Merge branch 'develop' into hotfix/sangshuduo/2.0doc-emq-insert
Showing
{kind=link}
43.2 KB
{kind=link}
120.2 KB
{kind=link}
74.6 KB
{kind=link}
26.0 KB
{kind=link}
43.8 KB
{kind=link}
67.4 KB
{kind=link}
96.9 KB
{kind=link}
60.3 KB
{kind=link}
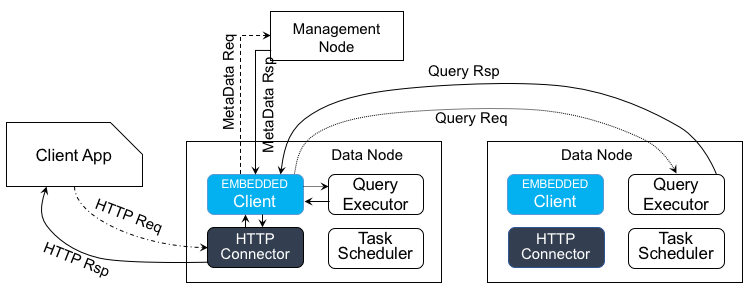
48.8 KB
{kind=link}
21.1 KB
{kind=link}
22.0 KB
{kind=link}
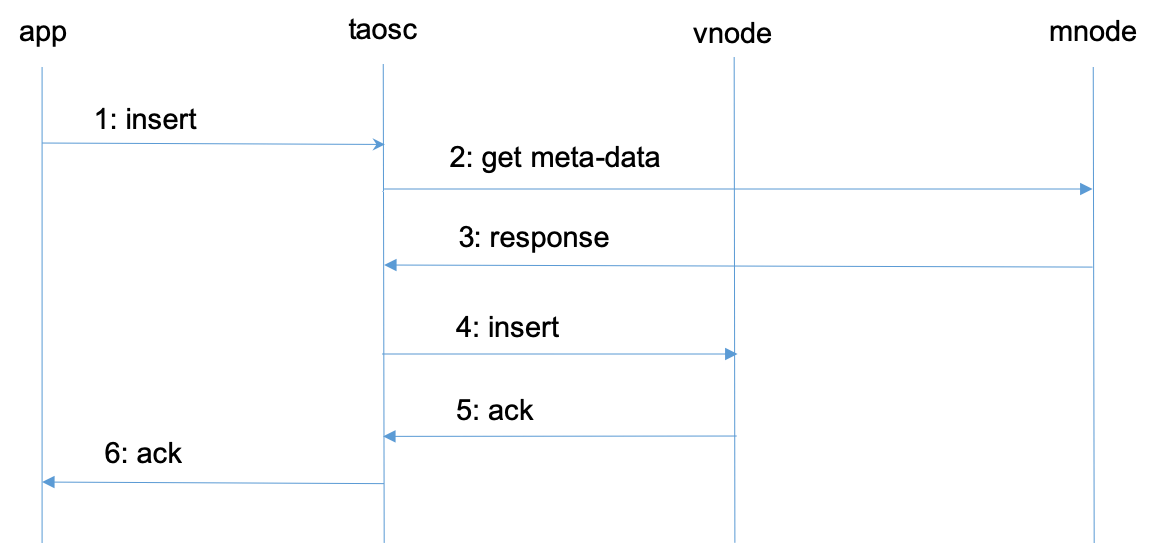
43.2 KB
{kind=link}
