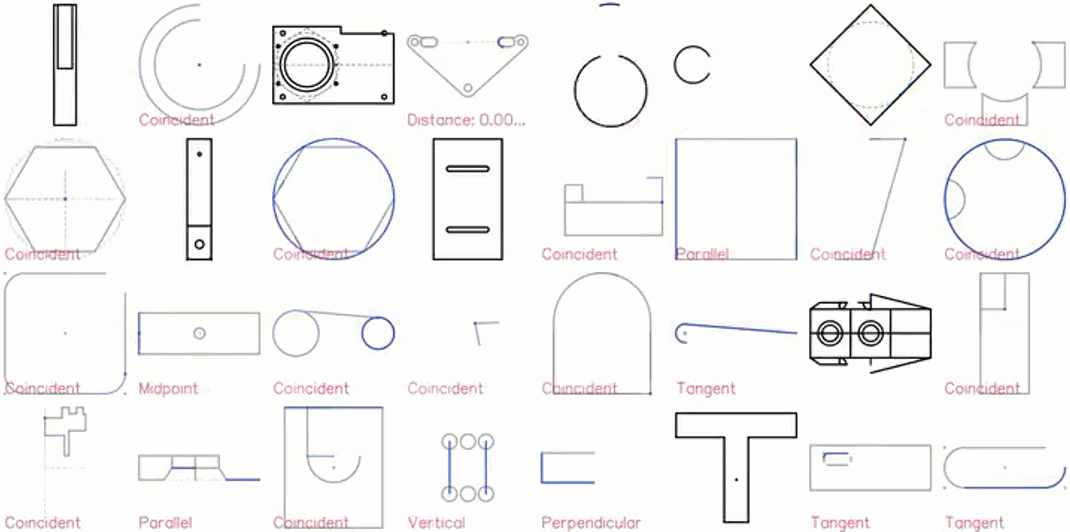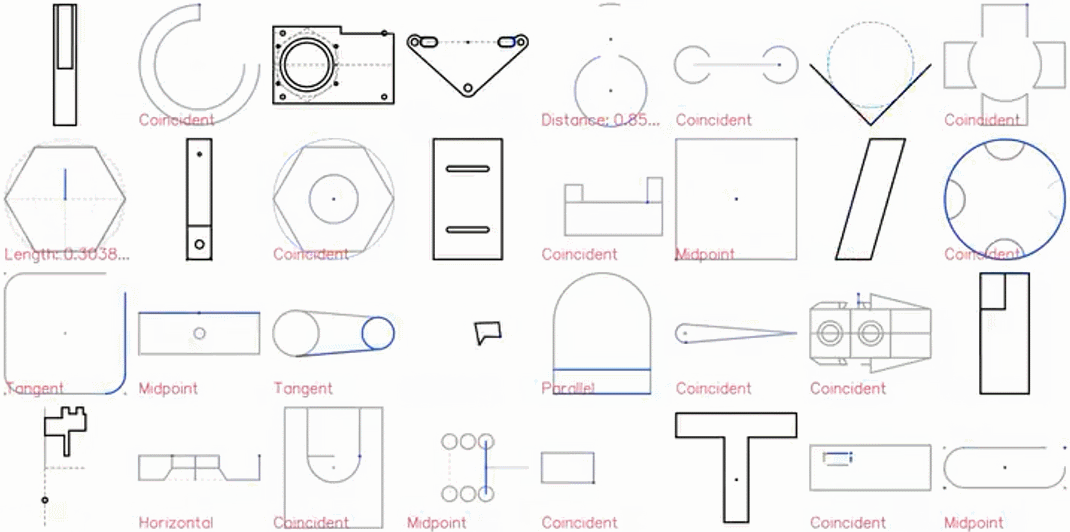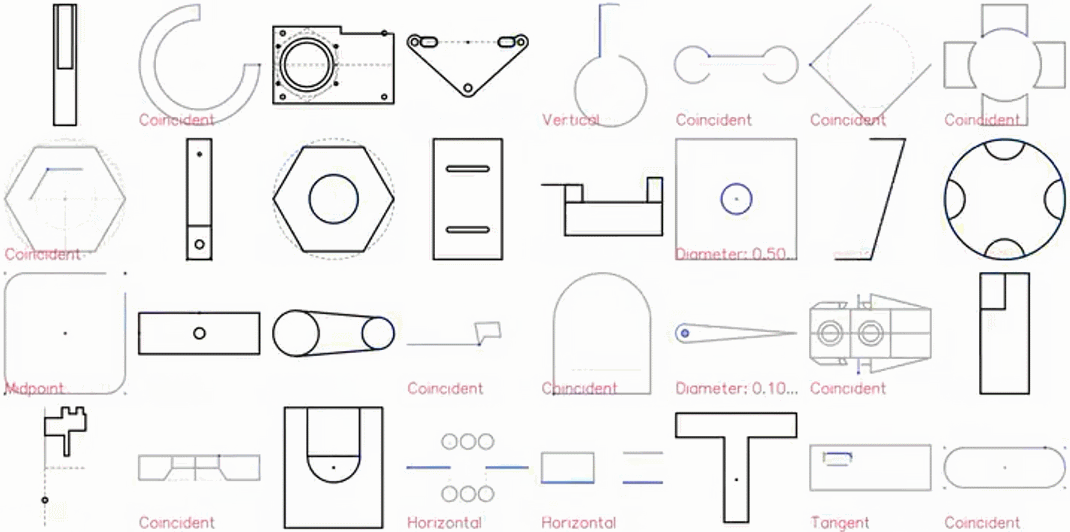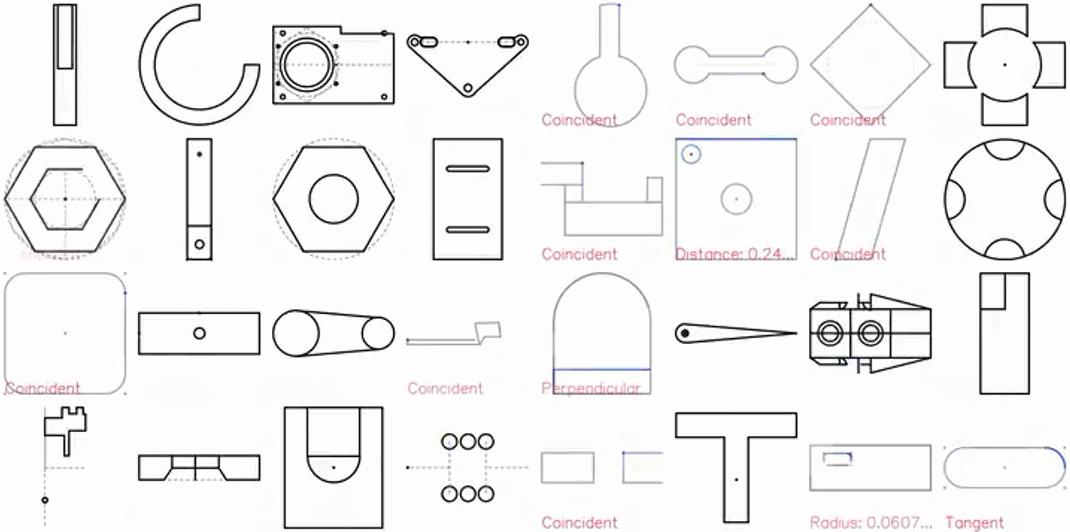
本周AI热点回顾:傅里叶变换取代Transformer,GPU上快7倍、TPU上快2倍;DeepMind新模型自动生成CAD草图
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:
