Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
CSDN 技术社区
skill_tree_neo4j
提交
99da4194
S
skill_tree_neo4j
项目概览
CSDN 技术社区
/
skill_tree_neo4j
通知
22
Star
4
Fork
3
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
S
skill_tree_neo4j
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
提交
99da4194
编写于
12月 31, 2021
作者:
幻灰龙
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'master' into 'master'
更新章节内容和问答题目 See merge request
!3
上级
875ff119
c434c06d
变更
8
隐藏空白更改
内联
并排
Showing
8 changed file
with
425 addition
and
6 deletion
+425
-6
data/3.Neo4j 高阶/1.图数据科学和机器学习/1.图数据科学GDS概览/neo4j-gds.md
data/3.Neo4j 高阶/1.图数据科学和机器学习/1.图数据科学GDS概览/neo4j-gds.md
+57
-0
data/3.Neo4j 高阶/1.图数据科学和机器学习/2.图算法概览/neo4j-graph-algorithms.md
...3.Neo4j 高阶/1.图数据科学和机器学习/2.图算法概览/neo4j-graph-algorithms.md
+52
-2
data/3.Neo4j 高阶/1.图数据科学和机器学习/3.图嵌入概览/neo4j-graph-embedding.md
.../3.Neo4j 高阶/1.图数据科学和机器学习/3.图嵌入概览/neo4j-graph-embedding.md
+59
-0
data/3.Neo4j 高阶/1.图数据科学和机器学习/4.自然语言处理NLP概览/neo4j-nlp.md
data/3.Neo4j 高阶/1.图数据科学和机器学习/4.自然语言处理NLP概览/neo4j-nlp.md
+35
-0
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/1.企业版特性概览/neo4j-enterprise.md
...3.Neo4j 高阶/2.Neo4j 企业版和系统运维/1.企业版特性概览/neo4j-enterprise.md
+72
-0
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/2.系统监控/neo4j-monitor.md
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/2.系统监控/neo4j-monitor.md
+73
-0
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/3.性能优化/neo4j-performance-tuning.md
...4j 高阶/2.Neo4j 企业版和系统运维/3.性能优化/neo4j-performance-tuning.md
+43
-2
data/3.Neo4j 高阶/3.图的行业应用/1.图应用架构设计/graph-arch.md
data/3.Neo4j 高阶/3.图的行业应用/1.图应用架构设计/graph-arch.md
+34
-2
未找到文件。
data/3.Neo4j 高阶/1.图数据科学和机器学习/1.图数据科学GDS概览/neo4j-gds.md
浏览文件 @
99da4194
# Neo4j图数据科学(GDS)概览
Neo4j 图形数据科学 (GDS) 库作为 Neo4j 图形数据库的插件提供。该插件需要安装到数据库中并添加到 Neo4j 配置中的许可名单中。有两种主要方法可以实现这一点。
图算法用于计算图、节点或关系的度量。
它们可以提供有关图中相关实体(中心性、排名)或社区等固有结构(社区检测、图分区、聚类)的见解。
许多图算法是迭代方法,它们经常使用随机游走、广度优先或深度优先搜索或模式匹配遍历图进行计算。
由于可能的路径随着距离的增加呈指数增长,许多方法也具有很高的算法复杂性。
幸运的是,存在利用图的某些结构、记忆已经探索过的部分以及并行化操作的优化算法。只要有可能,我们都会应用这些优化。
Neo4j Graph Data Science 库包含大量算法。
GDS 中的算法有特定的方法来利用其输入图的各个方面。我们称这些
*算法特征为*
。当一个算法支持一个算法特征时,这表明该算法已经被实现为根据该特征产生明确定义的结果。
为了尽可能高效地运行算法,Neo4j Graph Data Science 库使用专门的内存图形格式来表示图形数据。因此,有必要将 Neo4j 数据库中的图形数据加载到内存中的图形目录中。加载的数据量可以通过所谓的图形投影来控制,例如,它还允许对节点标签和关系类型进行过滤,以及其他选项。
Neo4j Graph Data Science 库有两个版本。
-
开源社区版包括所有算法和功能,但仅限于四个 CPU 内核。
-
Neo4j 图数据科学库企业版:
-
可以在无限数量的 CPU 内核上运行。
-
支持 Neo4j 企业版的基于角色的访问控制系统 (RBAC)。
