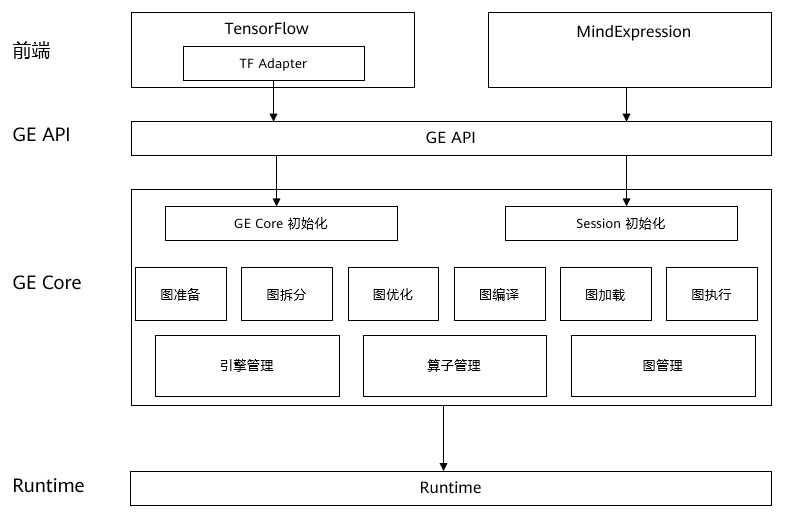
GraphEngine(GE) is a sub-module of MindSpore connecting the front end and devices which was designed by the researches and engineers within Huawei Technologies Co.,Ltd. GE is implemented via C++. It takes the graph of front end as its input and a series of graph operations are carried out to adapt the graph to a certain form which can be effectively operated on devices. GE is specifically designed for an efficient operation on Ascend Chips. GE is automatically called without any exposure to the users. GE mainly consists of two parts, i.e. GE API and GE Core. The architecture diagram of GE is illustrated as follows

...
...
@@ -10,25 +12,21 @@
GE Core acts as the core module of GE and is responsible for graph processing operations. It consist of six parts, i.e. graph preparation, graph partition, graph optimization, graph compilation, graph loading and graph execution. These six parts are performed in series and all together complete the complicated graph processing operations.
- Graph preparation
- Graph preparation & Whole graph optimization
All the shapes of feature maps and variables in the graph are inferred in this stage for memory allocation later. Some aggregations of operators like allreduce are performed as well. Ascend Chips are heterogeneous chips including CPUs and vector calculation units, i.e. AICORE. Each operator in the graph is assigned to a certain operating cores according to the costs and supports. These two cores correspond to two different abstract engines in software.
All the shapes of feature maps and variables in the graph are inferred in this stage for memory allocation later. Some aggregations of operators like allreduce are performed as well.
- Graph partition
The whole graph is split into several sub-graphs based on the assigned engine in previous stage. Certain operators are added to the sub-graphs as the marks for graph edges. Such a partition enables an efficient optimization, compilation in next stages.
Ascend Chips are heterogeneous chips including CPUs and vector calculation units, i.e. AICORE. Each operator in the graph is assigned to a certain operating cores according to the costs and supports. These two cores correspond to two different abstract engines in software. The whole graph is split into several sub-graphs based on the assigned engine in previous stage. Certain operators are added to the sub-graphs as the marks for graph edges. Such a partition enables an efficient optimization, compilation in next stages.
-Graph optimization
-Subgraph optimization
Different optimizer interfaces are called due to different engines that each sub-graph belongs to. To thoroughly utilize the calculation ability of the CUBE module in AICORE, A novel data layout format for faster hardware fetch is applied and the transition between normal 4D to this special format is performed in this stage. Such an operation guarantees less data handling between RAMs and CUBEs. Certain combination of operators is fused into a single big operator to further reduce the computation costs. This fusion is carried out in this stage as well.
- Graph compilation
This stage can be divided into two parts, i.e. resources allocation and graph compilation. Memory allocation is completed considering memory reuse strategy in resources allocation stage. According to the graph information, the queue, event, stream resources are allocated. Each operator is compiled to a task bound to a certain stream. Tasks on the same stream are performed in series and task on different streams can be executed in parallel. This stream partition is completed in this stage.
- Graph loading
- Graph compilation & Graph loading
According to the engine information, the operators of graph are assigned to different engines and in this stage, the graph is loaded on the devices for running.
GraphEngine uses real-time operator compilation technology, i.e. the operator executable program is generated at real time according to the network structure. Meanwhile, Memory allocation is completed considering memory reuse strategy in resources allocation stage. According to the graph information, the queue, event, stream resources are allocated. Each operator is compiled to a task bound to a certain stream. Tasks on the same stream are performed in series and task on different streams can be executed in parallel. In the Graph Loading stage, the operators of graph are assigned to different engines according to the engine information, and the graph is loaded on the devices for running.
{kind=link}