用OpenCV实现条形码识别
Showing
此差异已折叠。
OneFlow/imgs/1.jpg
已删除
100644 → 0
{kind=link}

8.0 KB
OneFlow/imgs/1.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/10.jpg
已删除
100644 → 0
{kind=link}

105.0 KB
OneFlow/imgs/10.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/11.jpg
已删除
100644 → 0
{kind=link}

10.5 KB
OneFlow/imgs/11.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/12.jpg
已删除
100644 → 0
{kind=link}

214.1 KB
OneFlow/imgs/12.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/13.jpg
已删除
100644 → 0
{kind=link}

12.3 KB
OneFlow/imgs/13.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/14.jpg
已删除
100644 → 0
{kind=link}

316.4 KB
OneFlow/imgs/14.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/15.jpg
已删除
100644 → 0
{kind=link}

9.6 KB
OneFlow/imgs/15.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/16.jpg
已删除
100644 → 0
{kind=link}

95.8 KB
OneFlow/imgs/16.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/17.jpg
已删除
100644 → 0
{kind=link}

13.1 KB
OneFlow/imgs/17.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/18.jpg
已删除
100644 → 0
{kind=link}

235.3 KB
OneFlow/imgs/18.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/19.jpg
已删除
100644 → 0
{kind=link}
89.3 KB
OneFlow/imgs/19.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/2.jpg
已删除
100644 → 0
{kind=link}

1.1 MB
OneFlow/imgs/2.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/20.jpg
已删除
100644 → 0
{kind=link}
122.9 KB
OneFlow/imgs/20.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/21.jpg
已删除
100644 → 0
{kind=link}
41.2 KB
OneFlow/imgs/21.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/22.jpg
已删除
100644 → 0
{kind=link}
55.5 KB
OneFlow/imgs/22.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/23.jpg
已删除
100644 → 0
{kind=link}
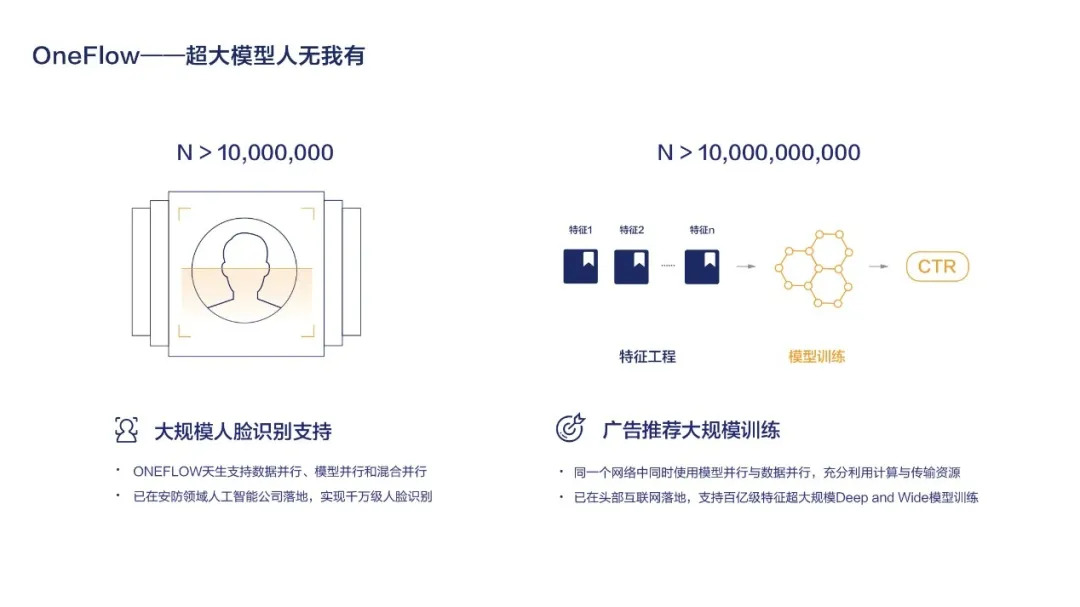
62.9 KB
OneFlow/imgs/23.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/24.jpg
已删除
100644 → 0
{kind=link}
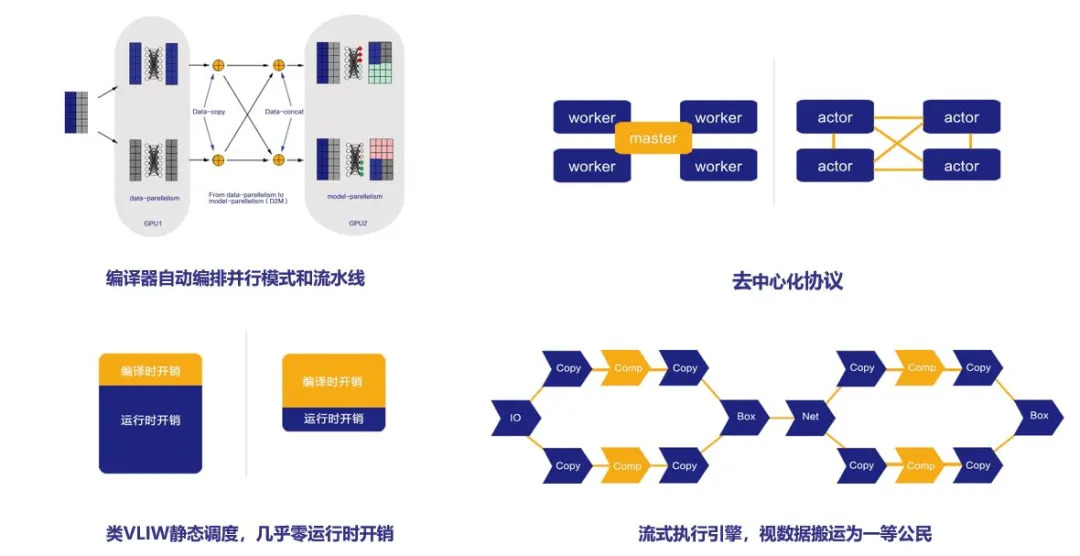
84.7 KB
OneFlow/imgs/24.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/25.png
已删除
100644 → 0
{kind=link}
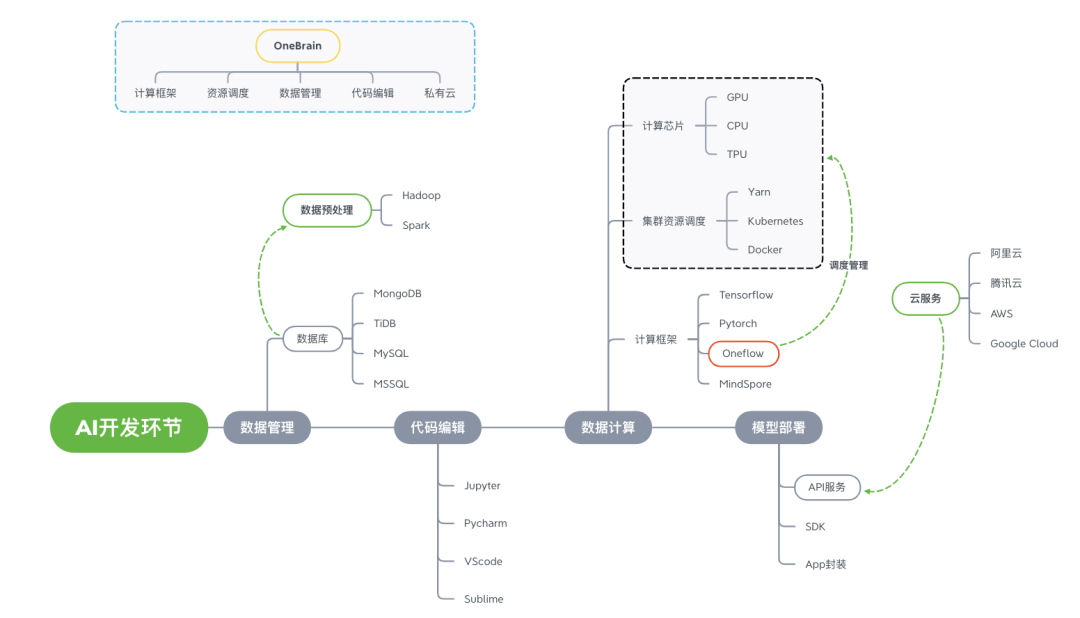
102.7 KB
OneFlow/imgs/26.jpg
已删除
100644 → 0
{kind=link}
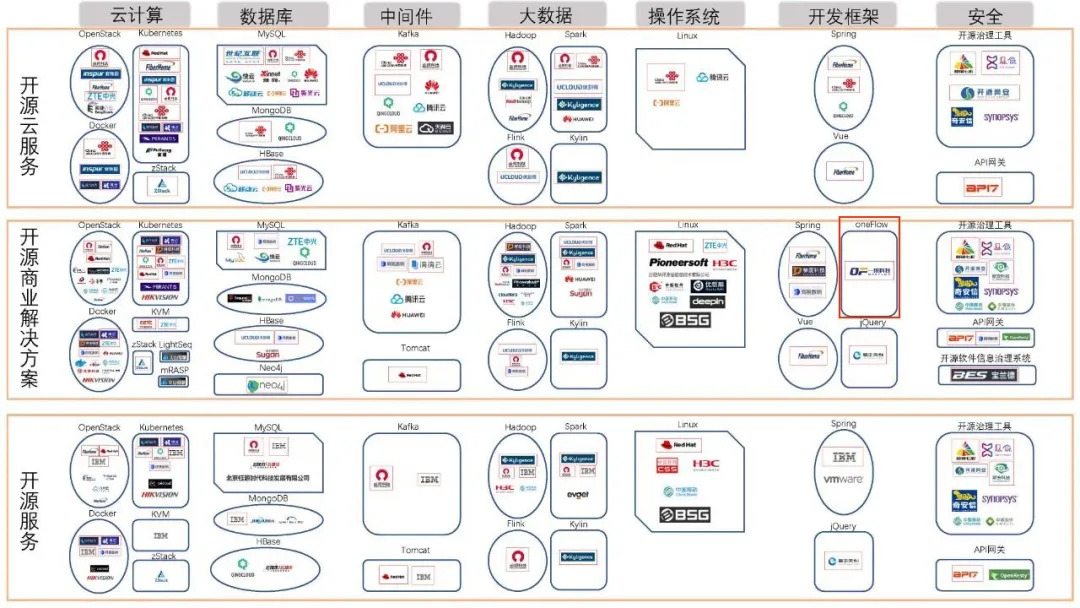
206.4 KB
OneFlow/imgs/26.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/27.jpg
已删除
100644 → 0
{kind=link}
279.5 KB
OneFlow/imgs/27.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/28.jpg
已删除
100644 → 0
{kind=link}
62.4 KB
OneFlow/imgs/28.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/29.png
已删除
100644 → 0
{kind=link}
31.4 KB
OneFlow/imgs/3.jpg
已删除
100644 → 0
{kind=link}

8.9 KB
OneFlow/imgs/3.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/30.png
已删除
100644 → 0
{kind=link}
217.8 KB
OneFlow/imgs/31.png
已删除
100644 → 0
{kind=link}
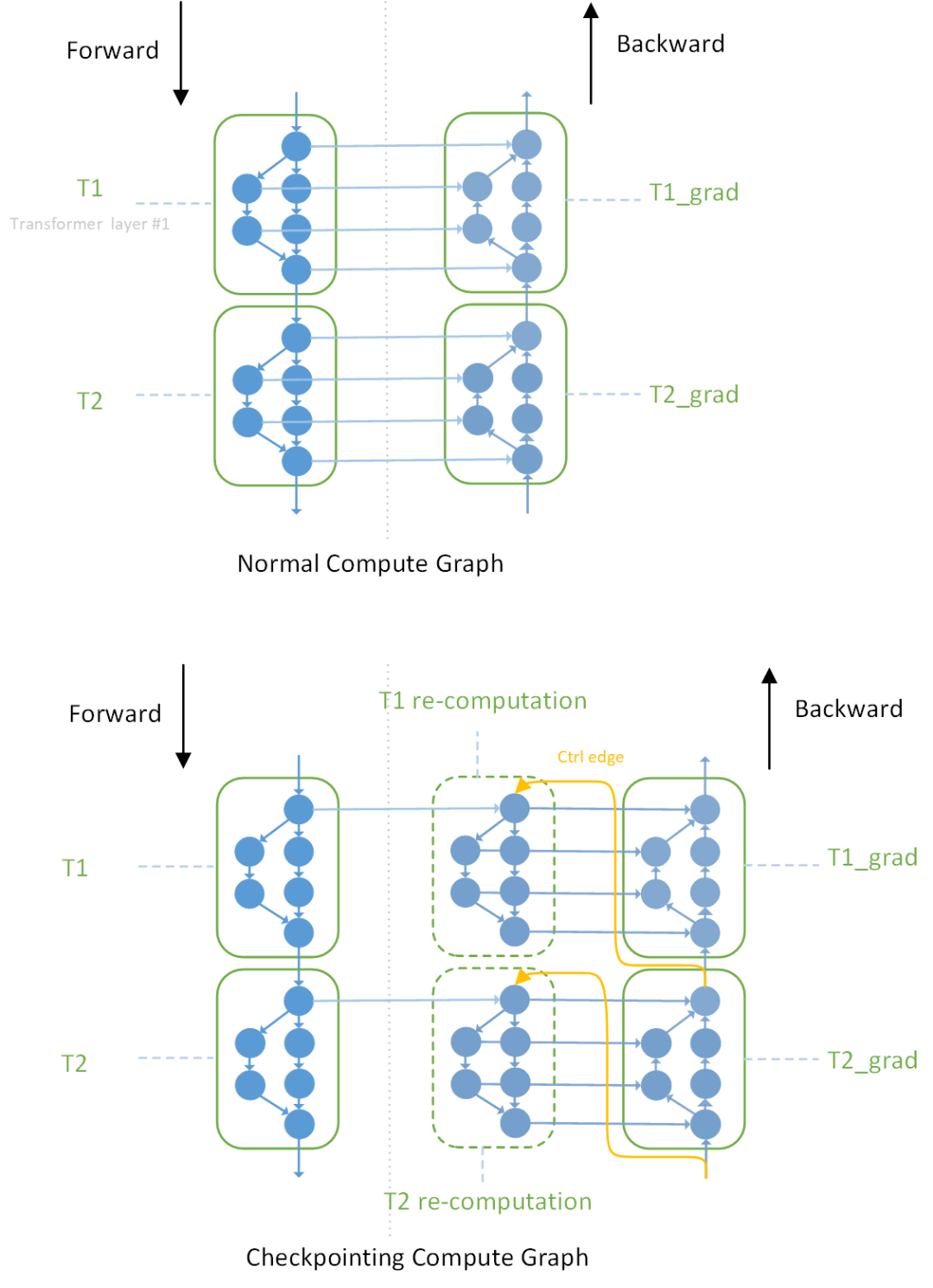
217.8 KB
OneFlow/imgs/4.jpg
已删除
100644 → 0
{kind=link}

653.8 KB
OneFlow/imgs/4.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/5.jpg
已删除
100644 → 0
{kind=link}

8.9 KB
OneFlow/imgs/5.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/6.jpg
已删除
100644 → 0
{kind=link}

570.3 KB
OneFlow/imgs/6.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/7.jpg
已删除
100644 → 0
{kind=link}

10.7 KB
OneFlow/imgs/7.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/8.jpg
已删除
100644 → 0
{kind=link}

374.3 KB
OneFlow/imgs/8.webp
已删除
100644 → 0
{kind=link}
文件已删除
OneFlow/imgs/9.jpg
已删除
100644 → 0
{kind=link}

11.1 KB
OneFlow/imgs/9.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/1.jpg
已删除
100644 → 0
{kind=link}

48.9 KB
PaddlePaddle/imgs/1.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/10.jpg
已删除
100644 → 0
{kind=link}
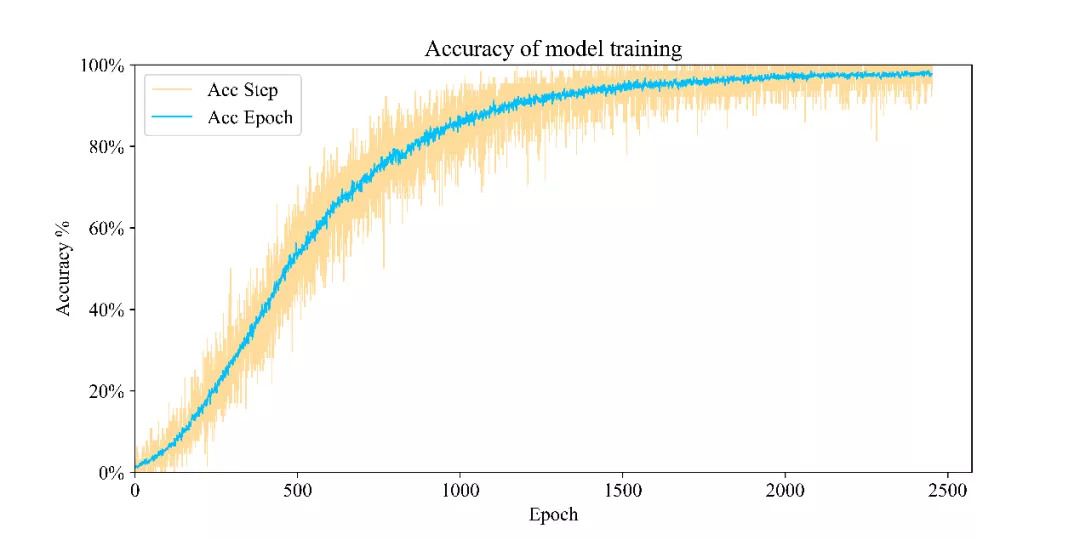
66.5 KB
PaddlePaddle/imgs/10.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/11.jpg
已删除
100644 → 0
{kind=link}

21.0 KB
PaddlePaddle/imgs/11.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/12.jpg
已删除
100644 → 0
{kind=link}
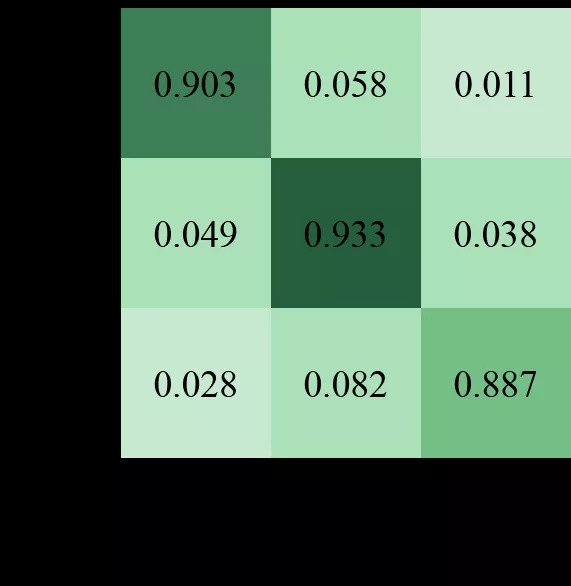
30.4 KB
PaddlePaddle/imgs/12.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/13.png
已删除
100644 → 0
{kind=link}

623.8 KB
PaddlePaddle/imgs/14.png
已删除
100644 → 0
{kind=link}

366.1 KB
PaddlePaddle/imgs/15.png
已删除
100644 → 0
{kind=link}
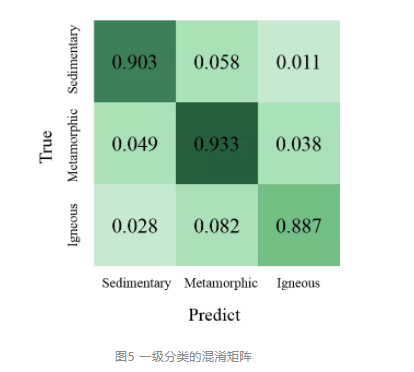
37.2 KB
PaddlePaddle/imgs/16.png
已删除
100644 → 0
{kind=link}
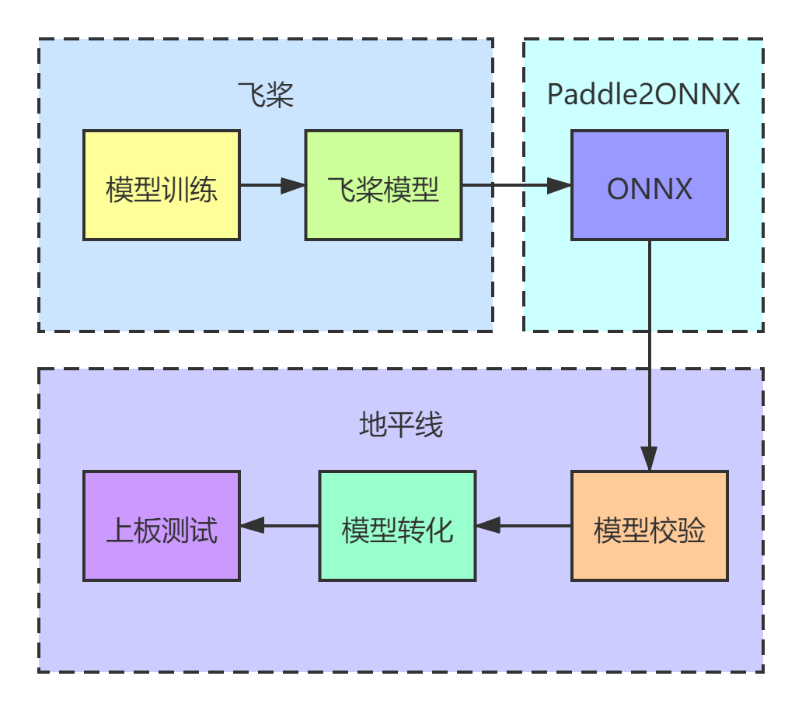
61.4 KB
PaddlePaddle/imgs/17.jpg
已删除
100644 → 0
{kind=link}
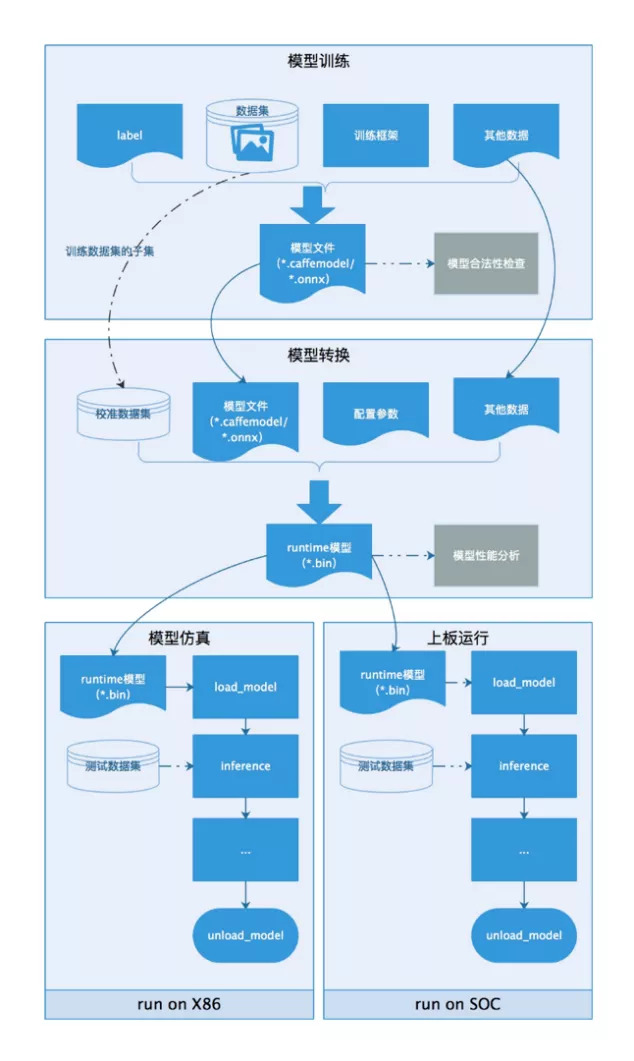
101.9 KB
PaddlePaddle/imgs/17.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/18.jpg
已删除
100644 → 0
{kind=link}
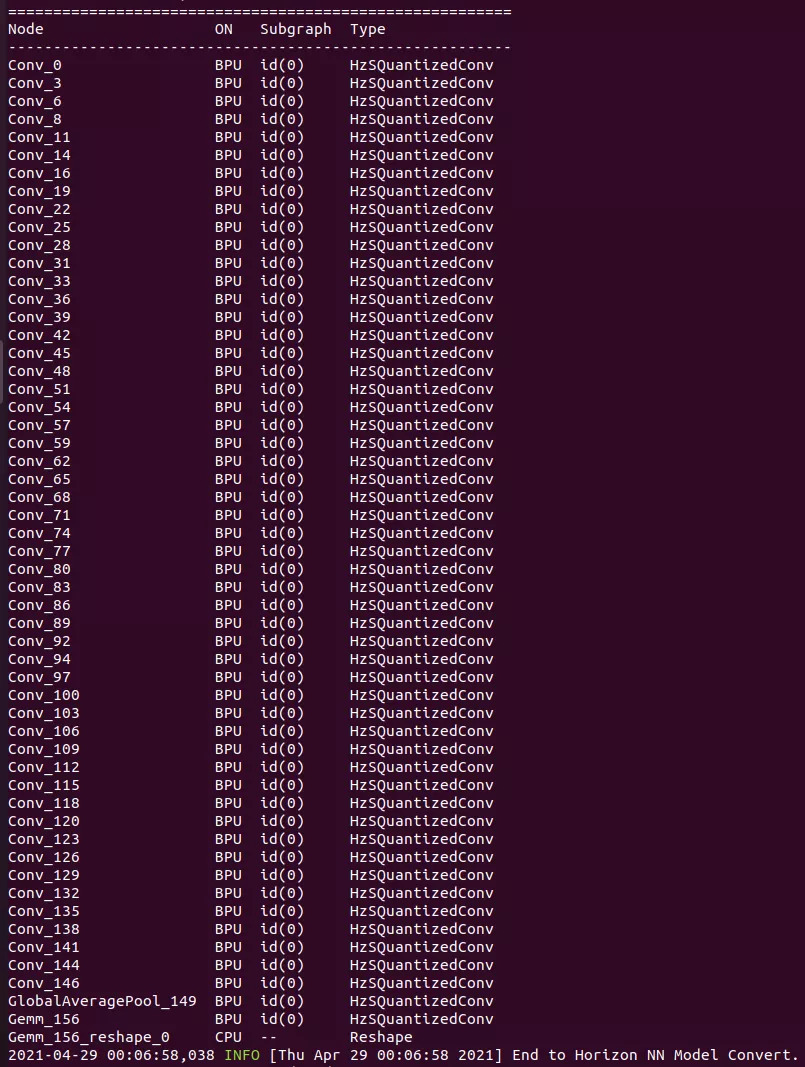
273.1 KB
PaddlePaddle/imgs/18.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/19.png
已删除
100644 → 0
{kind=link}
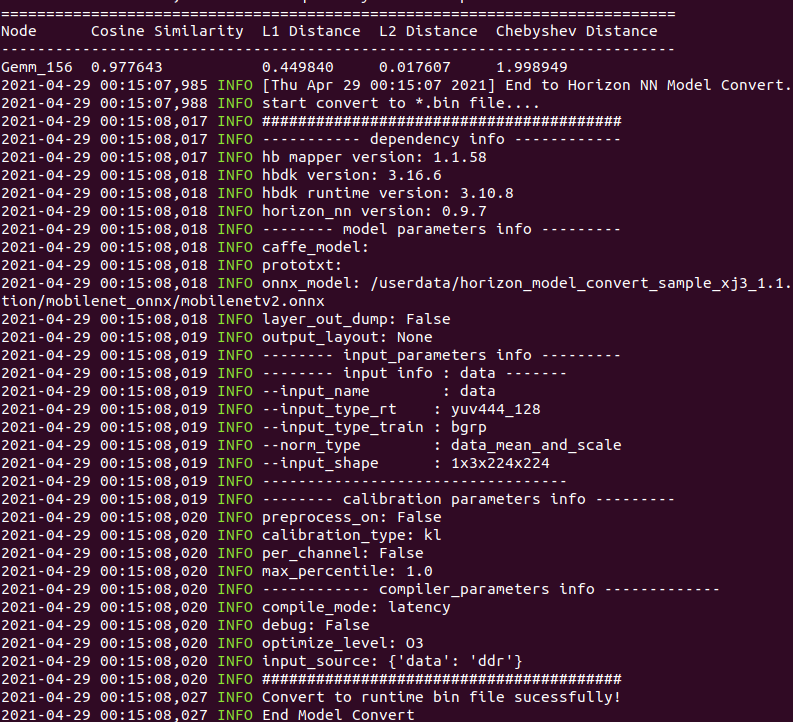
163.2 KB
PaddlePaddle/imgs/2.jpg
已删除
100644 → 0
{kind=link}
61.6 KB
PaddlePaddle/imgs/2.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/20.png
已删除
100644 → 0
{kind=link}
48.0 KB
PaddlePaddle/imgs/3.png
已删除
100644 → 0
{kind=link}

71.8 KB
PaddlePaddle/imgs/3.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/4.gif
已删除
100644 → 0
{kind=link}
1.6 MB
PaddlePaddle/imgs/5.jpg
已删除
100644 → 0
{kind=link}
157.0 KB
PaddlePaddle/imgs/5.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/6.jpg
已删除
100644 → 0
{kind=link}
245.2 KB
PaddlePaddle/imgs/6.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/7.jpg
已删除
100644 → 0
{kind=link}

155.0 KB
PaddlePaddle/imgs/7.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/8.jpg
已删除
100644 → 0
{kind=link}
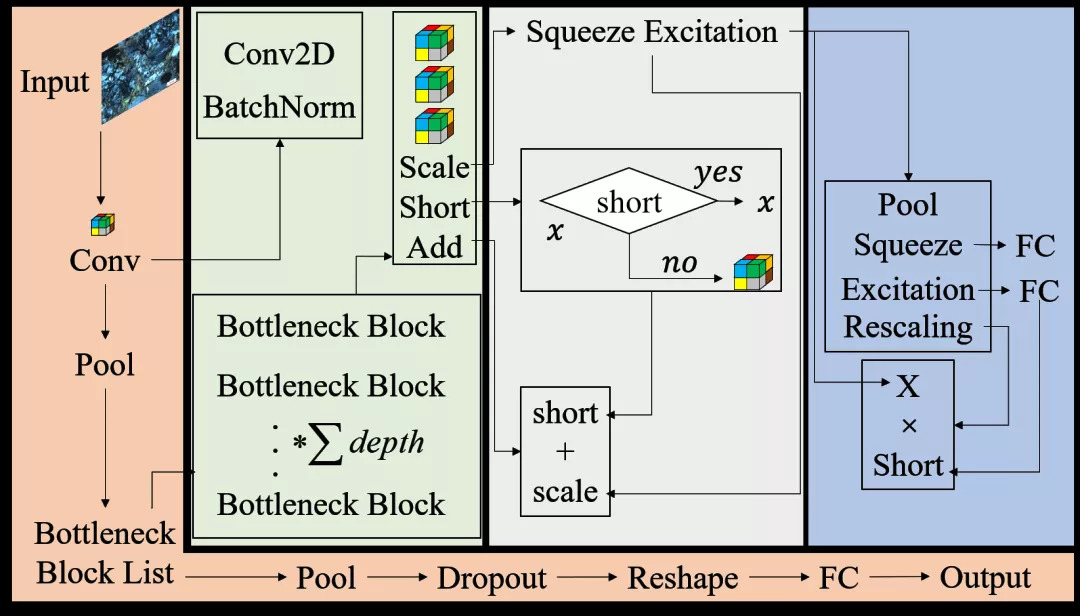
135.2 KB
PaddlePaddle/imgs/8.webp
已删除
100644 → 0
{kind=link}
文件已删除
PaddlePaddle/imgs/9.jpg
已删除
100644 → 0
{kind=link}
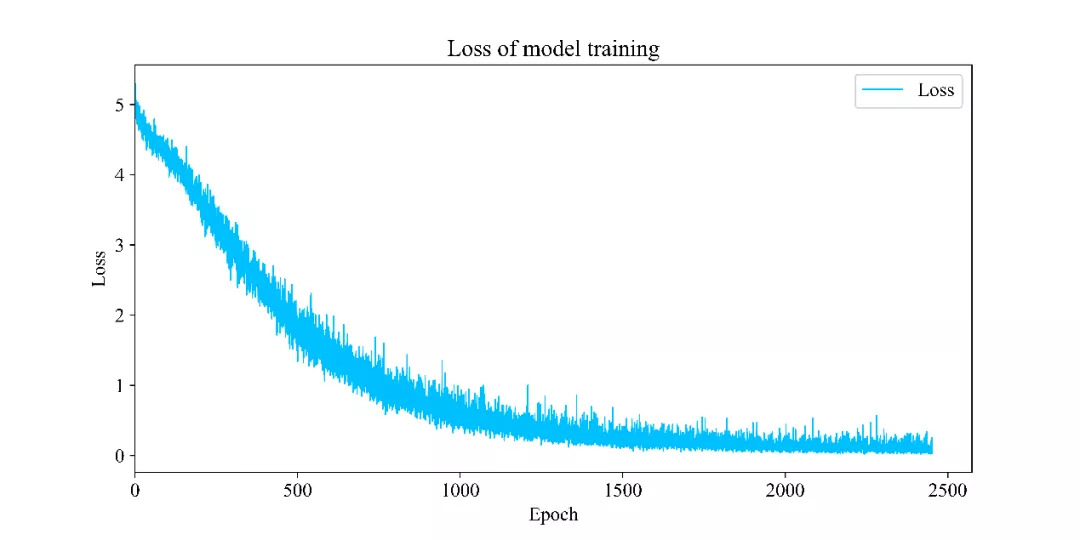
52.8 KB
PaddlePaddle/imgs/9.webp
已删除
100644 → 0
{kind=link}
文件已删除
imgs/1.png
0 → 100644
{kind=link}

30.6 KB
imgs/2.png
0 → 100644
{kind=link}

102.1 KB
imgs/3.png
0 → 100644
{kind=link}

90.1 KB
imgs/4.png
0 → 100644
{kind=link}

155.1 KB
imgs/5.png
0 → 100644
{kind=link}
此差异已折叠。
imgs/6.png
0 → 100644
{kind=link}
此差异已折叠。