-
支持各种附加模型目录功能
-
在模型目录中存储无限数量的模型
-
[
发布存储模型
](
https://neo4j.com/docs/graph-data-science/current/model-catalog/publish/
)
-
[
将存储的模型持久化到磁盘
](
https://neo4j.com/docs/graph-data-science/current/model-catalog/store/#model-catalog-store-ops
)
-
支持
[
优化的内存图实现
](
https://neo4j.com/docs/graph-data-science/current/production-deployment/feature-toggles/#bit-id-map-feature-toggle
)
GDS 库使用模式通常分为两个阶段:开发和生产。在开发阶段,目标是建立有用算法的工作流程。为此,必须配置系统,定义图形投影,并选择算法。利用库的内存估计功能是典型的做法。这使您能够成功配置系统以处理要处理的数据量。有两种资源需要牢记:内存图和算法数据结构。在生产阶段,系统将被适当配置以成功运行所需的算法。操作序列通常是创建一个图形,在其上运行一个或多个算法,并使用结果。
问题:
下列描述中,不正确的一项是?
## 答案
Neo4j GDS是企业版特性,开源社区版无法使用
## 选项
### A
Neo4j GDS提供了多种官方的图算法,用于图数据的机器学习
### B
Neo4j GDS是企业版特性,开源社区版无法使用
### C
Neo4j GDS运行在内存中
### D
Neo4j GDS提供了系统监控程序用来观测运行情况
data/3.Neo4j 高阶/1.图数据科学和机器学习/2.图算法概览/neo4j-graph-algorithms.md
浏览文件 @
99da4194
# Neo4j 图算法概览
\ No newline at end of file
# Neo4j 图算法概览
Neo4j Graph Data Science (GDS) 库包含许多图算法。包含以下类型算法的实现:
-
[
路径查找
](
https://neo4j.com/docs/graph-data-science/current/algorithms/pathfinding/
)
- 这些算法有助于找到最短路径或评估路径的可用性和质量
-
[
中心性
](
https://neo4j.com/docs/graph-data-science/current/algorithms/centrality/
)
- 这些算法确定网络中不同节点的重要性
-
[
社区检测
](
https://neo4j.com/docs/graph-data-science/current/algorithms/community/
)
——这些算法评估一个群体是如何聚集或划分的,以及它加强或分裂的趋势
-
[
相似性
](
https://neo4j.com/docs/graph-data-science/current/algorithms/similarity/
)
- 这些算法有助于计算节点的相似性
-
[
链接预测
](
https://neo4j.com/docs/graph-data-science/current/algorithms/linkprediction/
)
- 这些算法确定节点对的接近程度
-
[
节点嵌入
](
https://neo4j.com/docs/graph-data-science/current/algorithms/node-embeddings/
)
- 这些算法计算图中节点的向量表示。
-
[
节点分类
](
https://neo4j.com/docs/graph-data-science/current/algorithms/node-classification/
)
- 该算法使用机器学习来预测节点的分类。
以下指南提供了图形数据科学库和相关主题部分的更多详细信息和背景。
-
[
图搜索算法
](
https://neo4j.com/developer/graph-data-science/graph-search-algorithms/
)
-
[
寻路算法
](
https://neo4j.com/developer/graph-data-science/path-finding-graph-algorithms/
)
-
[
中心性算法
](
https://neo4j.com/developer/graph-data-science/centrality-graph-algorithms/
)
-
[
社区检测算法
](
https://neo4j.com/developer/graph-data-science/community-detection-graph-algorithms/
)
-
[
图嵌入
](
https://neo4j.com/developer/graph-data-science/graph-embeddings/
)
-
[
链接预测
](
https://neo4j.com/developer/graph-data-science/link-prediction/
)
-
[
连接特征提取
](
https://neo4j.com/developer/graph-data-science/connected-feature-extraction/
)
问题:
下列描述中,不正确的一项是?