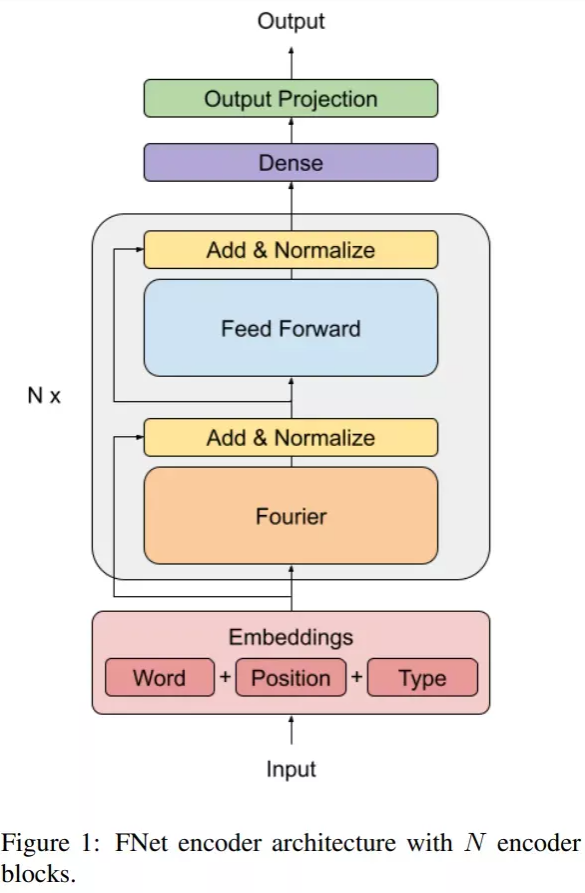
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
imgs/4.gif
0 → 100644
{kind=link}
1.6 MB
imgs/4.png
已删除
100644 → 0
{kind=link}

155.1 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H: