
k8s架构
Showing
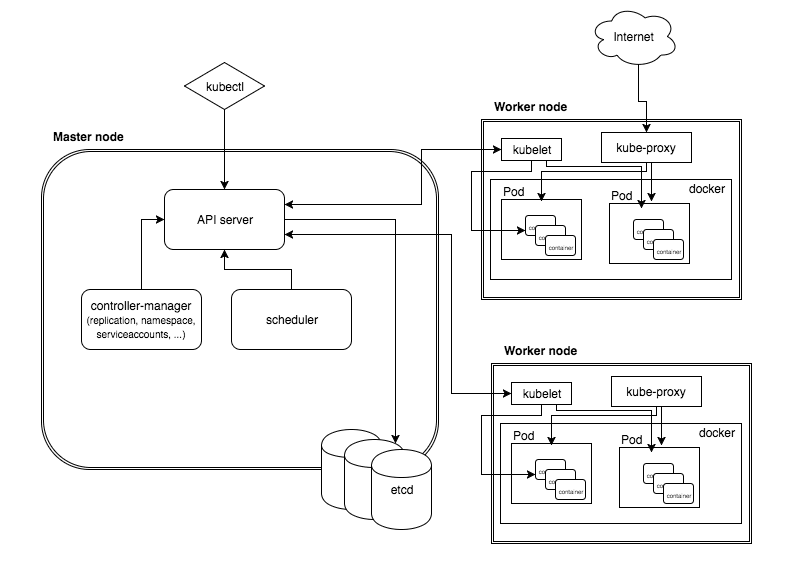
arch/images/arch.png
0 → 100644
{kind=link}
12.0 KB
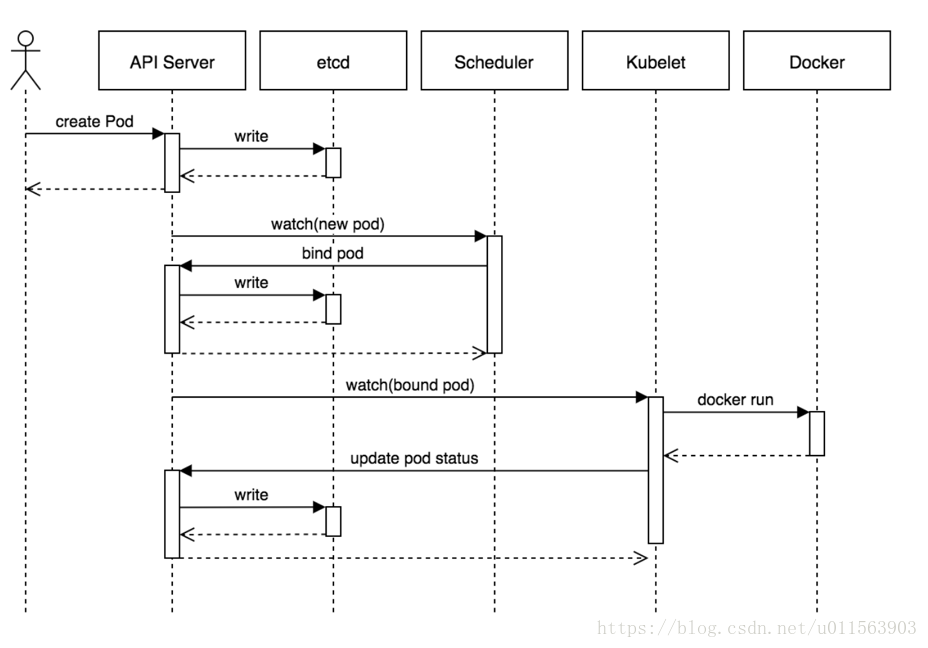
arch/images/create_pod.png
0 → 100644
{kind=link}
81.1 KB
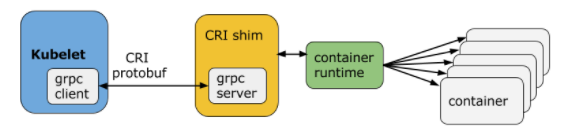
arch/images/cri.png
0 → 100644
{kind=link}
32.4 KB
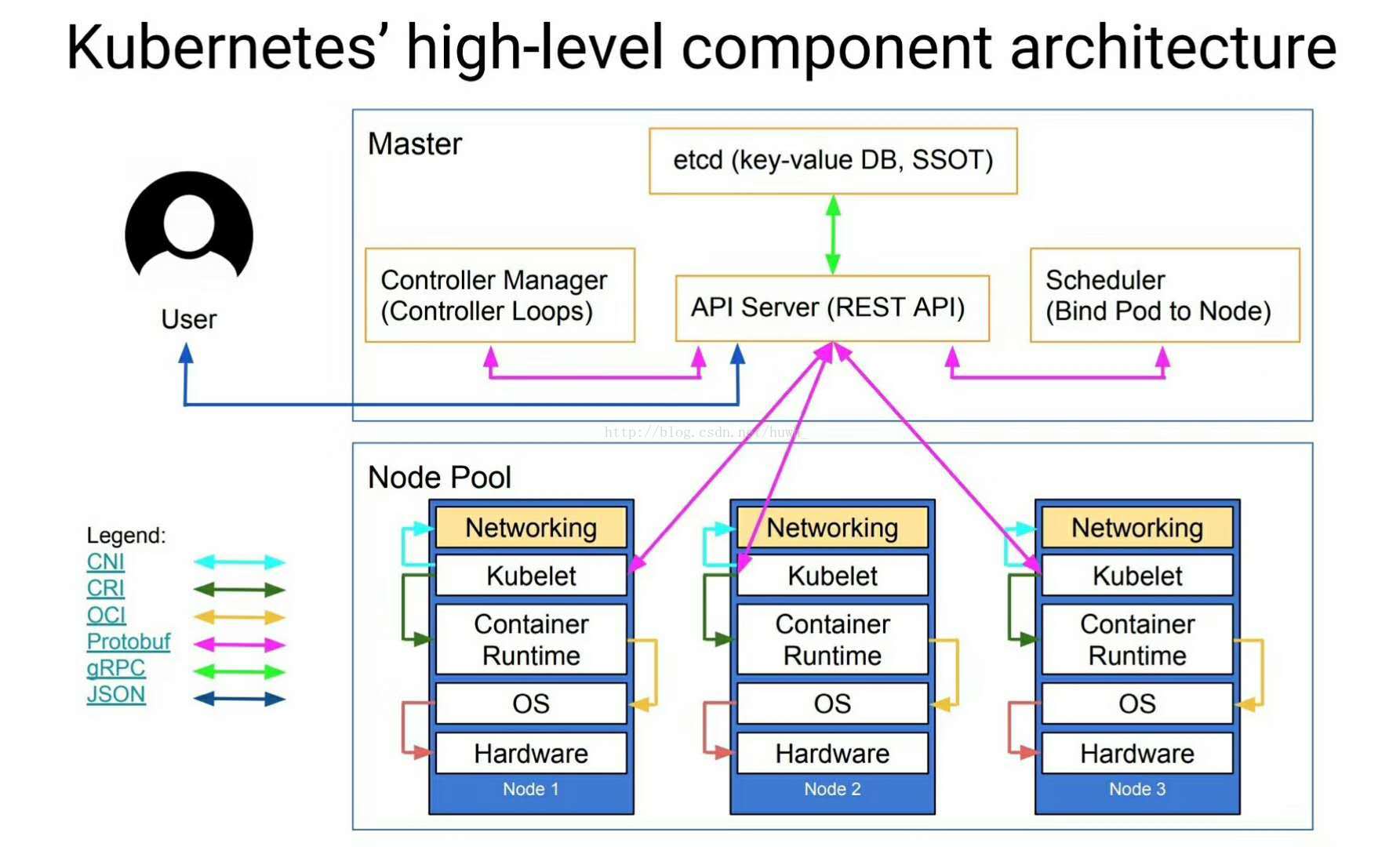
