Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
后端镜像
Python Guide
提交
b704fb5a
P
Python Guide
项目概览
后端镜像
/
Python Guide
通知
0
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python Guide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
b704fb5a
编写于
12月 13, 2020
作者:
写代码的明哥
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update
上级
d9312bb3
变更
14
展开全部
隐藏空白更改
内联
并排
Showing
14 changed file
with
2057 addition
and
2006 deletion
+2057
-2006
source/c07/c07_01.md
source/c07/c07_01.md
+22
-0
source/c07/c07_01.rst
source/c07/c07_01.rst
+24
-0
source/c07/c07_04.md
source/c07/c07_04.md
+40
-6
source/c07/c07_04.rst
source/c07/c07_04.rst
+45
-7
source/c07/c07_05.md
source/c07/c07_05.md
+139
-489
source/c07/c07_05.rst
source/c07/c07_05.rst
+159
-551
source/c07/c07_06.md
source/c07/c07_06.md
+44
-0
source/c07/c07_06.rst
source/c07/c07_06.rst
+34
-98
source/c07/c07_07.md
source/c07/c07_07.md
+4
-4
source/c07/c07_07.rst
source/c07/c07_07.rst
+4
-2
source/c07/c07_08.md
source/c07/c07_08.md
+262
-164
source/c07/c07_08.rst
source/c07/c07_08.rst
+277
-186
source/c07/c07_09.md
source/c07/c07_09.md
+473
-243
source/c07/c07_09.rst
source/c07/c07_09.rst
+530
-256
未找到文件。
source/c07/c07_01.md
浏览文件 @
b704fb5a
...
...
@@ -38,6 +38,28 @@ class Animal:
-
`self.name`
是实例属性,
`age`
是类属性
-
`run`
是方法,第一个参数 self 是什么意思呢?这个咱后面再讲。
除了上面这种写法外
```
python
# 第一种写法
class
Animal
:
...
```
还有另外两种写法,与之是等价的
```
python
# 第二种写法
class
Animal
():
...
# 第二种写法
class
Animal
(
object
):
...
```
因为在 Python 3 中,无论你是否显示继承自 object,Python 解释器都会默认你继承 object ,这是新式类的写法,与之对应的是 Python 2 的经典类写法(Python 2 已经远去,无需要再了解经典类写法)。
## 3. 如何实例化?
定义了类之后,就可以通过下边的写法实例化它,并访问属性,调用方法
...
...
source/c07/c07_01.rst
浏览文件 @
b704fb5a
...
...
@@ -42,6 +42,30 @@ class),是具有相同特性(属性)和行为(方法)的对象(实
- ``self.name`` 是实例属性,\ ``age`` 是类属性
- ``run`` 是方法,第一个参数 self 是什么意思呢?这个咱后面再讲。
除了上面这种写法外
.. code:: python
# 第一种写法
class Animal:
...
还有另外两种写法,与之是等价的
.. code:: python
# 第二种写法
class Animal():
...
# 第二种写法
class Animal(object):
...
因为在 Python 3 中,无论你是否显示继承自 object,Python
解释器都会默认你继承 object ,这是新式类的写法,与之对应的是 Python 2
的经典类写法(Python 2 已经远去,无需要再了解经典类写法)。
3. 如何实例化?
---------------
...
...
source/c07/c07_04.md
浏览文件 @
b704fb5a
# 7.4
封装、继承和多态
# 7.4
类的封装(Encapsulation)
面向对象编程有三大重要特征:封装、继承和多态
。
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现
。
## 封装(Encapsulation)
要了解封装,离不开“私有化”,就是将类或者是函数中的某些属性限制在某个区域之内,外部无法直接调用。
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现。
关于什么是
`私有化变量和私有化函数`
,在上一节我已经很详细的讲过啦。
私有变量和私有方法,虽然有办法访问,但是仍然不建议使用上面给出的方法直接访问,而应该接口统一的接口(函数入口)来对私有变量进行查看、变量,对私有方法进行调用。这就是封装。
正是由于封装机制,程序在使用某一对象时不需要关心该对象的数据结构细节及实现操作的方法。使用封装能隐藏对象实现细节,使代码更易维护,同时因为不能直接调用、修改对象内部的私有信息,在一定程度上保证了系统安全性。类通过将函数和变量封装在内部,实现了比函数更高一级的封装。
要了解封装,离不开“私有化”,就是将类或者是函数中的某些属性限制在某个区域之内,外部无法调用。
请看下面这段代码
```
python
class
Person
:
def
__init__
(
self
,
name
,
age
):
self
.
name
=
name
self
.
age
=
age
xh
=
Person
(
name
=
"小红"
,
age
=
27
)
if
xh
.
age
>=
18
:
print
(
f
"
{
xh
.
name
}
已经是成年人了"
)
else
:
print
(
f
"
{
xh
.
name
}
还是未年人"
)
```
我定义了一个 Person 的类,它有 name 和 age 两个属性。
如果想判断小明是不是成年人,需要使用
`xh.age`
来与 18 比较。
对于很多女生还来说,年龄是非常隐私的。如果不想年龄被人随意就获取,可以在
`age`
前加两个下划线,将其变成一个私有变量。外界就无法随随便便就知道某个人年龄啦。
如此一来,想要知道一个人是否是成年人,该怎么办呢?
这时候,就该
`封装`
出场啦。
我可以定义一个用于专门判断一个人是否成年人的函数,对
`self.__age`
这个属性进行封装。
```
python
class
Person
:
def
__init__
(
self
,
name
,
age
):
self
.
name
=
name
self
.
__age
=
age
def
is_adult
(
self
):
return
self
.
__age
>=
18
xh
=
Person
(
name
=
"小红"
,
age
=
27
)
xh
.
is_adult
()
```
source/c07/c07_04.rst
浏览文件 @
b704fb5a
7.4
封装、继承和多态
====================
7.4
类的封装(Encapsulation)
====================
=========
面向对象编程有三大重要特征:封装、继承和多态
。
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现
。
封装(Encapsulation)
---------------------
要了解封装,离不开“私有化”,就是将类或者是函数中的某些属性限制在某个区域之内,外部无法直接调用。
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现。
关于什么是 ``私有化变量和私有化函数``\ ,在上一节我已经很详细的讲过啦。
私有变量和私有方法,虽然有办法访问,但是仍然不建议使用上面给出的方法直接访问,而应该接口统一的接口(函数入口)来对私有变量进行查看、变量,对私有方法进行调用。这就是封装。
正是由于封装机制,程序在使用某一对象时不需要关心该对象的数据结构细节及实现操作的方法。使用封装能隐藏对象实现细节,使代码更易维护,同时因为不能直接调用、修改对象内部的私有信息,在一定程度上保证了系统安全性。类通过将函数和变量封装在内部,实现了比函数更高一级的封装。
要了解封装,离不开“私有化”,就是将类或者是函数中的某些属性限制在某个区域之内,外部无法调用。
请看下面这段代码
.. code:: python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
xh = Person(name="小红", age=27)
if xh.age >= 18:
print(f"{xh.name}已经是成年人了")
else:
print(f"{xh.name}还是未年人")
我定义了一个 Person 的类,它有 name 和 age 两个属性。
如果想判断小明是不是成年人,需要使用 ``xh.age`` 来与 18 比较。
对于很多女生还来说,年龄是非常隐私的。如果不想年龄被人随意就获取,可以在
``age``
前加两个下划线,将其变成一个私有变量。外界就无法随随便便就知道某个人年龄啦。
如此一来,想要知道一个人是否是成年人,该怎么办呢?
这时候,就该 ``封装`` 出场啦。
我可以定义一个用于专门判断一个人是否成年人的函数,对 ``self.__age``
这个属性进行封装。
.. code:: python
class Person:
def __init__(self, name, age):
self.name = name
self.__age = age
def is_adult(self):
return self.__age >= 18
xh = Person(name="小红", age=27)
xh.is_adult()
source/c07/c07_05.md
浏览文件 @
b704fb5a
此差异已折叠。
点击以展开。
source/c07/c07_05.rst
浏览文件 @
b704fb5a
此差异已折叠。
点击以展开。
source/c07/c07_06.md
0 → 100644
浏览文件 @
b704fb5a
# 7.6 类的多态(Polymorphism)
多态,是指在同一类型下的不同形态。
比如下面这段代码
```
python
class
People
:
def
speak
(
self
):
pass
class
American
(
People
):
def
speak
(
self
):
print
(
"Hello, boys"
)
class
Chinese
(
People
):
def
speak
(
self
):
print
(
"你好,老铁"
)
p1
=
American
()
p2
=
Chinese
()
```
American 和 Chinese 都继承了 People 类,但他们在
`speak()`
函数下,却有不同的形态表现。American 说英文,Chinese 说汉语。
倘若现在有一个
`do_speak`
函数
```
python
def
do_speak
(
people
):
people
.
speak
()
do_speak
(
p1
)
do_speak
(
p2
)
```
那么无论传入的 American 实例还是 Chinese 实例,只要他有实现 speak 方法都可以。
这就是 Python 中非常有名鸭子类型:
**一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。**
套入刚刚的代码实例中,就是一个对象,只要有 speak 方法,那么他就是一个
`do_speak`
方法所需要的 people 对象。
可能有人会觉得,这些内容很自然啊,没什么不好理解,不觉得多态有什么特殊,Python就是这样啊!
如果你学过 JAVA 这一类强类型静态语言,就不会这么觉得了,对于JAVA,必须指定函数参数的数据类型,只能传递对应参数类型或其子类型的参数,不能传递其它类型的参数,show_kind()函数只能接收animal、dog、cat和pig类型,而不能接收job类型。就算接收dog、cat和pig类型,也是通过面向对象的多态机制实现的。
\ No newline at end of file
source/c07/c07_06.rst
浏览文件 @
b704fb5a
7.6
静态方法其实暗藏玄机
========================
7.6
类的多态(Polymorphism)
========================
====
静态方法,应该没人不知道吧?它可以算是一个很基础、简单的知识点
。
多态,是指在同一类型下的不同形态
。
但是就是这样一个知识点,也有不少可以探究的东西。
比如下面这段代码
不信我问你三个问题,你看能否答上来。
.. code:: python
1. Python2.x和3.x中,函数和方法的区分有什么不同?
2. 有了类/实例方法和普通函数,为什么还会有静态方法?
3. Python3.x 中,静态方法有几种写法?
class People:
def speak(self):
pass
如果你没能答上来,那你可以尝试在下文中寻找答案。
class American(People):
def speak(self):
print("Hello, boys")
--------------
class Chinese(People):
def speak(self):
print("你好,老铁")
p1 = American()
p2 = Chinese()
在 Python 2 中的函数和方法的区别,十分清晰,很好分辨。但在
Python3中,我却发现完全又是另一套准则
。
American 和 Chinese 都继承了 People 类,但他们在 ``speak()``
函数下,却有不同的形态表现。American 说英文,Chinese 说汉语
。
首先先来 Python2 的(以下在 Python2.7中测试通过)
倘若现在有一个 ``do_speak`` 函数
|image0|
.. code:: python
可以得出结论:
def do_speak(people):
people.speak()
1、普通函数(未定位在类里),都是函数。
do_speak(p1)
do_speak(p2)
2、静态方法(@staticmethod),都是函数。
那么无论传入的 American 实例还是 Chinese 实例,只要他有实现 speak
方法都可以。
3、类方法(@classmethod),都是方法。
这就是 Python
中非常有名鸭子类型:\ **一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。**
4、实例方法(首参数为self且非静态、非类方法的),都是方法。
套入刚刚的代码实例中,就是一个对象,只要有 speak 方法,那么他就是一个
``do_speak`` 方法所需要的 people 对象。
你一定想说,类方法和实例方法,是方法没错呀,毕竟名字本身就有方法,普通函数是函数,我也理解呀。那静态方法,为什么不是方法而是函数呢?
名字只是一个外在的表面称呼,你能说「赵铁男」就一定是汉子吗?
我的理解是:方法是一种和对象(实例或者类)绑定后的函数。
类方法的首参是\ ``cls``\ ,调用时,无需显示传入。实例方法首参是self,调用时,也无需显示传入。
而静态方法,其实和普通函数没啥区别,唯一的区别就是,他定义的位置被放在了类里,做为类或者实例的一个函数。
那你肯定又要问了,既然静态方法和普通函数都是一样的,为什么要刻意将它放在类里呢?
我上面说了,放在类里定义,就可以让它成为类的一个工具函数,这就像你身上随身携带了一把刀,这把刀与你本人并没有什么直接关系,唯一的联系就是这把刀是你的,而你把它带在身上,无论你去到哪里,只要需要,你就可以直接拿出来用上。对比将函数放在类外面,缺点是什么呢?就是当你出门在外(在别的模块里)发现你要用刀的时候,还要特地跑一趟去商店买一把刀(import
这个函数)。
另外,我觉得静态方法在业务和设计上的意义,会更多一些。
一般静态方法是做为类或者实例的一个工具函数,比如对变量的做一个合法性的检验,对数据进行序列化反序列化操作等等。
说完了 Python2 ,再来说说Python3.
以前我觉得 Python2 对于方法和函数的界线更加清晰,但接触了
Python3,我反而觉得Python3里方法和函数的区分似乎更加合理。
还是刚刚那段代码,我更改了解释器为Python3.6(以下在
Python3.6中测试通过)
|image1|
和Python2的唯一区别是,\ ``People.jump`` 在Python3 中变成了函数。
这一下颠覆了你刚刚才建立起来的知识体系有木有?
先别急,我再做个试验,也许你就知道了。
**在 Python2中**
执行People.jump(‘hello’),会报错说,jump的首参必须为People的实例对象,这可以理解,毕竟jump定义时,第一个参数为self。
|image2|
**在 Python3中**
你可以发现,这里的jump的首参不再要求是 People
的一个实例,而可以是任意的对象,比如我使用字符串对象,也没有报错。
|image3|
也就是说,当你往jump中传入的首参为People的实例时,jump
就是方法,而当你传入的首参不是People的实例对象时,jump就是函数。
你看,多么灵活呀。
再总结一下,在Python3中:
1、普通函数(未定位在类里),都是函数。
2、静态方法(@staticmethod),都是函数。
3、类方法(@classmethod),都是方法。
4、方法和函数区分没有那么明确,而是更加灵活了,一个函数有可能是方法也有可能是函数。
你肯定又要问了,那这是不是就意味着,Python3
中静态方法,可以不用再使用@staticmethod
装饰了呢,反正Python3都可以识别。
这是个好问题,是的,可以不用指定,但是最好指定,如果你不指定,你调用这个方法只能通过People.jump,而不能通过
self.jump了,因为首参不是 self,而如果使用@staticmethod
就可以使用self.jump。
所以说这是一个规范,就像类的私有方法,规范要求外部最好不要调用,但这不是强制要求,不是说外部就不能调用。
写这篇文章的起源,是前两天有位读者在交流里问到了相关的问题,正好没什么主题可以写,就拿过来做为素材整理一下,也正好没有写过静态方法、类方法的内容,没想到简单的东西,也能写出这么多的内容出来。
.. |image0| image:: http://image.iswbm.com/20190630111243.png
.. |image1| image:: http://image.iswbm.com/20190630104956.png
.. |image2| image:: http://image.iswbm.com/20190630105735.png
.. |image3| image:: http://image.iswbm.com/20190630105600.png
可能有人会觉得,这些内容很自然啊,没什么不好理解,不觉得多态有什么特殊,Python就是这样啊!
如果你学过 JAVA
这一类强类型静态语言,就不会这么觉得了,对于JAVA,必须指定函数参数的数据类型,只能传递对应参数类型或其子类型的参数,不能传递其它类型的参数,show_kind()函数只能接收animal、dog、cat和pig类型,而不能接收job类型。就算接收dog、cat和pig类型,也是通过面向对象的多态机制实现的。
source/c07/c07_07.md
浏览文件 @
b704fb5a
# 7.3 多继承和 Mixin 设计模式
类的单继承,是我们再熟悉不过的,写起来也毫不费力。而多继承呢,见得很多,写得很少。在很多的项目代码里,你还会见到一种很奇怪的类,他们有一个命名上的共同点,就是在类名的结尾,都喜欢用 Mixin。
类的单继承,是开发者再熟悉不过的继承方式,写起来也毫不费力。
而多继承呢,见得很多,写得很少。在很多的项目代码里,你还会见到一种很奇怪的类,他们有一个命名上的共同点,就是在类名的结尾,都喜欢用 Mixin。
## 1. 认识Mixin模式
...
...
@@ -18,7 +20,7 @@
举个例子
```
```
python
class
Vehicle
(
object
):
pass
...
...
@@ -36,8 +38,6 @@ class Airplane(Vehicle, PlaneMixin):
-
功能单一:若有多个功能,那就写多个Mixin类;
-
绝对独立:不能依赖于子类的实现;子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。
## 2. 不使用Mixin的弊端
你肯定会问,不使用 Mixin 行吗?
...
...
source/c07/c07_07.rst
浏览文件 @
b704fb5a
7.3 多继承和 Mixin 设计模式
===========================
类的单继承,是我们再熟悉不过的,写起来也毫不费力。而多继承呢,见得很多,写得很少。在很多的项目代码里,你还会见到一种很奇怪的类,他们有一个命名上的共同点,就是在类名的结尾,都喜欢用
类的单继承,是开发者再熟悉不过的继承方式,写起来也毫不费力。
而多继承呢,见得很多,写得很少。在很多的项目代码里,你还会见到一种很奇怪的类,他们有一个命名上的共同点,就是在类名的结尾,都喜欢用
Mixin。
1. 认识Mixin模式
...
...
@@ -26,7 +28,7 @@ Mixin 类,一般都要求开发者遵循规范,在类名末尾加上 Mixin
举个例子
::
.. code:: python
class Vehicle(object):
pass
...
...
source/c07/c07_08.md
浏览文件 @
b704fb5a
# 7.
2 经典类与新式类
# 7.
8 理解元类编程
##
1. 版本支持 / 写法差异
##
1. 类是如何产生的
在Python 2.x 中
类是如何产生?
如果你至今使用的还是 Python 2.x,那么你需要了解一下,在Python 2.x中存在着两种类:经典类和新式类
。
这个问题肯定很傻。实则不然,很多初学者只知道使用继承的表面形式来创建一个类,却不知道其内部真正的创建是由type来创建的
。
什么是经典类
?
type?这不是判断对象类型的函数吗
?
```
# 不继承自object
class Ming:
pass
是的,type通常用法就是用来判断对象的类型。但除此之外,他最大的用途是用来动态创建类。当Python扫描到class的语法的时候,就会调用type函数进行类的创建。
什么是新式类?
# 显示继承object
class Ming(object):
pass
```
## 2. 如何使用type创建类
在Python 3.x 中
首先,type()需要接收三个参数
如果你已经摒弃了Python 2.x,而已经完全投入了Python 3.x的怀抱,那你可能不需要关心,因为在Python3.x中所有的类都是新式类(所有类都(显示/隐式)继承自object)。
1.
类的名称,若不指定,也要传入空字符串:
`""`
2.
父类,注意以tuple的形式传入,若没有父类也要传入空tuple:(),默认继承object
3.