## 答案
PageRank不是一种图算法
## 选项
### A
图算法是专门处理关系而构建的数学计算
### B
图搜索(或图遍历)算法探索图以进行一般发现或显式搜索。他们将尝试访问尽可能多的图,但并不期望他们探索的路径在计算上是最优的。
### C
路径查找算法建立在
[
图搜索算法
](
https://neo4j.com/developer/graph-search-algorithms
)
之上,探索节点之间的路径,从一个节点开始,遍历关系直到到达目的地。
### D
中心性算法是图算法的传统类别之一。他们在图中找到重要的节点。
### E
PageRank不是一种图算法
\ No newline at end of file
data/3.Neo4j 高阶/1.图数据科学和机器学习/3.图嵌入概览/neo4j-graph-embedding.md
浏览文件 @
99da4194
# Neo4j 图嵌入概览
图嵌入确定了图中每个实体(通常是节点)的固定长度向量表示。这些嵌入是图的低维表示,并保留了图的拓扑结构。
节点嵌入技术通常包括以下功能:
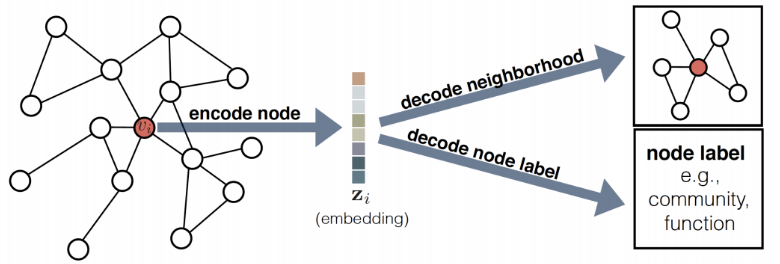
-
相似函数
测量节点之间的相似性
-
编码器功能
生成节点嵌入
-
解码功能
重建成对相似性
-
损失函数
检查重建质量
有几个用例非常适合图嵌入:
-
我们可以借助
[
t 分布随机邻域嵌入
](
https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding
)(
t-SNE
)
和主
[
成分分析
](
https://en.wikipedia.org/wiki/Principal_component_analysis
)(
PCA
)
等算法,通过将嵌入减少到 2 维或 3 维来直观地探索数据。
-
我们可以从嵌入中构建 kNN 相似性图。然后可以使用相似性图来提出建议,作为 k-最近邻查询的一部分。
-
我们可以使用嵌入作为特征输入机器学习模型,而不是手动生成这些特征。在这个用例中,嵌入可以被认为是
[
表征学习的
](
https://en.wikipedia.org/wiki/Feature_learning
)
一种实现。
Neo4j
[
图数据科学库
](
https://neo4j.com/graph-data-science-library
)
支持多种图嵌入算法。
-
随机投影
-
node2vec
-
图SAGE
问题
下列描述中,不正确的一项是?
## 答案
图嵌入是为了将图数据模型转换成二维数据
## 选项
### A
Neo4j 图嵌入是Neo4j GDS库的功能
### B
使用Neo4j 图嵌入可以为机器学习提供图数据模型处理能力
### C
需要图嵌入是因为当前的机器学习无法直接处理图数据
### D
图嵌入是为了将图数据模型转换成二维数据
data/3.Neo4j 高阶/1.图数据科学和机器学习/4.自然语言处理NLP概览/neo4j-nlp.md
浏览文件 @
99da4194
# Neo4j和自然语言处理(NLP)
Neo4j 为结构化数据提供了强大的查询能力,但是世界上很多数据都存在于文本文档中。NLP 技术可以帮助提取这些文档中的潜在结构。这种结构可以像表示句子中标记的节点一样简单,也可以像表示使用命名实体识别算法提取的实体的节点一样复杂。
从文本文档中提取结构并将其存储在图形中可以实现多种不同的用例,包括:
-
基于内容的推荐
-
自然语言搜索
-
文档相似度
[
APOC
](
https://neo4j.com/labs/apoc/4.2/
)
是 Neo4j 的标准库。它包含调用 Amazon Web Services (AWS)、Google Cloud Platform (GCP) 和 Microsoft Azure Natural Language API 的过程,并根据返回的结果创建图。这些过程支持实体提取、关键短语提取、情感分析和文档分类。
问题:
下列描述中,不正确的一项是?
## 答案
三大公有云的Neo4j NLP都提供了Stream和Graph两种模式
## 选项
### A
Neo4j NLP是通过APOC提供的
### B
Neo4j NLP集成了三大公有云的服务
### C
三大公有云的Neo4j NLP都提供了Stream和Graph两种模式
### D
Neo4j NLP可用于实体提取,关键短语,分类和情绪识别等工作
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/1.企业版特性概览/neo4j-enterprise.md
浏览文件 @
99da4194
# Neo4j企业版特性概览
Neo4j 有两个版本可供选择,
[
*社区版*
](
https://neo4j.com/docs/operations-manual/current/introduction/#community-edition
)
和
[
*企业版*
](
https://neo4j.com/docs/operations-manual/current/introduction/#enterprise-edition
)
。Enterprise Edition 包括 Community Edition 必须提供的所有功能,以及额外的企业要求,例如备份、群集和故障转移功能。
社区版是 Neo4j 的全功能版本,适用于单实例部署。它完全支持关键的 Neo4j 功能,例如符合 ACID 的事务、Cypher 和编程 API。它非常适合在小型工作组中学习 Neo4j、DIY 项目和应用程序。
企业版扩展了社区版的功能,包括性能和可扩展性的关键特性,例如集群架构和在线备份功能。其他安全功能包括基于角色的访问控制和 LDAP 支持,例如 Active Directory。它是对规模和可用性有要求的生产系统的选择,例如商业解决方案和关键内部解决方案。
|
**功能特性**
|
**Neo4j 社区版**
|
**Neo4j 企业版**
|
| ----------------------------- | ------------------------------- | ---------------- |
| 在线备份(热备) | No | Yes |
| 数据导出/导入 | Yes | Yes |
| 高可用集群 | No | Yes |
| 因果集群(Causal clustering) | No | Yes |
| 用户安全 | Yes | Yes |
| 基于角色的安全(RBAC) | No | Yes |
| Kerberos安全 | No | Yes |
| 数据限制 | 340亿节点,340亿关系,680亿属性 | 无限制 |
| Neo4j, Inc. 官方支持 | No | Yes |
**Neo4j 集群**
Neo4j 的因果集群提供了三个主要功能:
1.
**安全性:**
核心服务器为事务处理提供了一个容错平台,当这些核心服务器中的大多数正常运行时,该平台将保持可用。
2.
**规模:**
只读副本为图查询提供了一个可大规模扩展的平台,使非常大的图工作负载能够在广泛分布的拓扑中执行。
3.
