Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
GitCode官方
Python专题
提交
b95abeef
Python专题
项目概览
GitCode官方
/
Python专题
通知
4254
Star
1618
Fork
355
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Python专题
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
b95abeef
编写于
7月 21, 2021
作者:
M
MaoXianxin
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
text classification
上级
bafb64cc
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
193 addition
and
0 deletion
+193
-0
stack overflow问题分类.md
stack overflow问题分类.md
+193
-0
未找到文件。
stack overflow问题分类.md
0 → 100644
浏览文件 @
b95abeef
本教程的目的是带领大家学会如何给 stack overflow 上的问题进行打标签
首先我们需要导入要用到的函数库
```
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras import preprocessing
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
```
接下来我们看下 stack overflow 数据集,该数据集有 4 个类别标签,分别是 csharp、java、javascript、python ,每个类别有 2000 个样本,数据集下载地址: http://storage.googleapis.com/download.tensorflow.org/data/stack_overflow_16k.tar.gz
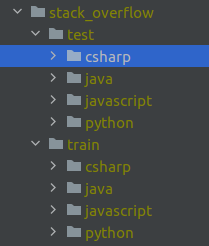
下一步是加载数据集,我们用的是
`tf.keras.preprocessing.text_dataset_from_directory()`
,要求的数据存放结构如下图所示
```
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
```
在开始训练前,我们需要把数据集划分成训练集、验证集、测试集,不过我们看下目录可以发现,已经存在训练集和测试集,那么还缺验证集,这个可以用
`validation_split`
从训练集里划分出来,代码如下所示
```
batch_size = 32
seed = 42
raw_train_ds = tf.keras.preprocessing.text_dataset_from_directory(
'stack_overflow/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed
)
raw_val_ds = tf.keras.preprocessing.text_dataset_from_directory(
'stack_overflow/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed
)
raw_test_ds = tf.keras.preprocessing.text_dataset_from_directory(
'stack_overflow/test',
batch_size=batch_size
)
```
在开始训练之前我们还需要对数据进行一些处理,可以通过调用
`tf.keras.layers.experimental.preprocessing.TextVectorization`
来进行数据的 standardize , tokenize , and vectorize
standardize: 用于移除 remove punctuation or HTML elements
tokenize: 把 strings 切分成 tokens
vectorize: 把 tokens 转化成 numbers ,然后可以送入神经网络
```
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
max_features = 10000
sequence_length = 125
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length
)
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
```
我们可以一起看下处理过后的数据长什么样子,如下图所示

到这一步,我们还需要对数据进行最后一步处理,然后就可以开始训练了
```
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
```
接下来我们开始搭建模型
```
embedding_dim
=
16
model
=
tf
.
keras
.
Sequential
([
layers
.
Embedding
(
max_features
+
1
,
embedding_dim
),
layers
.
Dropout
(
0.2
),
layers
.
GlobalAveragePooling1D
(),
layers
.
Dropout
(
0.2
),
layers
.
Dense
(
4
)
])
model
.
summary
()
model
.
compile
(
loss
=
losses
.
SparseCategoricalCrossentropy
(
from_logits
=
True
),
optimizer
=
'adam'
,
metrics
=[
'accuracy'
])
```
开始模型训练
```
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
```
绘制训练结果图
```
history_dict = history.history
history_dict.keys()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
```
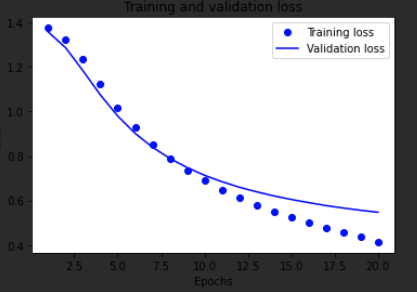
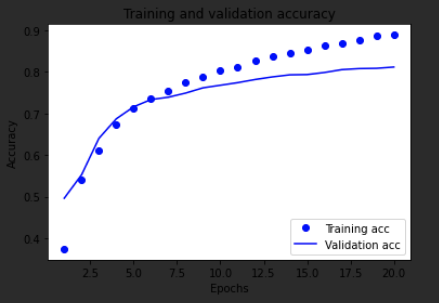
我们来分析下,上面的两个图,第一个图反应的是训练损失值和验证损失值的曲线,我们发现模型过拟合了,针对这种情况我们可以用
`tf.keras.callbacks.EarlyStopping`
来处理,只要在模型的验证损失值不再下降的地方,停止训练就好
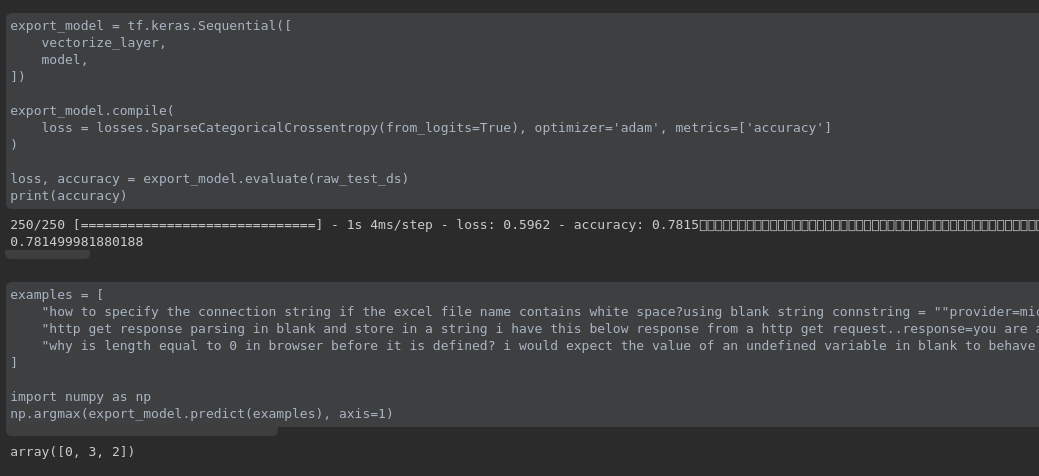
训练完模型之后,我们可以对样本进行预测,比如 examples 里面有 3 个样本,分别截取自 stack overflow 数据集,关于预测效果,大家可以自行测试
代码地址: https://codechina.csdn.net/csdn_codechina/enterprise_technology/-/blob/master/text_classification.ipynb
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录