绑定的方法或属性,注意以dict的形式传入
有如下三种写法,它们是等价的。
来看个例子
```
class Ming:
pass
```
python
# 准备一个基类(父类)
class
BaseClass
:
def
talk
(
self
):
print
(
"i am people"
)
class Ming():
pass
# 准备一个方法
def
say
(
self
):
print
(
"hello"
)
class Ming(object):
pass
# 使用type来创建User类
User
=
type
(
"User"
,
(
BaseClass
,
),
{
"name"
:
"user"
,
"say"
:
say
})
```
##
2. 使用方法 / 独特属性
##
3. 理解什么是元类
经典类无法使用super()
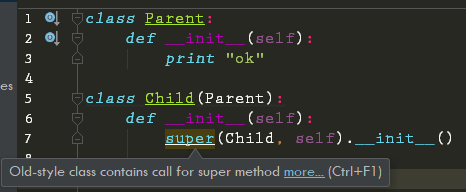
经典类的类型是 classobj

什么是类?可能谁都知道,类就是用来创建对象的「模板」。
新式类的类型是 type,保持class与type的统一
。
那什么是元类呢?一句话通俗来说,元类就是创建类的「模板」
。
新式类增加了
\_
_slots\__
内置属性, 可以把实例属性的种类锁定到
\_
_slots\__
规定的范围之中.
新式类增加了
\_
_getattribute\__
方法,在获取属性时可以进入此方法。而经典类不会。
为什么type能用来创建类?因为它本身是一个元类。使用元类创建类,那就合理了。
```
# 经典类:py2.7
class Kls01:
def __getattribute__(self, *args, **kwargs):
print("MING - 01")
type是Python在背后用来创建所有类的元类,我们熟知的类的始祖
`object`
也是由type创建的。更有甚者,连type自己也是由type自己创建的,这就过份了。
# 新式类
class Kls02(object):
def __getattribute__(self, *args, **kwargs):
print("MING - 02")
```
python
>>>
type
(
type
)
<
class
'
type
'>
kls02 = Kls02(
)
kls02.name
>>> type(object
)
<class '
type
'>
kls01 = Kls01()
kls01.name
```
>>> type(int)
<class '
type
'>
输出如下
>>> type(str)
<class '
type
'>
```
如果要形象的来理解的话,就看下面这三行话。
-
str:用来创建字符串对象的类。
-
int:是用来创建整数对象的类。
-
type:是用来创建类对象的类。
反过来看
-
一个实例的类型,是类
-
一个类的类型,是元类
-
一个元类的类型,是type
写个简单的小示例来验证下
```
python
>>>
class
MetaPerson
(
type
):
...
pass
...
>>>
class
Person
(
metaclass
=
MetaPerson
):
...
pass
...
>>>
Tom
=
Person
()
>>>
print
(
type
(
Tom
))
<
class
'
__main__
.
Person
'>
>>> print(type(Tom.__class__))
<class '
__main__
.
MetaPerson
'>
>>> print(type(Tom.__class__.__class__))
<class '
type
'>
```
MING - 02
Traceback (most recent call last):
File "F:/Python Script/Tornado/yang.py", line 13, in <module>
kls01.name
AttributeError: Kls01 instance has no attribute 'name'
下面再来看一个稍微完整的
```
python
# 注意要从type继承
class
BaseClass
(
type
):
def
__new__
(
cls
,
*
args
,
**
kwargs
):
print
(
"in BaseClass"
)
return
super
().
__new__
(
cls
,
*
args
,
**
kwargs
)
class
User
(
metaclass
=
BaseClass
):
def
__init__
(
self
,
name
):
print
(
"in User"
)
self
.
name
=
name
# in BaseClass
user
=
User
(
"wangbm"
)
# in User
```
综上,我们知道了类是元类的实例,所以在创建一个普通类时,其实会走元类的
`__new__`
。
同时,我们又知道在类里实现了
`__call__`
就可以让这个类的实例变成可调用。
## 3. MRO 查找算法的演变
所以在我们对普通类进行实例化时,实际是对一个元类的实例(也就是普通类)进行直接调用,所以会走进元类的
`__call__`
**经典类中**
在这里可以借助 「单例的实现」举一个例子,你就清楚了
经典类,MRO采用的是
`深度优先`
算法。
```
python
class
MetaSingleton
(
type
):
def
__call__
(
cls
,
*
args
,
**
kwargs
):
print
(
"cls:{}"
.
format
(
cls
.
__name__
))
print
(
"====1===="
)
if
not
hasattr
(
cls
,
"_instance"
):
print
(
"====2===="
)
cls
.
_instance
=
type
.
__call__
(
cls
,
*
args
,
**
kwargs
)
return
cls
.
_instance
为了验证,这个继承顺序。在 Python2.x 中可以借助自带模块 inspect 来检验。
class
User
(
metaclass
=
MetaSingleton
):
def
__init__
(
self
,
*
args
,
**
kw
):
print
(
"====3===="
)
for
k
,
v
in
kw
:
setattr
(
self
,
k
,
v
)
```
验证结果
```
python
>>>
u1
=
User
(
'wangbm1'
)
cls
:
User
====
1
====
====
2
====
====
3
====
>>>
u1
.
age
=
20
>>>
u2
=
User
(
'wangbm2'
)
cls
:
User
====
1
====
>>>
u2
.
