DolphinScheduler, as an open-source distributed workflow task scheduling system, can deploy and run smoothly in Intel architecture server environments and mainstream virtualization environments and supports mainstream Linux operating system environments.
This section briefs about the hardware requirements for DolphinScheduler. DolphinScheduler works as an open-source distributed workflow task scheduling system. It can deploy and run smoothly in Intel architecture server environments and mainstream virtualization environments. It also supports mainstream Linux operating system environments and ARM architecture.
## Linux Operating System Version Requirements
| OS | Version |
The Linux operating systems specified below can run on physical servers and mainstream virtualization environments such as VMware, KVM, and XEN.
| Operating System | Version |
| :----------------------- | :----------: |
| Red Hat Enterprise Linux | 7.0 and above |
| CentOS | 7.0 and above |
...
...
@@ -14,9 +16,9 @@ DolphinScheduler, as an open-source distributed workflow task scheduling system,
> **Note:**
>The above Linux operating systems can run on physical servers and mainstream virtualization environments such as VMware, KVM, and XEN.
## Recommended Server Configuration
## Server Configuration
DolphinScheduler supports 64-bit hardware platforms with Intel x86-64 architecture. The following shows the recommended server requirements in a production environment:
DolphinScheduler supports 64-bit hardware platforms with Intel x86-64 architecture. The following table shows the recommended server requirements in a production environment:
> - The above recommended configuration is the minimum configuration for deploying DolphinScheduler. Higher configuration is strongly recommended for production environments.
> - The recommended hard disk size is more than 50GB and separate the system disk and data disk.
## Network Requirements
DolphinScheduler provides the following network port configurations for normal operation:
...
...
@@ -45,4 +46,4 @@ DolphinScheduler provides the following network port configurations for normal o
## Browser Requirements
DolphinScheduler recommends Chrome and the latest browsers which use Chrome Kernel to access the front-end UI page.
\ No newline at end of file
The minimum supported version of Google Chrome is version 85, but version 90 or above is recommended.
If you need to use `DingTalk` for alerting, create an alert instance in the alert instance management and select the `DingTalk` plugin. The following shows the `DingTalk` configuration example:
If you need to use `DingTalk` for alerting, create an alert instance in the alert instance management and select the `DingTalk` plugin.
The following shows the `DingTalk` configuration example:
The data quality task is used to check the data accuracy during the integration and processing of data. Data quality tasks in this release include single-table checking, single-table custom SQL checking, multi-table accuracy, and two-table value comparisons. The running environment of the data quality task is Spark 2.4.0, and other versions have not been verified, and users can verify by themselves.
The execution flow of the data quality task is as follows:
The execution logic of the data quality task is as follows:
- The user defines the task in the interface, and the user input value is stored in `TaskParam`.
- When running a task, `Master` will parse `TaskParam`, encapsulate the parameters required by `DataQualityTask` and send it to `Worker`.
...
...
@@ -39,9 +40,12 @@ In the example, assuming that the actual value is 10, the operator is >, and the
# Task Operation Guide
## Null Value Check for Single Table Check
### Inspection Introduction
The goal of the null value check is to check the number of empty rows in the specified column. The number of empty rows can be compared with the total number of rows or a specified threshold. If it is greater than a certain threshold, it will be judged as failure.
- Calculate the SQL statement that the specified column is empty as follows:
- The SQL statement that calculates the null of the specified column is as follows:
@@ -121,7 +125,7 @@ The goal of field length verification is to check whether the length of the sele
## Uniqueness Check for Single Table Check
### Inspection Introduction
The goal of the uniqueness check is to check whether the field is duplicated. It is generally used to check whether the primary key is duplicated. If there is duplication and the threshold is reached, the check task will be judged to be failed.
The goal of the uniqueness check is to check whether the fields are duplicated. It is generally used to check whether the primary key is duplicated. If there are duplicates and the threshold is reached, the check task will be judged to be failed.
### Interface Operation Guide
...
...
@@ -165,7 +169,7 @@ The goal of regular expression verification is to check whether the format of th
## Enumeration Value Validation for Single Table Check
### Inspection Introduction
The goal of enumeration value verification is to check whether the value of a field is within the range of enumeration values. If there is data that is not in the range of enumeration values and exceeds the threshold, the task will be judged to fail
The goal of enumeration value verification is to check whether the value of a field is within the range of the enumeration value. If there is data that is not in the range of the enumeration value and exceeds the threshold, the task will be judged to fail.
@@ -18,7 +18,7 @@ Create a shell task and enter `echo ${dt}` in the script content. In this case,
### Save the workflow and set global parameters
You could follow this guide to set global parameter: On the workflow definition page, click the plus sign to the right of "Set Global", after filling in the variable name and value, then save it
Set global parameter: On the workflow definition page, click the plus sign to the right of "Set Global", after filling in the variable name and value, save it.
@@ -18,18 +18,20 @@ Usage of local parameters is: at the task define page, click the '+' beside the
### Use Local Parameter by Custom Parameter
This example shows how to use local parameters to print the current date. Create a Shell task and write a script with the content `echo ${dt}`. Click **custom parameter** in the configuration bar, and the configuration is as follows:
This example shows how to use local parameters to print the current date.
Create a Shell task and write a script with the content `echo ${dt}`. Click **custom parameter** in the configuration bar, and the configuration is as follows:
-in: IN indicates that local parameters can only be used on the current node, and OUT indicates that local.parameters can be transmitted to the downstream.
-IN: IN indicates that local parameters can only be used on the current node, and OUT indicates that local parameters can be transmitted to the downstream.
- DATE: indicates the DATE of the data type.
- $[YYYY-MM-DD] : indicates a built-in parameter derived from a user-defined format.
Save the workflow and run it. View Shell task's log.
Save the workflow and run it. View log of Shell task.
@@ -4,7 +4,9 @@ DolphinScheduler has three parameter types:
*[Global Parameter](global.md): parameters defined at the workflow define page.
*[Parameter Context](context.md): parameters passed by upstream task nodes.
*[Local Parameter](local.md): parameters belong to its node, which is the parameters defined by the user in [Custom Parameters]. The user can define part of the parameters when creating workflow definitions.
*[Local Parameter](local.md): parameters belong to its node, which is the parameters defined by the user in [Custom Parameters].
The user can define part of the parameters when creating workflow definitions.
As there are multiple sources of the parameter value, it will raise parameter priority issues when the parameter name is the same. The priority of DolphinScheduler parameters from high to low is: `Local Parameter > Parameter Context > Global Parameter`.
