Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
GitCode官方
Python专题
提交
781afc33
Python专题
项目概览
GitCode官方
/
Python专题
通知
4255
Star
1618
Fork
355
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Python专题
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
781afc33
编写于
7月 22, 2021
作者:
M
MaoXianxin
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
text classification with RNN
上级
4c9b711e
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
66 addition
and
0 deletion
+66
-0
text classification with RNN.md
text classification with RNN.md
+66
-0
未找到文件。
text classification with RNN.md
0 → 100644
浏览文件 @
781afc33
本教程的目的是带领大家学会用 RNN 进行文本分类
本次用到的数据集是 IMDB,一共有 50000 条电影评论,其中 25000 条是训练集,另外 25000 条是测试集
首先我们需要加载数据集,可以通过 TFDS 很简单的把数据集下载过来,如下代码所示
```
dataset, info = tfds.load('imdb_reviews', with_info=True, as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset.element_spec
```
接下来我们需要创建 text encoder,可以通过 tf.keras.layers.experimental.preprocessing.TextVectorization 实现,如下代码所示
```
VOCAB_SIZE = 1000
encoder = tf.keras.layers.experimental.preprocessing.TextVectorization(
max_tokens=VOCAB_SIZE
)
encoder.adapt(train_dataset.map(lambda text, label: text))
```
接下来我们需要搭建模型,下图是模型结构图
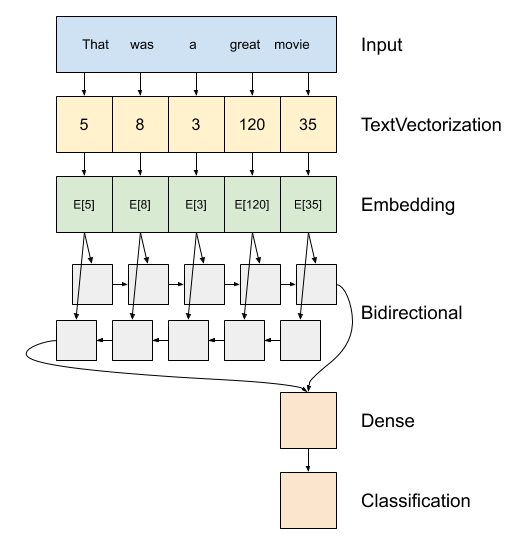
对应的代码如下所示
```
model
=
tf
.
keras
.
Sequential
([
encoder
,
tf
.
keras
.
layers
.
Embedding
(
input_dim
=
len
(
encoder
.
get_vocabulary
()),
output_dim
=
64
,
#
Use
masking
to
handle
the
variable
sequence
lengths
mask_zero
=
True
),
tf
.
keras
.
layers
.
Bidirectional
(
tf
.
keras
.
layers
.
LSTM
(
64
)),
tf
.
keras
.
layers
.
Dense
(
64
,
activation
=
'relu'
),
tf
.
keras
.
layers
.
Dense
(
1
)
])
model
.
compile
(
loss
=
tf
.
keras
.
losses
.
BinaryCrossentropy
(
from_logits
=
True
),
optimizer
=
tf
.
keras
.
optimizers
.
Adam
(
1e-4
),
metrics
=[
'accuracy'
])
```
到这一步,我们就可以开始训练了,以及训练后进行模型评估
```
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
```
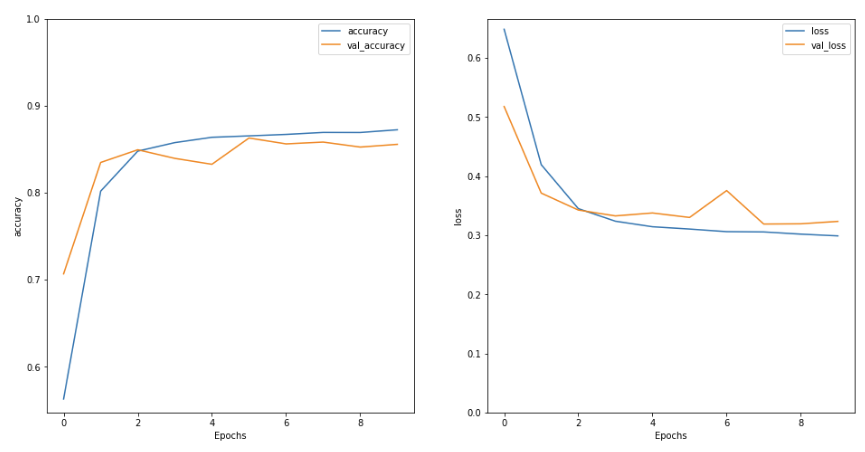
上面是训练的结果记录图
代码地址: https://codechina.csdn.net/csdn_codechina/enterprise_technology/-/blob/master/text_classification_rnn.ipynb
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录