age
20
>>>
u1
is
u2
True
```
import inspect
class A:pass
class B(A):pass
class C(A):pass
class D(B, C):pass
print inspect.getmro(D)
```
输出如下,可以看出,继承顺序是 D -> B -> A -> C
## 4. 使用元类的意义
```
(<class __main__.D at 0x0000000005836A08>,
<class __main__.B at 0x0000000005836768>,
<class __main__.A at 0x00000000058368E8>,
<class __main__.C at 0x0000000005836AC8>)
```
正常情况下,我们都不会使用到元类。但是这并不意味着,它不重要。假如某一天,我们需要写一个框架,很有可能就需要你对元类要有进一步的研究。
非常好理解,但是在菱形继承时,方法的调用会出现问题。
元类有啥用,用我通俗的理解,元类的作用过程:
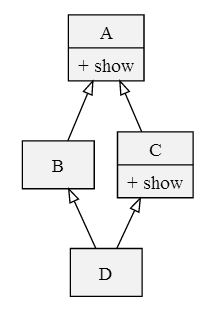
1.
拦截类的创建
2.
拦截下后,进行修改
3.
修改完后,返回修改后的类
假设 d 是 D 的一个实例,那么执行 d.show()是调用 A.show() 呢 还是调用 C.show()呢
?
所以,很明显,为什么要用它呢?不要它会怎样
?
在经典类中,由于是深度优先,所以是会选择 A.show()。但是很明显,C.show() 是 A.show() 的更具体化版本(显示了更多的信息),但我们的x.show() 没有调用它,而是调用了 A.show(),这显然是不合理的。所以这才有了后来的一步一步优化
。
使用元类,是要对类进行定制修改。使用元类来动态生成元类的实例,而99%的开发人员是不需要动态修改类的,因为这应该是框架才需要考虑的事
。
**新式类中**
但是,这样说,你一定不会服气,到底元类用来干什么?其实元类的作用就是
`创建API`
,一个最典型的应用是
`Django ORM`
。
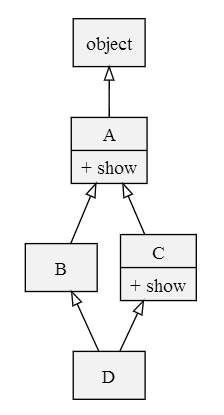
为解决经典类 MRO 所存在的问题,Python 2.2 针对新式类提出了一种新的 MRO 计算方式:在定义类时就计算出该类的 MRO 并将其作为类的属性。
## 5. 元类实战:ORM
Python 2.2 的新式类 MRO 计算方式和经典类 MRO 的计算方式非常相似:它仍然采用从左至右的深度优先遍历,但是如果遍历中出现重复的类,只保留最后一个。重新考虑上面「菱形继承」的例子:
使用过Django ORM的人都知道,有了ORM,使得我们操作数据库,变得异常简单。
ORM的一个类(User),就对应数据库中的一张表。id,name,email,password 就是字段。
同样地,我们也来验证一下。另说明,在新式类中,除用inspect外,可以直接通过__mro__属性获取类的 MRO。
```
python
class
User
(
BaseModel
):
id
=
IntField
(
'id'
)
name
=
StrField
(
'username'
)
email
=
StrField
(
'email'
)
password
=
StrField
(
'password'
)
class
Meta
:
db_table
=
"user"
```
import inspect
class A(object):pass
class B(A):pass
class C(A):pass
class D(B, C):pass
如果我们要插入一条数据,我们只需这样做
# 或者通过 D.__mro__ 查找
print inspect.getmro(D)
```
python
# 实例化成一条记录
u
=
User
(
id
=
20180424
,
name
=
"xiaoming"
,
email
=
"xiaoming@163.com"
,
password
=
"abc123"
)
# 保存这条记录
u
.
save
()
```
输出如下,可以看出,继承顺序变成了 D -> B -> C -> A
通常用户层面,只需要懂应用,就像上面这样操作就可以了。
```
(<class '__main__.D'>,
<class '__main__.B'>,
<class '__main__.C'>,
<class '__main__.A'>,
<type 'object'>)
```
但是今天我并不是来教大家如何使用ORM,我们是用来探究ORM内部究竟是如何实现的。我们也可以自己写一个简易的ORM。
这下,菱形问题解决了
。
从上面的
`User`
类中,我们看到
`StrField`
和
`IntField`
,从字段意思上看,我们很容易看出这代表两个字段类型。字段名分别是
`id`
,
`username`
,
`email`
,
`password`
。
再来看一个复杂一点的例子。
`StrField`
和
`IntField`
在这里的用法,叫做
`属性描述符`
。
简单来说呢,
`属性描述符`
可以实现对属性值的类型,范围等一切做约束,意思就是说变量id只能是int类型,变量name只能是str类型,否则将会抛出异常。
那如何实现这两个
`属性描述符`
呢?请看代码。
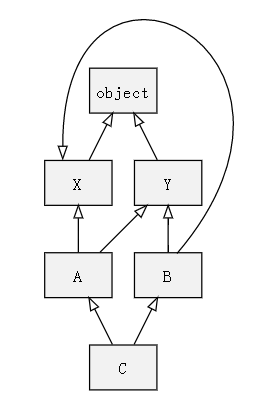
如果只依靠上面的算法,我们来一起算下,其继承关系是怎样的。
```
python
import
numbers
1.
首先进行深度遍历:[C, A, X, object, Y, object, B, Y, object, X, object];
2.
然后,只保留重复元素的最后一个:[C, A, B, Y, X, object]。
class
Field
:
pass
同样来验证一下。
class
IntField
(
Field
):
def
__init__
(
self
,
name
):
self
.
name
=
name
self
.
_value
=
None
```
class X(object): pass
class Y(object): pass
class A(X, Y): pass
class B(Y, X): pass
class C(A, B): pass
def
__get__
(
self
,
instance
,
owner
):
return
self
.
_value
print(C.__mro__)
```
def
__set__
(
self
,
instance
,
value
):
if
not
isinstance
(
value
,
numbers
.
Integral
):
raise
ValueError
(
"int value need"
)
self
.
_value
=
value
class
StrField
(
Field
):
def
__init__
(
self
,
name
):
self
.
name
=
name
self
.
_value
=
None
输出报错,它告诉我们 X,Y 具有二义性的继承关系(这是从Python 2.3后的 C3算法 才有的)。
def
__get__
(
self
,
instance
,
owner
):
return
self
.
_value
def
__set__
(
self
,
instance
,
value
):
if
not
isinstance
(
value
,
str
):
raise
ValueError
(
"string value need"
)
self
.
_value
=
value
```
Traceback (most recent call last):
File "F:/Python Script/Tornado/yang.py", line 7, in <module>
class C(A, B): pass
TypeError: Error when calling the metaclass bases
Cannot create a consistent method resolution
order (MRO) for bases X, Y
我们看到
`User`
类继承自
`BaseModel`
,这个
`BaseModel`
里,定义了数据库操作的各种方法,譬如我们使用的
`save`
函数,也可以放在这里面的。所以我们就可以来写一下这个
`BaseModel`
类
```
python
class
BaseModel
(
metaclass
=
ModelMetaClass
):
def
__init__
(
self
,
*
args
,
**
kw
):
for
k
,
v
in
kw
.
items
():
# 这里执行赋值操作,会进行数据描述符的__set__逻辑
setattr
(
self
,
k
,
v
)
return
super
().
__init__
()
def
save
(
self
):
db_columns
=
[]
db_values
=
[]
for
column
,
value
in
self
.
fields
.
items
():
db_columns
.
append
(
str
(
column
))
db_values
.
append
(
str
(
getattr
(
self
,
column
)))
sql
=
"insert into {table} ({columns}) values({values})"
.
format
(
table
=
self
.
db_table
,
columns
=
','
.
join
(
db_columns
),
values
=
','
.
join
(
db_values
))
pass
```
具体为什么会这样,我们来看一下
。
从
`BaseModel`
类中,save函数里面有几个新变量
。
对于 A 来说,其搜索顺序为[A, X, Y, object];
对于 B,其搜索顺序为 [B, Y, X, object];
对于 C,其搜索顺序为[C, A, B, X, Y, object]。
1.
fields: 存放所有的字段属性
2.
db_table:表名
我们
会发现,B 和 C 中 X、Y 的搜索顺序是相反的!也就是说,当 B 被继承时,它本身的行为竟然也发生了改变,这很容易导致不易察觉的错误。此外,即使把 C 搜索顺序中 X 和 Y 互换仍然不能解决问题,这时候它又会和 A 中的搜索顺序相矛盾。
我们
思考一下这个
`u`
实例的创建过程:
对于复杂一点的继承关系,我们在写代码的时候最好做到心中有数。接下来,就教教你,如何在层层复杂的继承关系中,计算出继承顺序。
`type`
->
`ModelMetaClass`
->
`BaseModel`
->
`User`
->
`u`
例如下面这张图
。
这里会有几个问题
。
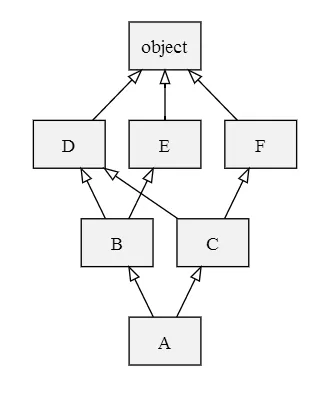
*
init的参数是User实例时传入的,所以传入的id是int类型,name是str类型。看起来没啥问题,若是这样,我上面的数据描述符就失效了,不能起约束作用。所以我们希望init接收到的id是IntField类型,name是StrField类型。
*
同时,我们希望这些字段属性,能够自动归类到fields变量中。因为,做为BaseModel,它可不是专门为User类服务的,它还要兼容各种各样的表。不同的表,表里有不同数量,不同属性的字段,这些都要能自动类别并归类整理到一起。这是一个ORM框架最基本的。
*
我们希望对表名有两种选择,一个是User中若指定Meta信息,比如表名,就以此为表名,若未指定就以类名的小写 做为表名。虽然BaseModel可以直接取到User的db_table属性,但是如果在数据库业务逻辑中,加入这段复杂的逻辑,显然是很不优雅的。
计算过程,会采用一种 merge算法。它的基本思想如下:
上面这几个问题,其实都可以通过元类的
`__new__`
函数来完成。
1.