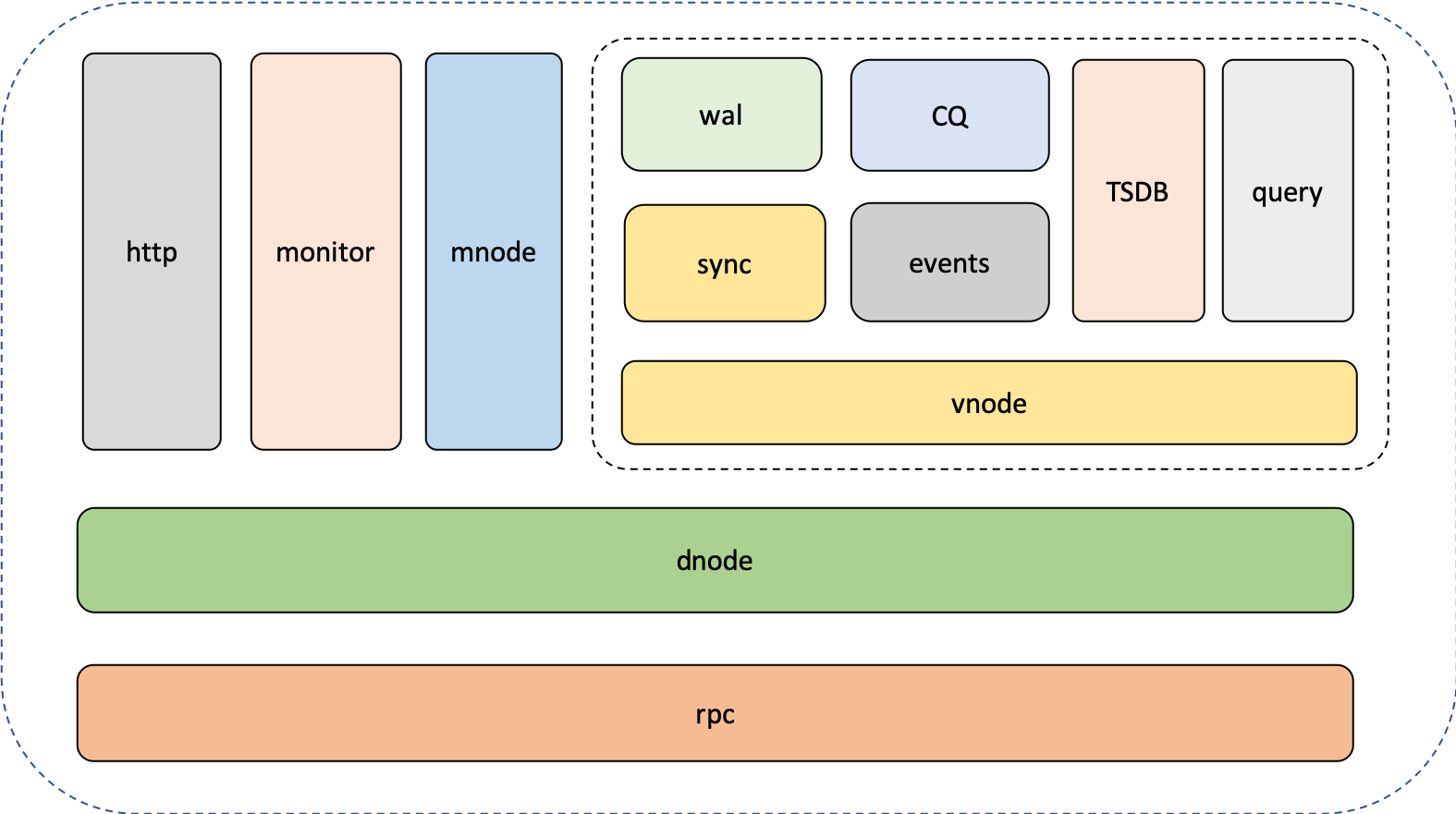
86.9 KB
{kind=link}
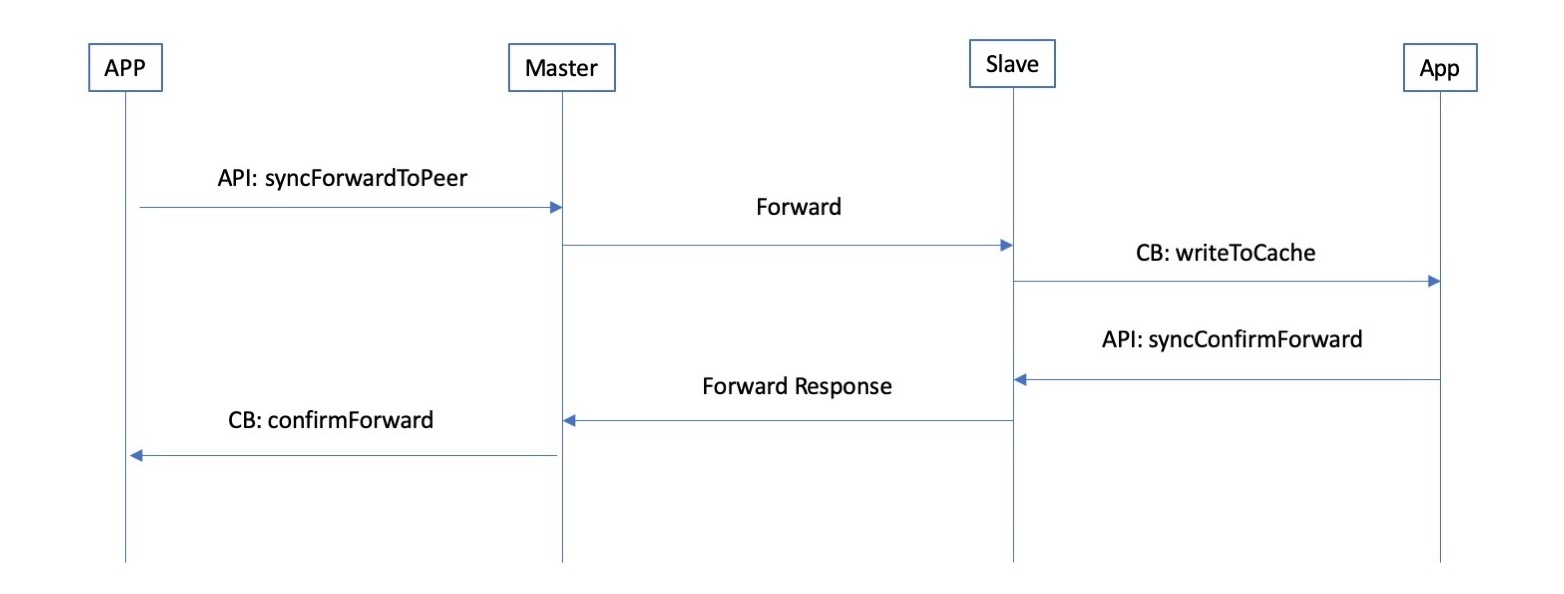
65.0 KB
{kind=link}
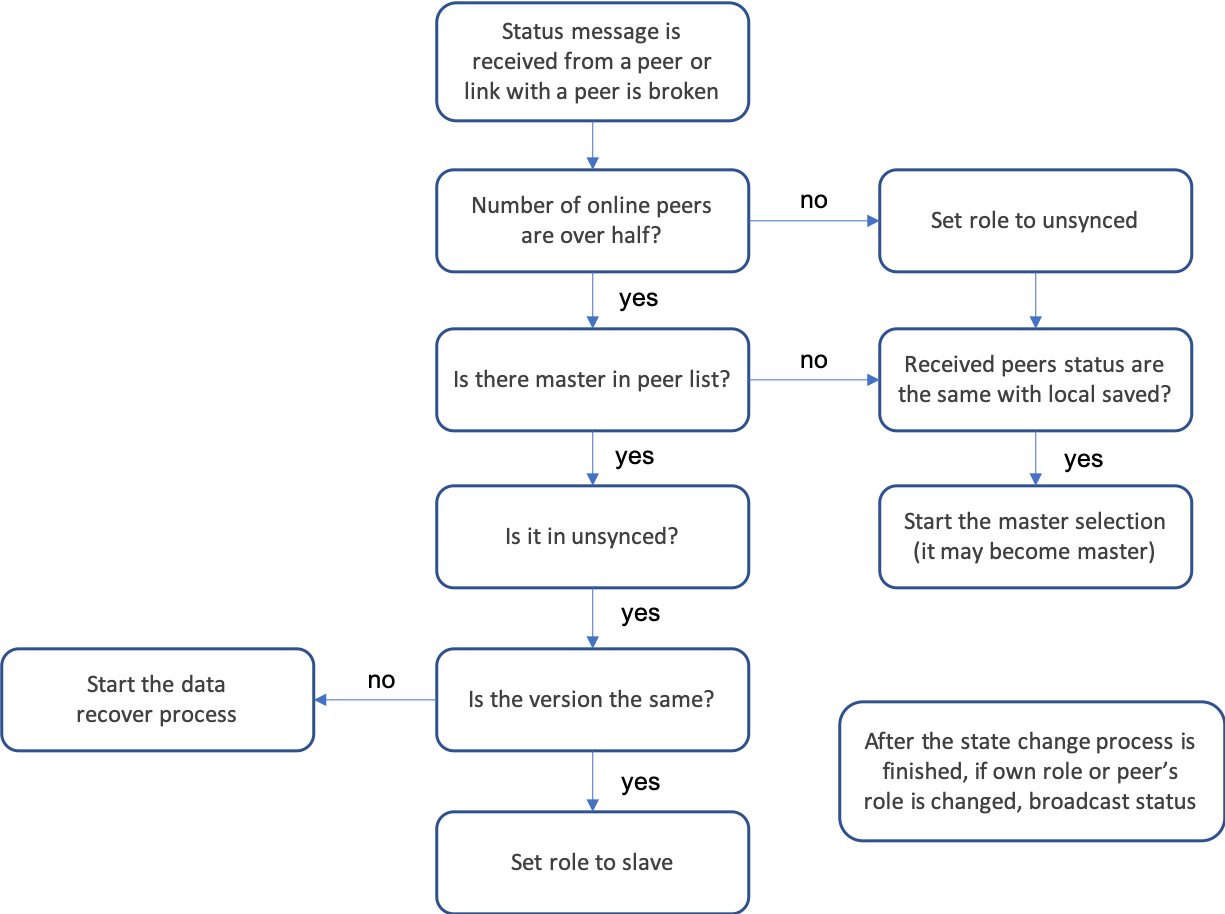
114.5 KB
{kind=link}
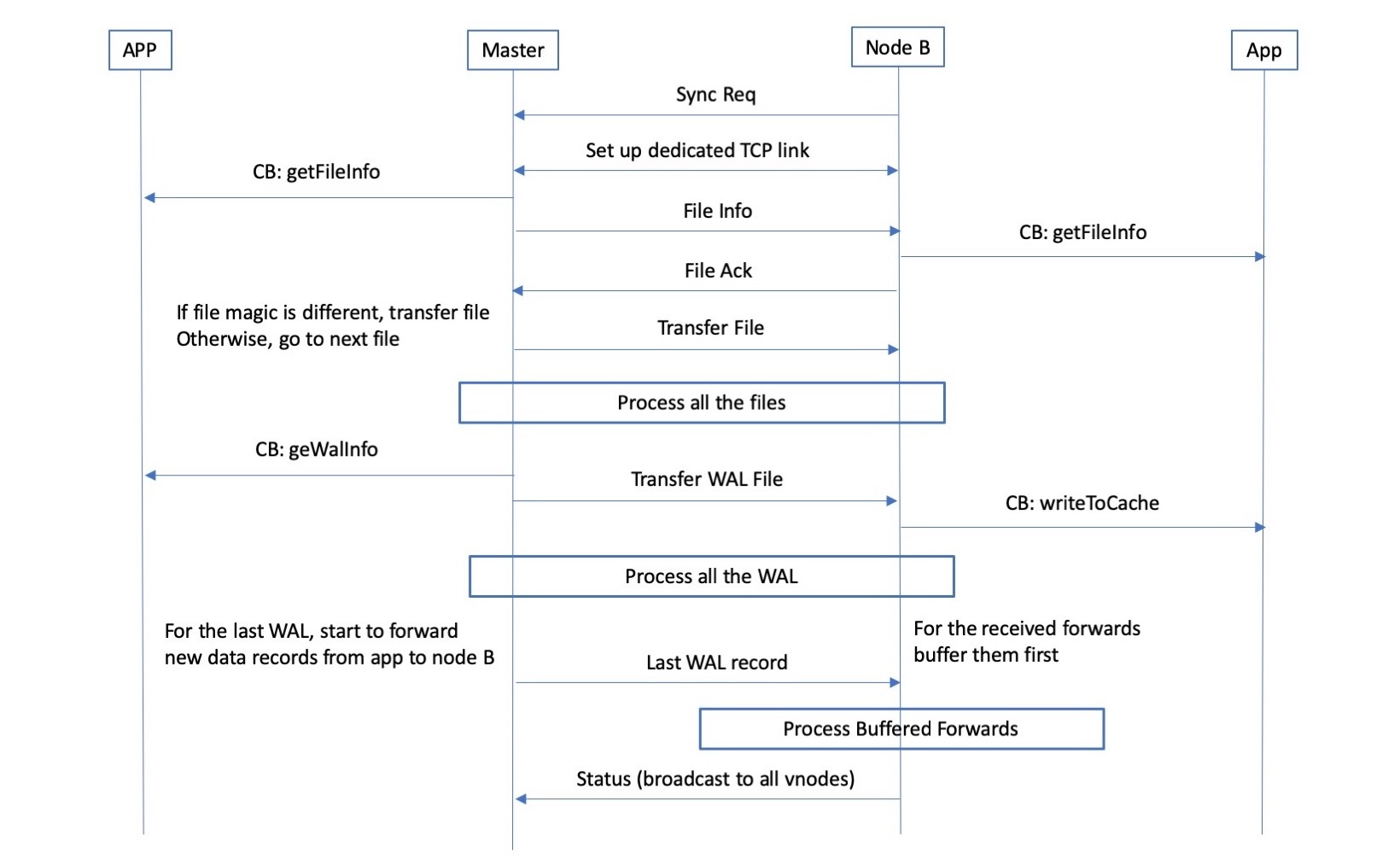
169.2 KB
{kind=link}
65.7 KB
{kind=link}
92.3 KB
{kind=link}
54.3 KB
{kind=link}
70.8 KB
{kind=link}
56.3 KB
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/os/inc/osDarwin.h
0 → 100644
此差异已折叠。
src/os/inc/osDarwin64.h