This page describes details regarding Project screen in Apache DolphinScheduler. Here, you will see all the functions which can be handled in this screen. The following table explains commonly used terms in Apache DolphinScheduler:
| Glossary | |
| ------ | -------- |
| DAG | Tasks in a workflow are assembled in form of Directed Acyclic Graph (DAG). A topological traversal is performed from nodes with zero degrees of entry until there are no subsequent nodes. |
| Workflow Definition | Visualization formed by dragging task nodes and establishing task node associations (DAG). |
| Workflow Instance | Instantiation of the workflow definition, which can be generated by manual start or scheduled scheduling. Each time the process definition runs, a workflow instance is generated. |
| Workflow Relation | Shows dynamic status of all the workflows in a project. |
| DAG | Tasks in a workflow are assembled in form of Directed Acyclic Graph (DAG). A topological traversal is performed from nodes with zero degrees of entry until there are no subsequent nodes. |
| Workflow Definition | Visualization formed by dragging task nodes and establishing task node associations (DAG). |
| Workflow Instance | Instantiation of the workflow definition, which can be generated by manual start or scheduled scheduling. Each time the process definition runs, a workflow instance is generated. |
| Workflow Relation | Shows dynamic status of all the workflows in a project. |
| Task | Task is a discrete action in a Workflow. Apache DolphinScheduler supports SHELL, SQL, SUB_PROCESS (sub-process), PROCEDURE, MR, SPARK, PYTHON, DEPENDENT ( depends), and plans to support dynamic plug-in expansion, (SUB_PROCESS). It is also a separate process definition that can be started and executed separately. |
| Task Instance | Instantiation of the task node in the process definition, which identifies the specific task execution status. |
| Task Instance | Instantiation of the task node in the process definition, which identifies the specific task execution status. |
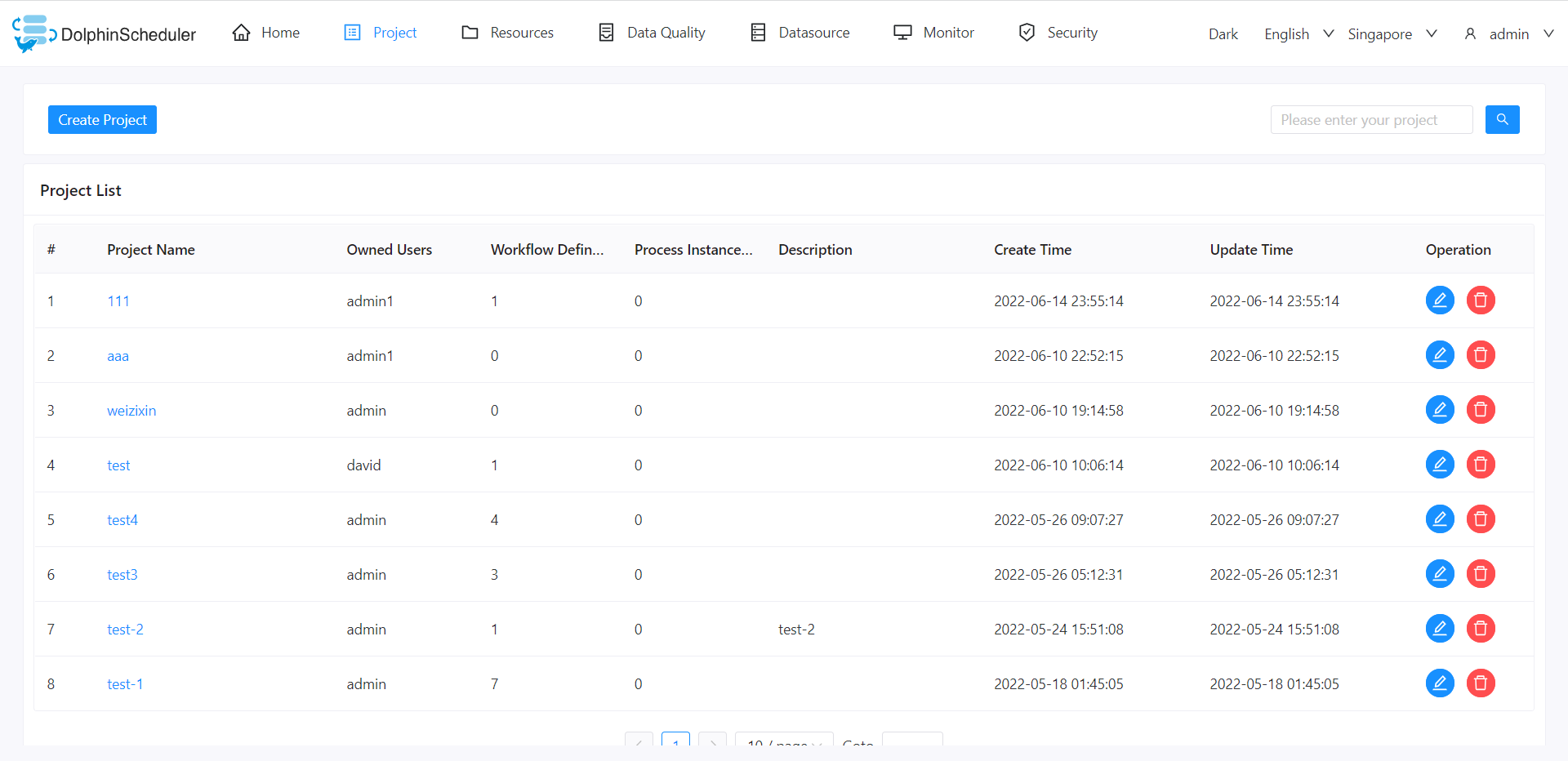
## Project List
On the project screen, list of all the existing projects along with details like name, owner, workflow definition, process instance, create and update time. This page also facilitates operations like create, edit, and delete project.