检查第一个列表的头元素(如 L[B1] 的头),记作 H。
2.
若 H 未出现在其它列表的尾部,则将其输出,并将其从所有列表中删除,然后回到步骤1;否则,取出下一个列表的头部记作 H,继续该步骤。
3.
重复上述步骤,直至列表为空或者不能再找出可以输出的元素。如果是前一种情况,则算法结束;如果是后一种情况,说明无法构建继承关系,Python 会抛出异常。
下面就来看看,如何用元类来解决这些问题呢?请看代码。
你可以在草稿纸上,参照上面的merge算法,写出如下过程
```
python
class
ModelMetaClass
(
type
):
def
__new__
(
cls
,
name
,
bases
,
attrs
):
if
name
==
"BaseModel"
:
# 第一次进入__new__是创建BaseModel类,name="BaseModel"
# 第二次进入__new__是创建User类及其实例,name="User"
return
super
().
__new__
(
cls
,
name
,
bases
,
attrs
)
```
L[object] = [object]
L[D] = [D, object]
L[E] = [E, object]
L[F] = [F, object]
L[B] = [B, D, E, object]
L[C] = [C, D, F, object]
L[A] = [A] + merge(L[B], L[C], [B], [C])
= [A] + merge([B, D, E, object], [C, D, F, object], [B], [C])
= [A, B] + merge([D, E, object], [C, D, F, object], [C])
= [A, B, C] + merge([D, E, object], [D, F, object])
= [A, B, C, D] + merge([E, object], [F, object])
= [A, B, C, D, E] + merge([object], [F, object])
= [A, B, C, D, E, F] + merge([object], [object])
= [A, B, C, D, E, F, object]
```
# 根据属性类型,取出字段
fields
=
{
k
:
v
for
k
,
v
in
attrs
.
items
()
if
isinstance
(
v
,
Field
)}
当然,可以用代码验证类的 MRO,上面的例子可以写作:
# 如果User中有指定Meta信息,比如表名,就以此为准
# 如果没有指定,就默认以 类名的小写 做为表名,比如User类,表名就是user
_meta
=
attrs
.
get
(
"Meta"
,
None
)
db_table
=
name
.
lower
()
if
_meta
is
not
None
:
table
=
getattr
(
_meta
,
"db_table"
,
None
)
if
table
is
not
None
:
db_table
=
table
# 注意原来由User传递过来的各项参数attrs,最好原模原样的返回,
# 如果不返回,有可能下面的数据描述符不起作用
# 除此之外,我们可以往里面添加我们自定义的参数
attrs
[
"db_table"
]
=
db_table
attrs
[
"fields"
]
=
fields
return
super
().
__new__
(
cls
,
name
,
bases
,
attrs
)
```
class D(object): pass
class E(object): pass
class F(object): pass
class B(D, E): pass
class C(D, F): pass
class A(B, C): pass
A.__mro__
```
输出如下
## 6. \__new__ 有什么用?
在没有元类的情况下,每次创建实例,在先进入
`__init__`
之前都会先进入
` __new__`
。
```
python
class
User
:
def
__new__
(
cls
,
*
args
,
**
kwargs
):
print
(
"in BaseClass"
)
return
super
().
__new__
(
cls
)
def
__init__
(
self
,
name
):
print
(
"in User"
)
self
.
name
=
name
```
(<class '__main__.A'>,
<class '__main__.B'>,
<class '__main__.C'>,
<class '__main__.
使用如下
```
python
>>>
u
=
User
(
'wangbm'
)
in
BaseClass
in
User
>>>
u
.
name
'wangbm'
```
## 附录:参考文章
在有元类的情况下,每次创建类时,会都先进入 元类的
`__new__`
方法,如果你要对类进行定制,可以在这时做一些手脚。
---
综上,元类的
`__new__`
和普通类的不一样:
-
元类的
`__new__`
在创建类时就会进入,它可以获取到上层类的一切属性和方法,包括类名,魔法方法。
-
而普通类的
`__new__`
在实例化时就会进入,它仅能获取到实例化时外界传入的属性。
## 附录:参考文章
-
https://www.python.org/download/releases/2.3/mro/
-
https://www.cnblogs.com/whatisfantasy/p/6046991.html
-
[
Python Cookbook - 元编程
](
http://python3-cookbook.readthedocs.io/zh_CN/latest/chapters/p09_meta_programming.html
)
-
[
深刻理解Python中的元类
](
http://blog.jobbole.com/21351/
)
source/c07/c07_08.rst
浏览文件 @
b704fb5a
此差异已折叠。
点击以展开。
source/c07/c07_09.md
浏览文件 @
b704fb5a
此差异已折叠。
点击以展开。
source/c07/c07_09.rst
浏览文件 @
b704fb5a
此差异已折叠。
点击以展开。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录