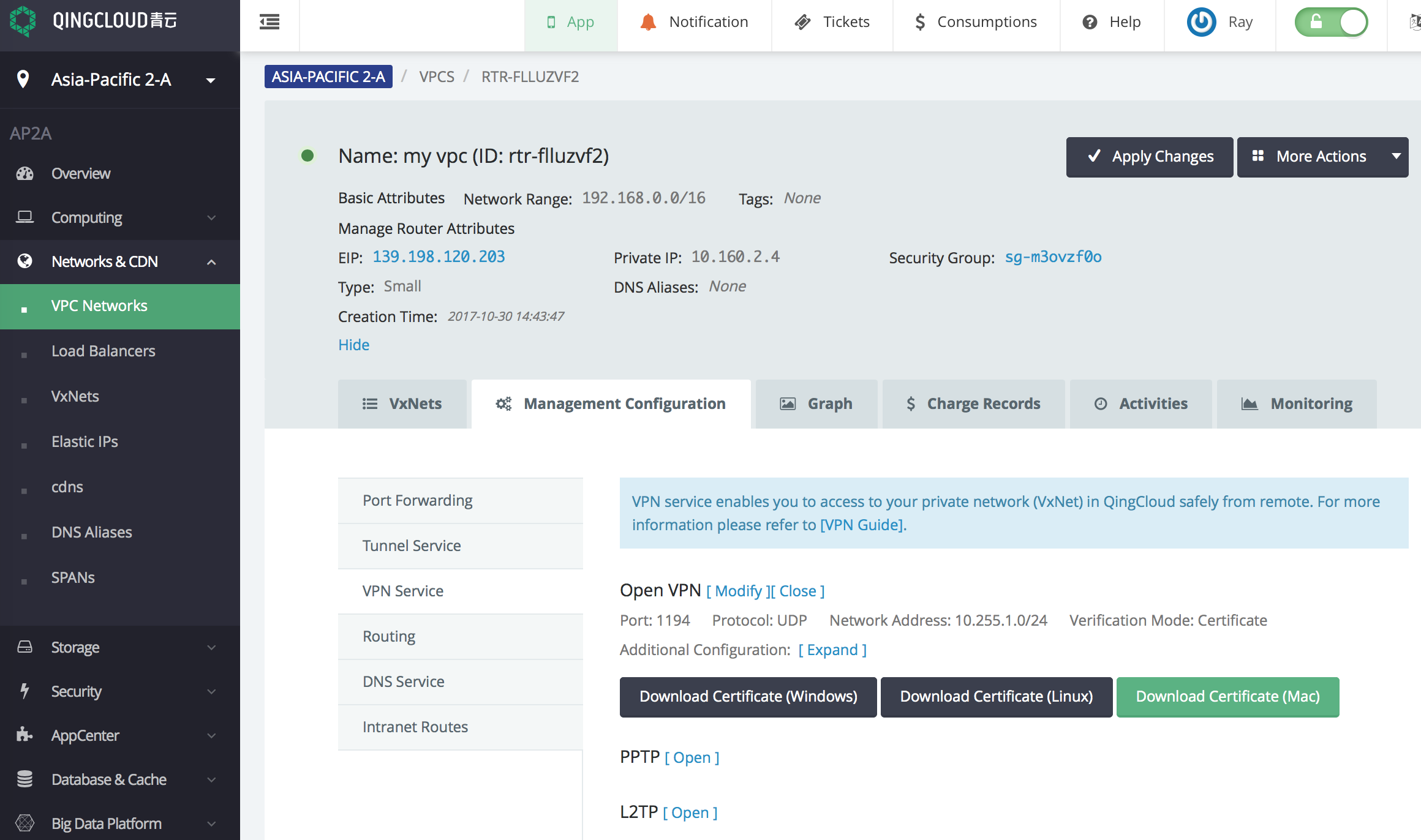
399.1 KB
docs/members.md
0 → 100644
docs/prereqs.md
0 → 100644
docs/pull-requests.md
0 → 100644