Merge branch 'develop' into release/0.10.0
Showing
AUTHORS.md
0 → 100644
authors
已删除
100644 → 0
{kind=link}
179.1 KB
{kind=link}
33.1 KB
{kind=link}
76.7 KB
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
141.7 KB
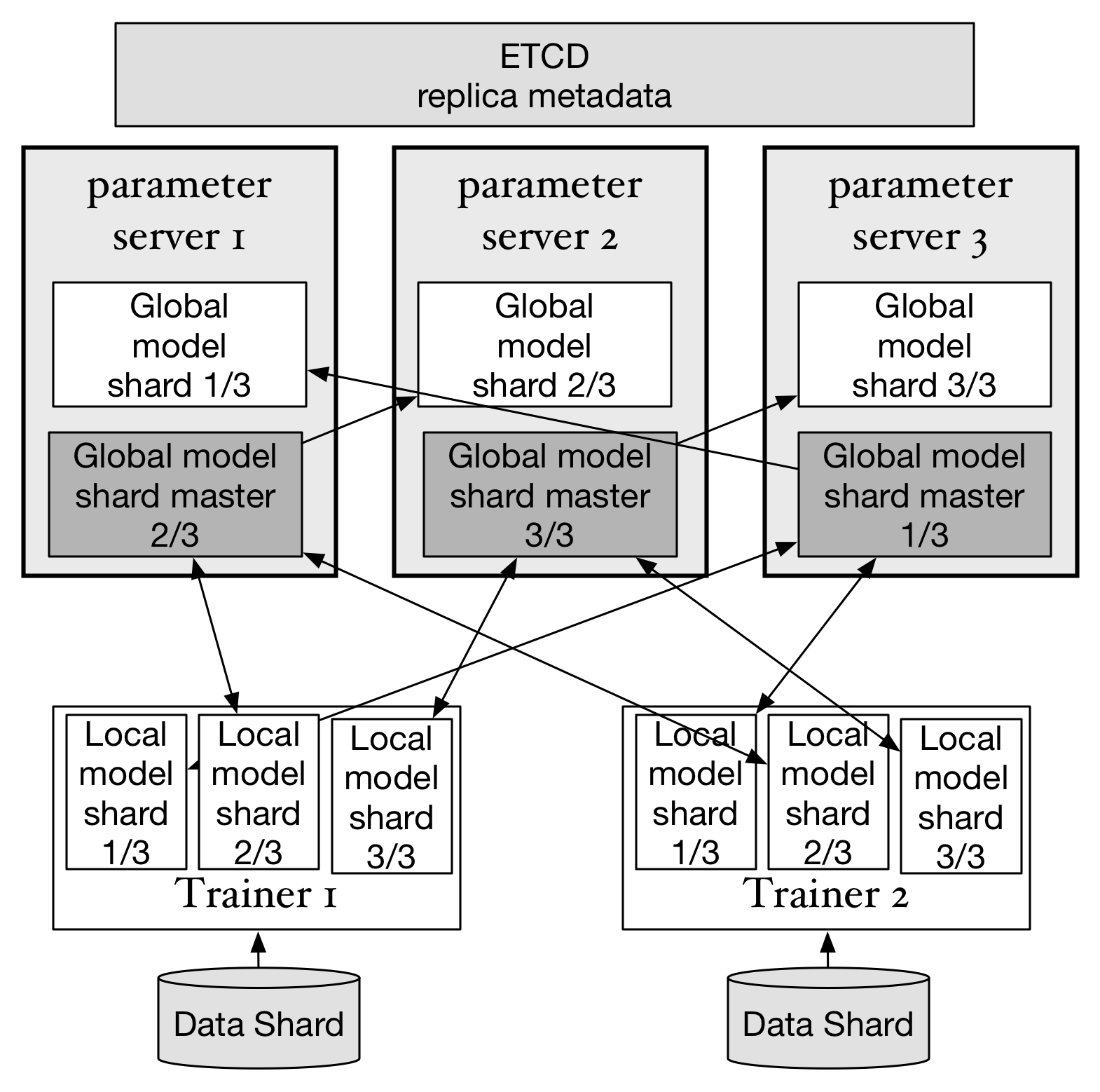
doc/design/images/replica.png
0 → 100644
{kind=link}
174.9 KB
{kind=link}
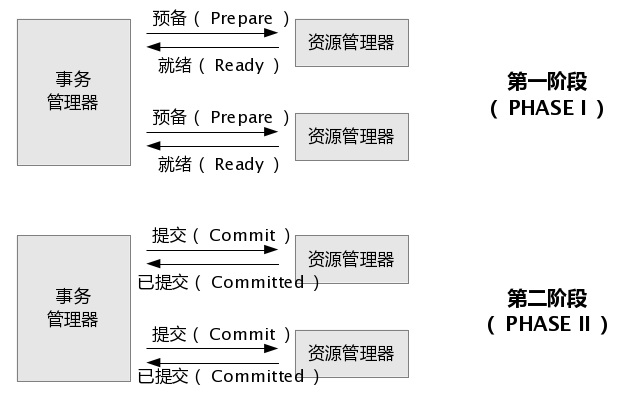
48.0 KB
doc/design/releasing_process.md
0 → 100644
paddle/capi/Arguments.cpp
0 → 100644
paddle/capi/CMakeLists.txt
0 → 100644
paddle/capi/Main.cpp
0 → 100644
paddle/capi/Matrix.cpp
0 → 100644
paddle/capi/Vector.cpp
0 → 100644
paddle/capi/arguments.h
0 → 100644
paddle/capi/capi.h
0 → 100644
paddle/capi/capi_private.h
0 → 100644
paddle/capi/config.h.in
0 → 100644
paddle/capi/error.h
0 → 100644
paddle/capi/examples/.gitignore
0 → 100644
paddle/capi/examples/README.md
0 → 100644
paddle/capi/gradient_machine.cpp
0 → 100644
paddle/capi/gradient_machine.h
0 → 100644
paddle/capi/main.h
0 → 100644
paddle/capi/matrix.h
0 → 100644
paddle/capi/tests/.gitignore
0 → 100644
paddle/capi/tests/CMakeLists.txt
0 → 100644
paddle/capi/tests/test_Matrix.cpp
0 → 100644
paddle/capi/tests/test_Vector.cpp
0 → 100644
paddle/capi/vector.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。