arch/images/high_level.jpg
0 → 100644
{kind=link}
128.2 KB
arch/images/layer.png
0 → 100644
{kind=link}
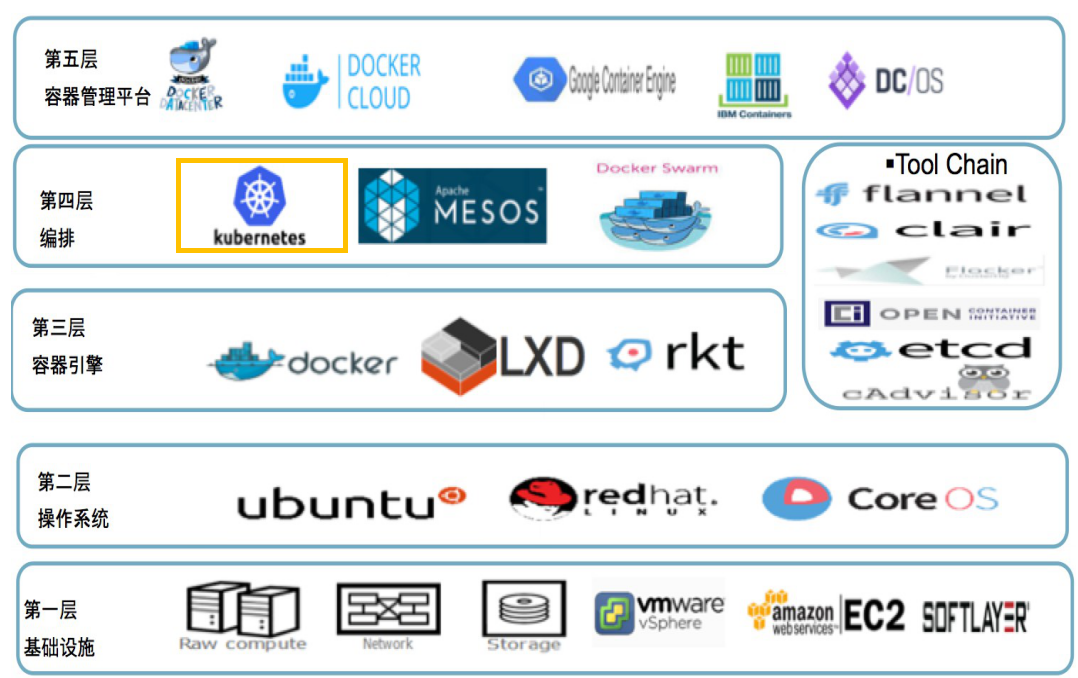
400.9 KB
arch/images/yaml2pod.png
0 → 100644
{kind=link}
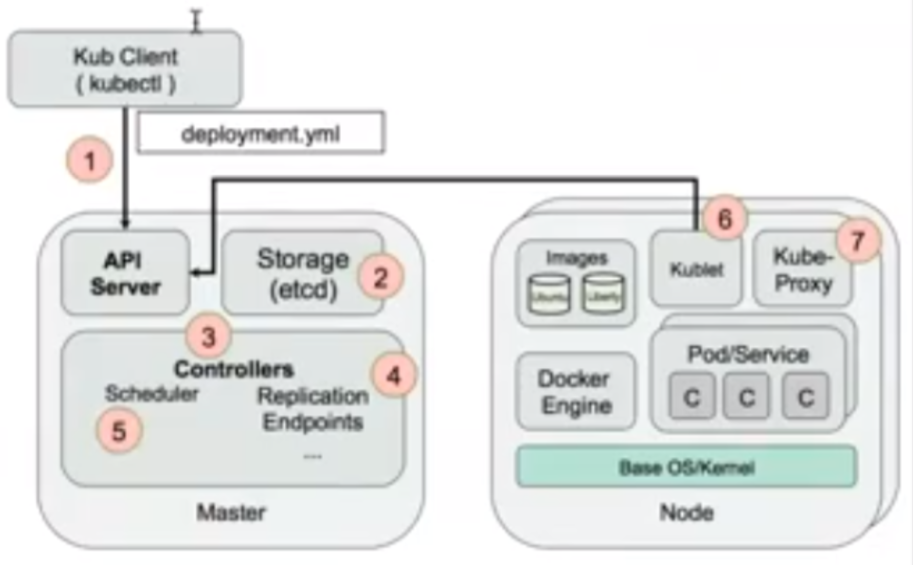
238.0 KB
arch/istio.md
0 → 100644
arch/istio/20190906310.jpg
0 → 100644
{kind=link}

23.4 KB
arch/istio/20190906311.jpg
