merge origin/develop
Showing
paddle/framework/attribute.cc
0 → 100644
paddle/framework/backward.cc
0 → 100644
此差异已折叠。
paddle/framework/backward.h
0 → 100644
此差异已折叠。
paddle/framework/backward.md
0 → 100644
此差异已折叠。
paddle/framework/backward_test.cc
0 → 100644
此差异已折叠。
文件已添加
{kind=link}
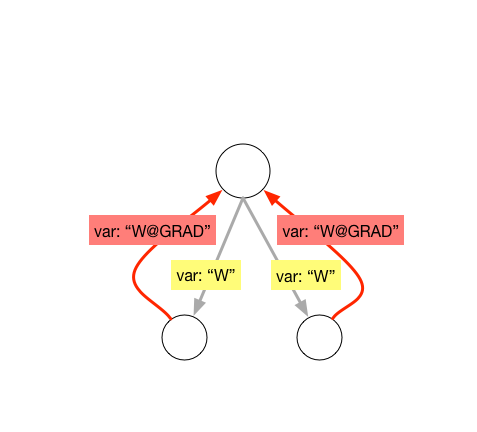
21.4 KB
文件已添加
{kind=link}
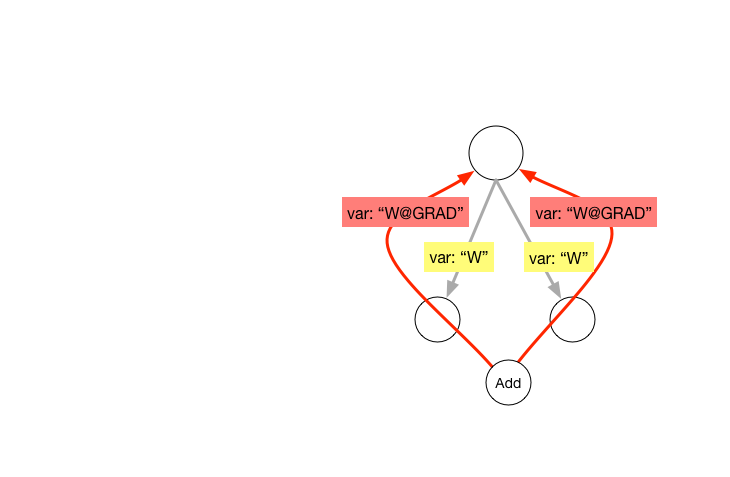
28.3 KB
paddle/framework/pybind.cc
0 → 100644
此差异已折叠。
paddle/framework/scope.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/.clang-format
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/mean_op.cc
0 → 100644
此差异已折叠。
paddle/operators/mean_op.cu
0 → 100644
此差异已折叠。
paddle/operators/mean_op.h
0 → 100644
此差异已折叠。
paddle/operators/mean_op_test.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/recurrent_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。