**因果一致性:**
当调用时,客户端应用程序保证至少读取它自己的写入。
**Neo4j Fabric**
在 Neo4j 4.0 中引入的 Fabric 是一种使用单个 Cypher 查询在多个数据库中存储和检索数据的方法,无论它们是在同一个 Neo4j DBMS 上还是在多个 DBMS 中。Fabric 实现了许多理想的目标:
-
本地和分布式数据的统一视图,可通过单个客户端连接和用户会话访问
-
提高读/写操作、数据量和并发性的可扩展性
-
在正常操作、故障转移或其他基础架构更改期间执行的查询的可预测响应时间
-
大数据量的高可用性和无单点故障。
**Neo4j 备份和恢复**
Neo4j 支持在线和离线数据库的备份和恢复。它使用
[
Neo4j 管理工具
](
https://neo4j.com/docs/operations-manual/current/tools/neo4j-admin/
)
命令,这些命令可以从现场运行,也可以从离线 Neo4j DBMS 运行。所有
`neo4j-admin`
命令都必须以
`neo4j`
用户身份调用以确保适当的文件权限。
**Neo4j 认证和授权**
身份验证是确保用户与用户声称的身份相符的过程,而授权则是检查是否允许经过身份验证的用户执行特定操作。使用基于角色的访问控制 (
*RBAC*
)管理授权。定义访问控制的权限分配给角色,而角色又分配给用户。
问题:
下列描述中不正确的一项是?
## 答案
在公有云上无法部署Neo4j 社区版或企业版
## 选项
### A
Neo4j 社区版和企业版都可以部署在自己的服务器上
### B
Neo4j 社区版适合小型应用和产品验证
### C
Neo4j 企业版提供了支持大数据和生产环境高可用的支持
### D
在公有云上无法部署Neo4j 社区版或企业版
### E
在公有云上可以通过云厂商的Marketplace直接部署预先配置好的Neo4j主机
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/2.系统监控/neo4j-monitor.md
浏览文件 @
99da4194
# Neo4j系统监控
Neo4j 提供了通过指标输出以及对当前执行查询的检查和管理进行持续分析的机制。
可以收集日志以进行连续分析或特定调查。可提供用于生成安全事件日志和查询日志的工具。提供查询管理功能用于对查询性能的特定调查。还提供了监控功能,用于因果集群的临时分析。
Neo4j 提供了一个内置的度量子系统。报告的指标可以通过 JMX 查询、从 CSV 文件中检索或由第三方监控工具使用。
Neo4j 具有以下类型的指标:
-
[
全局
](
https://neo4j.com/docs/operations-manual/current/monitoring/metrics/types/#metrics-global
)
- 涵盖整个 Neo4j DBMS。
-
[
数据库
](
https://neo4j.com/docs/operations-manual/current/monitoring/metrics/types/#metrics-database
)
- 涵盖单个数据库。
全局指标具有以下名称格式:
`<user-configured-prefix>.<metric-name>`
如果
`metrics.namespaces.enabled`
是
`false`
,或者
`<user-configured-prefix>.dbms.<metric-name>`
如果设置是
`true`
。
一旦数据库管理系统可用,就会报告这种类型的度量。例如,所有与 JVM 相关的指标都是全局的。特别是,该
`neo4j.vm.thread.count`
指标具有默认的 user-configured-prefix
`neo4j`
,指标名称为
`vm.thread.count`
。
默认情况下,全局指标包括:
-
页面缓存指标
-
GC 指标
-
线程指标
-
内存池指标
-
内存缓冲区指标
-
文件描述符指标
-
数据库操作指标
-
Bolt 指标
-
Web 服务器指标
每个数据库指标仅针对特定数据库报告。数据库指标仅在数据库的生命周期内可用。当数据库变得不可用时,它的所有指标也变得不可用。
数据库指标具有以下名称格式:
`<user-configured-prefix>.<database-name>.<metric-name>`
如果
`metrics.namespaces.enabled`
是
`false`
,或者
`<user-configured-prefix>.database.<database-name>.<metric-name>`
如果设置是
`true`
。
例如,任何事务度量都是数据库度量。特别是,该
`neo4j.mydb.transaction.started`
指标具有默认的 user-configured-prefix
`neo4j`
,它是
`mydb`
数据库的指标。
默认情况下,数据库指标包括:
-
交易指标
-
检查点指标
-
日志轮换指标
-
数据库数据指标
-
Cypher 指标
-
因果聚类指标
---
问题:
下列描述中,哪一个是不正确的?