0 → 100644
{kind=link}

17.0 KB
arch/istio/2019090632.jpg
0 → 100644
{kind=link}
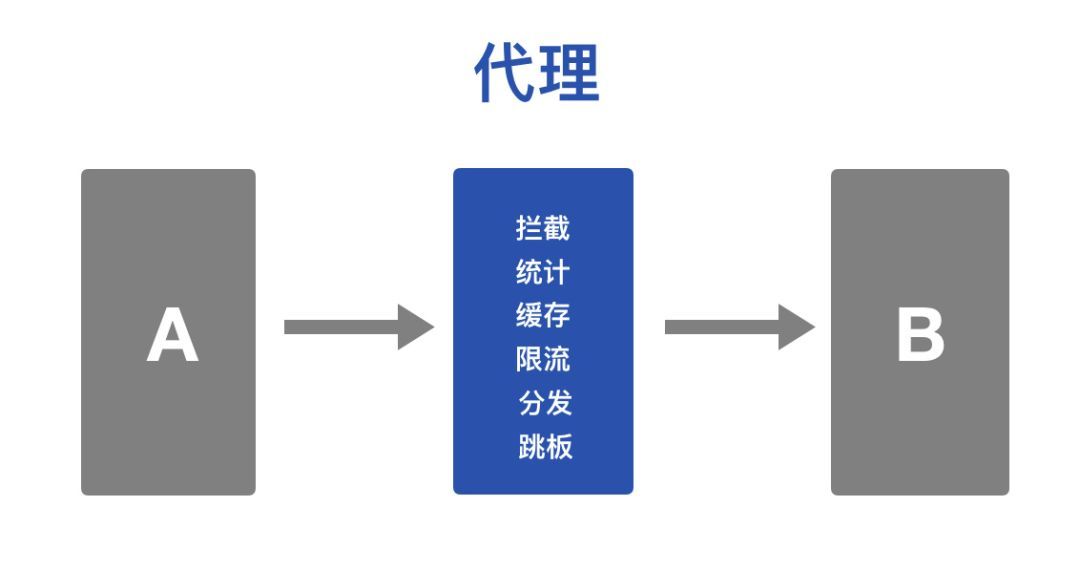
19.7 KB
arch/istio/2019090633.jpg
0 → 100644
{kind=link}
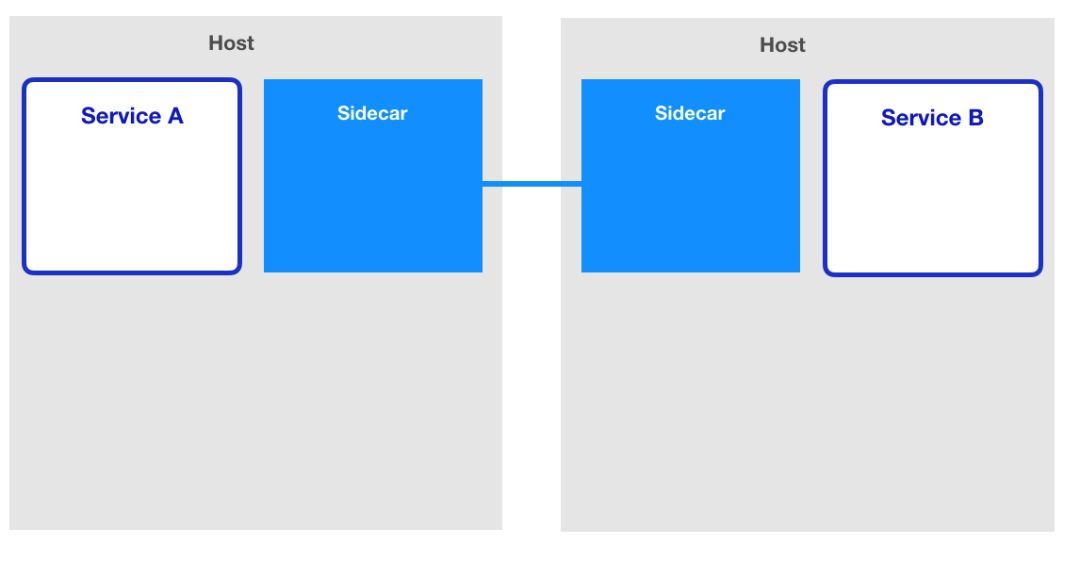
21.2 KB
arch/istio/2019090634.jpg
0 → 100644
{kind=link}

32.7 KB
arch/istio/2019090635.jpg
0 → 100644
{kind=link}
20.1 KB
arch/istio/2019090636.jpg
0 → 100644
{kind=link}
73.8 KB
arch/istio/2019090637.jpg
0 → 100644
{kind=link}
32.5 KB
arch/istio/2019090638.jpg
0 → 100644
{kind=link}

22.6 KB
arch/istio/2019090639.jpg
0 → 100644
{kind=link}

34.2 KB
arch/k8s_controller.md
0 → 100644
arch/k8s_cri.md
0 → 100644
arch/k8s_pod.md
0 → 100644
arch/k8s_scheduler.md
0 → 100644