Pegasus is a distributed key-value storage system developed and maintained by Xiaomi Cloud Storage Team, with targets of
high availability, high performance, strong consistency and ease of use. The original motivation of this project is to replace
[Apache HBase](https://hbase.apache.org/) for users who only need simple key-value schema but require low latency and high availability.
It is based on the modified [rDSN](https://github.com/XiaoMi/rdsn)(original[Microsoft/rDSN](https://github.com/Microsoft/rDSN)) framework,
and uses modified [RocksDB](https://github.com/xiaomi/pegasus-rocksdb)(original[facebook/RocksDB](https://github.com/facebook/rocksdb)) as underlying storage engine.
The consensus algorithm it uses is [PacificA](https://www.microsoft.com/en-us/research/publication/pacifica-replication-in-log-based-distributed-storage-systems/).
## Features
* High performance
Here are several key aspects that make Pegasus a high performance storage system:
- Implemented in C++
-[Staged event-driven architecture](https://en.wikipedia.org/wiki/Staged_event-driven_architecture), a distinguished architecture that Nginx adopts.
- High performance storage-engine with [RocksDB](https://github.com/facebook/rocksdb), though slight change is made to support fast learning.
* High availability
Unlike Bigtable/HBase, a non-layered replication architecture is adopted in Pegasus in which an external DFS like GFS/HDFS isn't the dependency of the persistent data, which benefits the availability a lot. Meanwhile, availability problems in HBase which result from Java GC are totally eliminated for the use of C++.
We adopt the [PacificA](https://www.microsoft.com/en-us/research/publication/pacifica-replication-in-log-based-distributed-storage-systems/#) consensus algorithm to make Pegasus a strong consistency system.
* Easily scaling out
Load can be balanced dynamically to newly added data nodes with a global load balancer.
* Easy to use
We provided C++ and Java client with simple interfaces to make it easy to use.
Pegasus is a distributed key-value storage system which is designed to be:
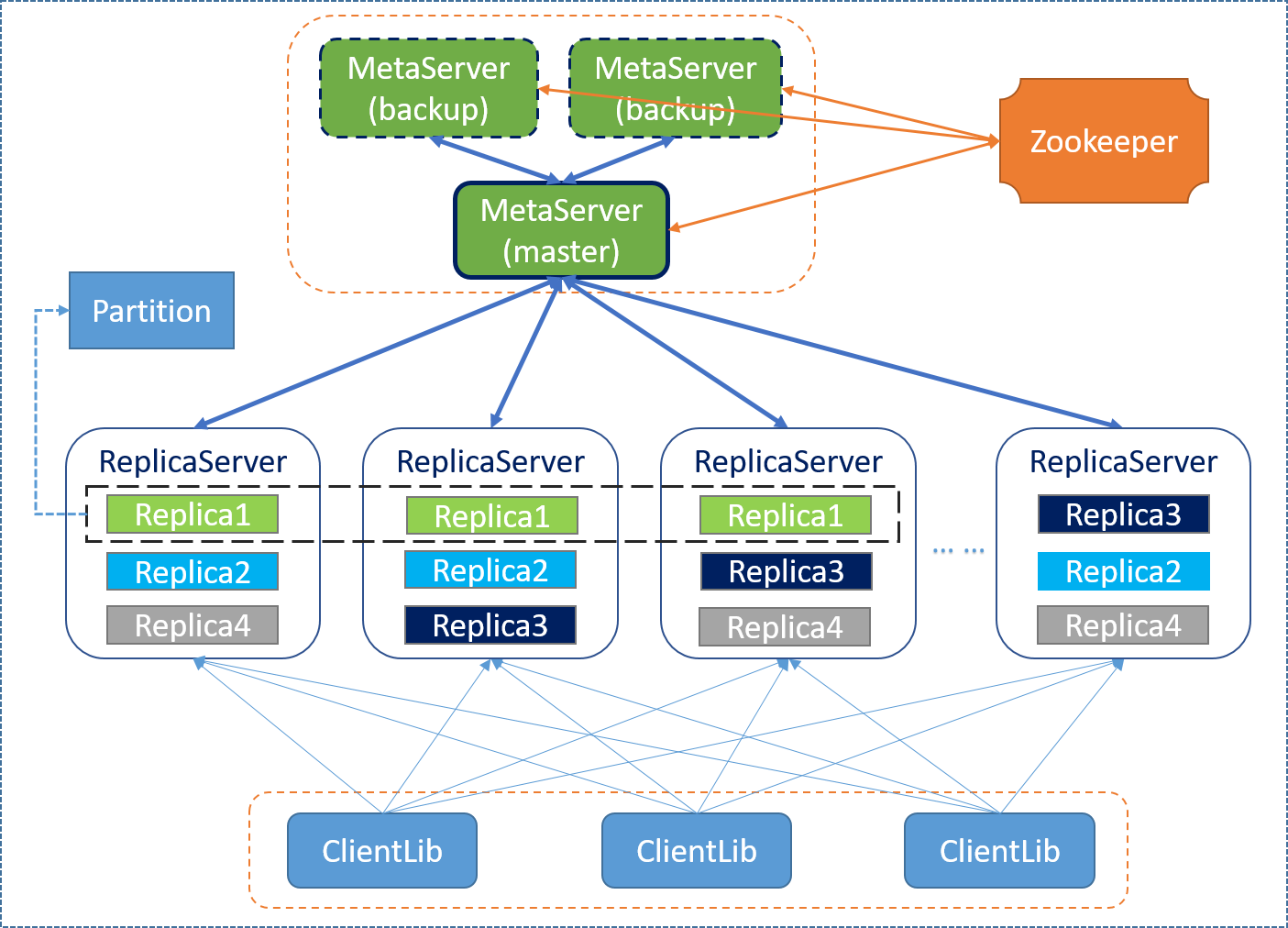
Here is a brief explanation on the concepts and terms in the diagram:
-**horizontally scalable** distributed using hash-based partitioning
-**strongly consistent**: ensured by [PacificA][PacificA] consensus protocol
-**high-performance**: using [RocksDB][pegasus-rocksdb] as underlying storage engine
-**simple**: well-defined, easy-to-use APIs
* MetaServer: a component in Pegasus to do the whole cluster management. The meta-server is something like "HMaster" in HBase.
* Zookeeper: the external dependency of Pegasus. We use zookeeper to store the meta state of the cluster and do meta-server's fault tolerance.
* ReplicaServer: a component in Pegasus to serve client's read/write request. The replica-server is also the container for replicas.
* Partition/replica: the whole key space is split into several partitions, and each partition has several replicas for fault tolerance. You may want to refer to the [PacificA](https://www.microsoft.com/en-us/research/publication/pacifica-replication-in-log-based-distributed-storage-systems/#) algorithm for more details.
Pegasus has been widely-used in XiaoMi and serves millions of requests per second.
It is a mature, active project. We hope to build a diverse developer and user
community and attract contributions from more people.
For more details about design and implementation, please refer to PPTs under [`docs/ppt/`](docs/ppt/).
## Background
## Data model & API overview
HBase was recognized as the only large-scale KV store solution in XiaoMi
until Pegasus came out in 2015 to solve the problem of high latency
of HBase because of its Java GC and RPC overhead of the underlying distributed filesystem.
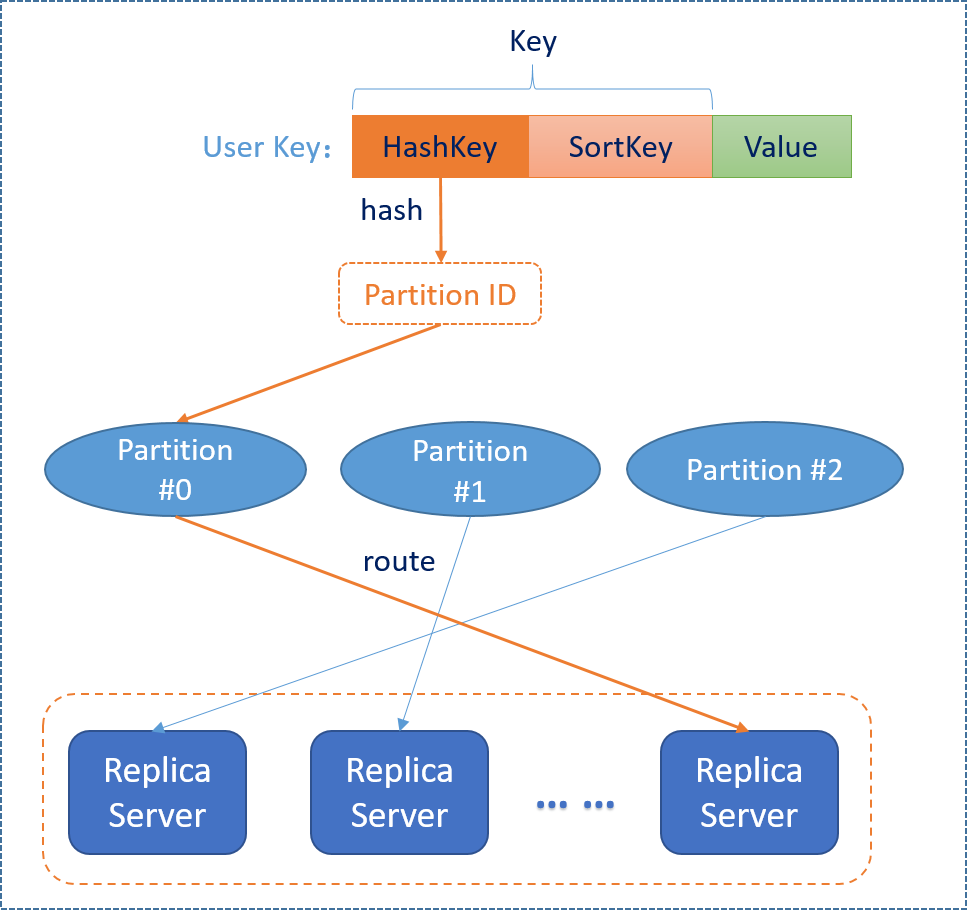
The data model in Pegasus is (hashkey + sortkey) -> value, in which:
* Hashkey is used for partitioning. Values with different hash keys may stored in different partitions.
* Sortkey is used for sorting within a hashkey. Values with the **same** hashkey but **different** sortkeys are in the **same partition**, and ordered by the sort key. If you use scan API to scan a single hashkey, you will get the values by the lexicographical order of sortkeys.
Pegasus targets to fill the gap between Redis and HBase. As the former
is in-memory, low latency, but does not provide a strong-consistency guarantee.
And unlike the latter, Pegasus is entirely written in C++ and its write-path
relies merely on the local filesystem.
The following diagram shows the data model of Pegasus:
Apart from the performance requirements, we also need a storage system
to ensure multiple-level data safety and support fast data migration
between data centers, automatic load balancing, and online partition split.
We open sourced this project because we know that it is far from mature and needs lots of
improvement. So we are looking forward to your [contribution](docs/contribution.md).
## Contact
If you have more questions, please join our [slack channel](https://join.slack.com/t/pegasus-kv/shared_invite/enQtMjcyMjQzOTk4Njk1LWVkMjlkMGE5Mzg1Y2M3MDc0NGYyYzQ5YzYyMGE0ZjlhMDMyNjU1ZGViYzdjZmUwNjVmNGE0ZDdkMWJiN2Q1MDY).
We use "clang-format"(version 3.9) to format our code. For ubuntu users, clang-format-3.9 could be installed via `apt-get`:
```
sudo apt-get install clang-format-3.9
```
After installed clang-format, you can format your code by the ".clang-format" config file in the root of the project.
## C++ development guidelines
Basically, we follow the google-code-style, except for:
* We prefer to use reference rather than pointers for return value of functions.
* The compilation of headers is controlled by "#progma once"
Reason for these exceptions is that we develop Pegasus based on Microsoft's open-source project [rDSN](https://github.com/Microsoft/rDSN), and we just follow its rules. Currently we fork a new repo on this project, and modification on our repo is hard to merge though we've made lots contributes to it.
## Roadmap
You may want to refer to the [roadmap](roadmap.md).
{kind=link}
{kind=link}