refactor: mv wiki doc to repo (#1181)
Showing
docs/benchmark/performance.md
0 → 100644
docs/catalogue.md
0 → 100644
docs/design/architecture.md
0 → 100644
docs/design/blackwidonw.md
0 → 100644
docs/design/consistency.md
0 → 100644
docs/design/lock.md
0 → 100644
docs/design/nemo.md
0 → 100644
docs/design/snapshot.md
0 → 100644
docs/design/sync.md
0 → 100644
docs/design/thread.md
0 → 100644
{kind=link}
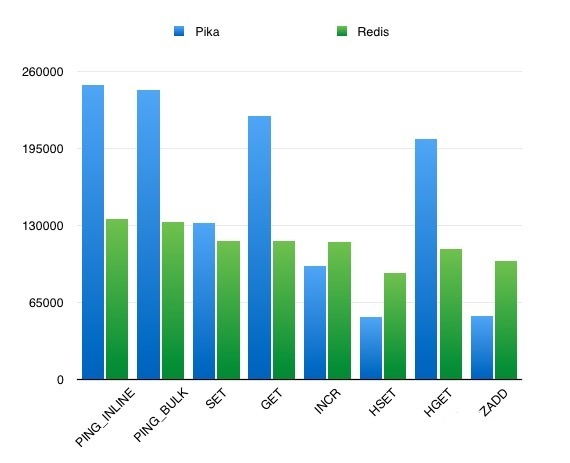
36.3 KB
{kind=link}
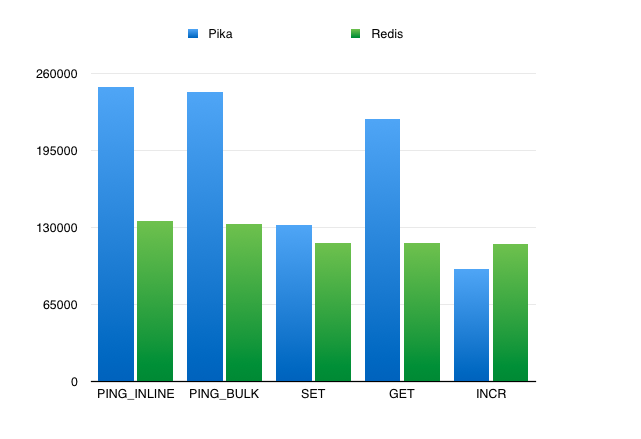
37.7 KB
docs/images/benchmarkVsSSDB01.png
0 → 100644
{kind=link}
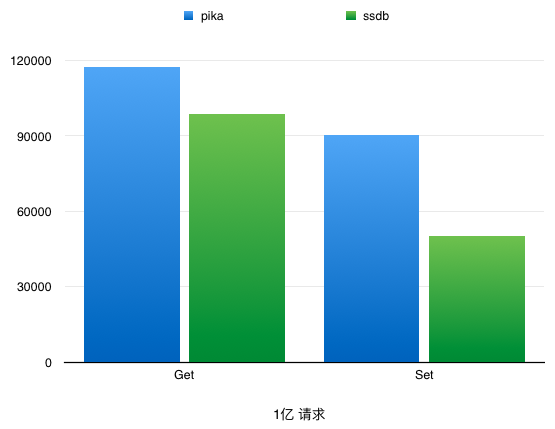
23.7 KB
docs/images/benchmarkVsSSDB02.png
0 → 100644
{kind=link}
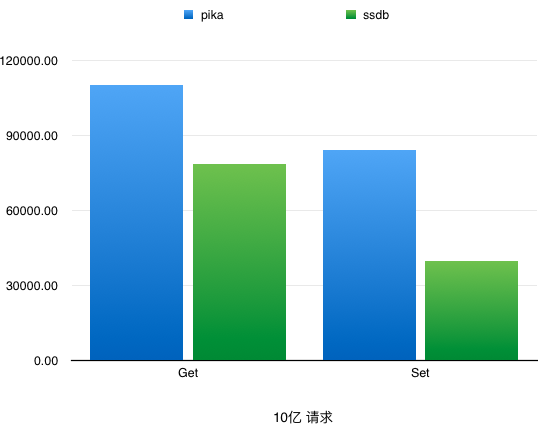
23.6 KB
docs/introduce.md
0 → 100644
docs/ops/API.md
0 → 100644
docs/ops/APIDifference.md
0 → 100644
docs/ops/FAQ.md
0 → 100644
docs/ops/MultiDB.md
0 → 100644
docs/ops/adminComnand.md
0 → 100644
docs/ops/bestPractice.md
0 → 100644
docs/ops/client.md
0 → 100644
此差异已折叠。
docs/ops/config.md
0 → 100644
docs/ops/dualMaster.md
0 → 100644
docs/ops/infoCommand.md
0 → 100644
docs/ops/install.md
0 → 100644
docs/ops/memoryUsage.md
0 → 100644
docs/ops/pikaVsSSDB.md
0 → 100644
docs/ops/shardingTutorials.md
0 → 100644
docs/ops/upgrade.md
0 → 100644