## 答案
设置监控指标的功能在社区版和企业版中都可用
## 选项
### A
默认情况下Neo4j启用了CSV日志记录
### B
可以通过设置启用将监控度量发送到Graphite系统
### C
可以通过设置启用将监控度量发送到Prometheus系统
### D
可以通过设置以JMX MBean方式公开监控度量
### E
设置监控指标的功能在社区版和企业版中都可用
data/3.Neo4j 高阶/2.Neo4j 企业版和系统运维/3.性能优化/neo4j-performance-tuning.md
浏览文件 @
99da4194
# Neo4j性能调优
\ No newline at end of file
# Neo4j性能调优
-
[
内存配置
](
https://neo4j.com/docs/operations-manual/current/performance/memory-configuration/
)
— 如何配置内存设置以实现高效操作。
-
[
索引配置
](
https://neo4j.com/docs/operations-manual/current/performance/index-configuration/
)
——如何配置索引。
-
[
垃圾收集器
](
https://neo4j.com/docs/operations-manual/current/performance/gc-tuning/
)
——如何配置 Java 虚拟机的垃圾收集器。
-
[
Bolt 线程池配置
](
https://neo4j.com/docs/operations-manual/current/performance/bolt-thread-pool-configuration/
)
——如何配置 Bolt 线程池。
-
[
Linux 文件系统调优
](
https://neo4j.com/docs/operations-manual/current/performance/linux-file-system-tuning/
)
— 如何配置 Linux 文件系统。
-
[
磁盘、RAM 和其他提示
](
https://neo4j.com/docs/operations-manual/current/performance/disks-ram-and-other-tips/
)
— 磁盘、RAM 和其他提示。
-
[
统计和执行计划
](
https://neo4j.com/docs/operations-manual/current/performance/statistics-execution-plans/
)
——模式统计和执行计划如何影响 Cypher 查询性能。
-
[
空间重用
](
https://neo4j.com/docs/operations-manual/current/performance/space-reuse/
)
——数据删除和存储空间重用。
---
问题:
下列描述中,不正确的是哪一项?
## 答案
用户不能配置Bolt线程连接池来优化程序
## 选项
### A
可以在Neo4j Browser里运行
`EXPLAIN`
来查看Cypher的执行计划
### B
可以在Neo4j Browser里运行
`PROFILE`
来查看Cypher语句的执行情况
### C
Neo4j 运行在JVM中,因此可以使用常规JVM调优方式进行优化
### D
Neo4j的索引支持查询优化和全文搜索优化
### E
用户不能配置Bolt线程连接池来优化程序
\ No newline at end of file
data/3.Neo4j 高阶/3.图的行业应用/1.图应用架构设计/graph-arch.md
浏览文件 @
99da4194
...
...
@@ -2,4 +2,36 @@
图的应用比我们想象的要更广泛和深入,随着大数据的发展和沉淀,越来越多的行业正在应用图数据平台解决多种问题。
现在开始学习图数据平台,结合行业领域的业务知识,将会产生很多领域专家。我们将这些人成为图专家。
\ No newline at end of file
现在开始学习图数据平台,结合行业领域的业务知识,将会产生很多领域专家。我们将这些人成为图专家。
---
问题:
下列说法中,不正确的一项是?
## 答案
图数据只是一种数据的存储,跟行业的业务关系不大
## 选项
### A
知识图谱在各行业的应用越来越广泛,现在是个好机会学习和掌握图数据库来实现知识图谱
### B
金融行业的图数据应用比如欺诈检测需要用到图算法
### C
互联网行业里已经有很多图数据平台的实际应用,比如社交网络、电商推荐系统等
### D
掌握图数据是一种新的思维方式,可以帮助更好地理解业务
### E
图数据只是一种数据的存储,跟行业的业务关系不大
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