已删除
100644 → 0
此差异已折叠。
src/os/inc/osDef.h
0 → 100644
此差异已折叠。
src/os/inc/osDir.h
0 → 100644
此差异已折叠。
src/os/inc/osFile.h
0 → 100644
此差异已折叠。
src/os/inc/osLz4.h
0 → 100644
此差异已折叠。
src/os/inc/osMemory.h
0 → 100644
此差异已折叠。
src/os/inc/osRand.h
0 → 100644
此差异已折叠。
src/os/inc/osSemphone.h
0 → 100644
此差异已折叠。
src/os/inc/osSocket.h
0 → 100644
此差异已折叠。
src/os/inc/osTimer.h
0 → 100644
此差异已折叠。
src/os/inc/osWindows.h
0 → 100644
此差异已折叠。
src/os/inc/osWindows32.h
已删除
100644 → 0
此差异已折叠。
src/os/inc/osWindows64.h
已删除
100644 → 0
此差异已折叠。
src/os/src/darwin/CMakeLists.txt
0 → 100644
此差异已折叠。
src/os/src/darwin/darwinFile.c
0 → 100644
此差异已折叠。
此差异已折叠。
src/os/src/darwin/darwinSocket.c
0 → 100644
此差异已折叠。
src/os/src/darwin/darwinSysInfo.c
0 → 100644
此差异已折叠。
src/os/src/darwin/darwinTimer.c
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/os/src/detail/osFileOp.c
已删除
100644 → 0
此差异已折叠。
src/os/src/windows/CMakeLists.txt
0 → 100644
此差异已折叠。
src/os/src/windows/w64Godll.c
0 → 100644
此差异已折叠。
src/os/src/windows/w64Lz4.c
0 → 100644
此差异已折叠。
src/os/src/windows/w64Semphone.c
0 → 100644
此差异已折叠。
src/os/src/windows/w64Socket.c
0 → 100644
此差异已折叠。
src/os/src/windows/w64Sysinfo.c
0 → 100644
此差异已折叠。
src/os/src/windows/w64Wordexp.c
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。