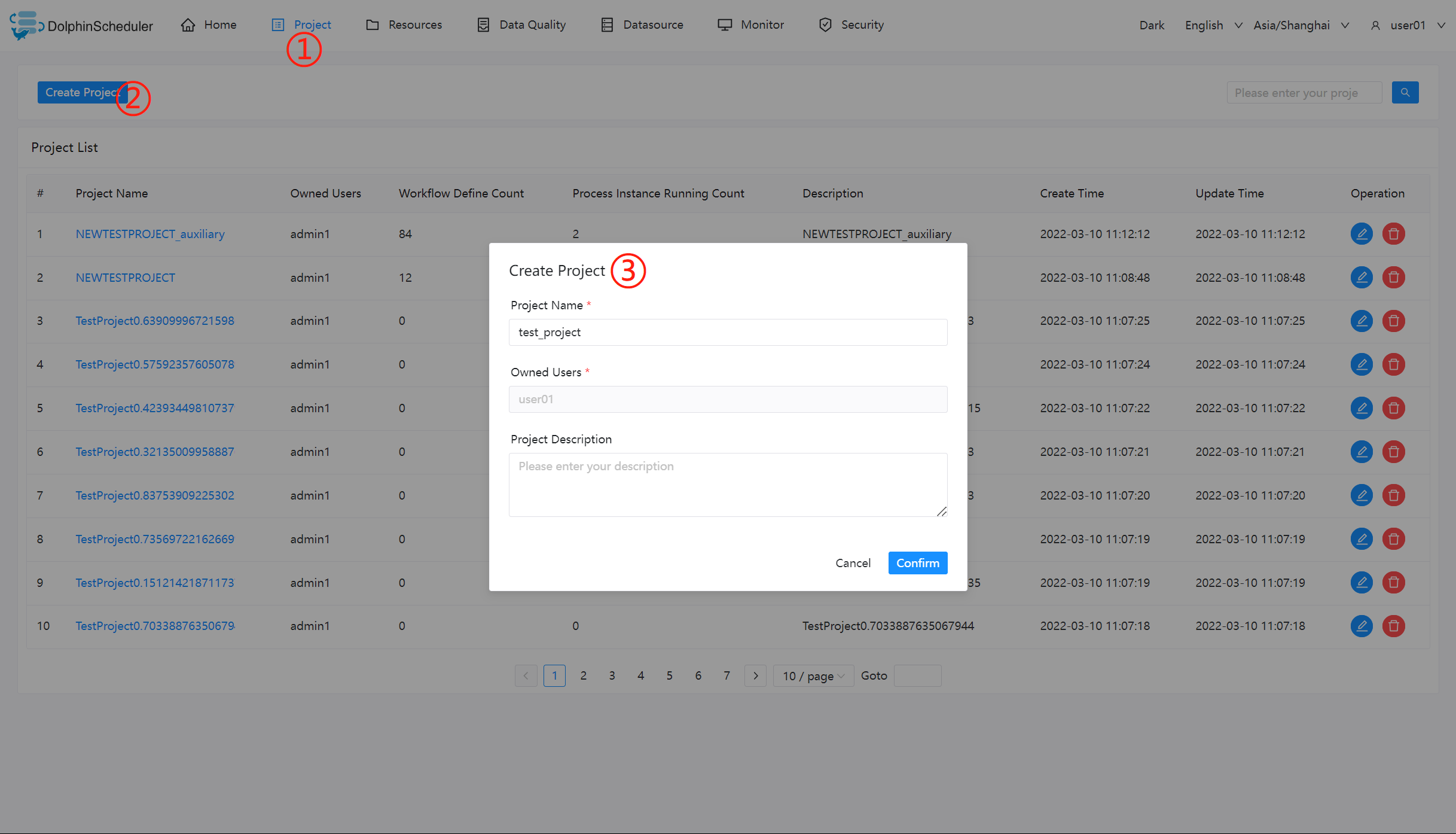
- Click `Project Management` to enter the project management page, click the `Create Project` button, enter the project name, project description, and click "Submit" to create a new project.
- Click the project name link on the project management page to enter the project home page, as shown in the figure below, the project home page contains the task status statistics, process status statistics, and workflow definition statistics of the project. The introduction for those metrics:
- Task status statistics: Within the specified time range, count the number of task instances status as successful submission, running, ready to pause, pause, ready to stop, stop, failure, success, need fault tolerance, kill and waiting threads
- Process status statistics: Within the specified time range, count the number of workflow instances status as submission success, running, ready to pause, pause, ready to stop, stop, failure, success, need fault tolerance, kill and waiting threads
- Workflow definition statistics: Count the workflow definitions created by this user and granted by the administrator
- Click `Project Management -> Workflow -> Task Instance`. Enter the `Task Instance` page, as shown in the figure below, click workflow instance name, you can jump to the workflow instance DAG chart to view the task status.
## Create Task Instance
Click `Project Management -> Workflow -> Task Instance` to enter the task instance page, as shown in the figure below, click the name of the workflow instance to jump to the DAG diagram of the workflow instance to view the task status.
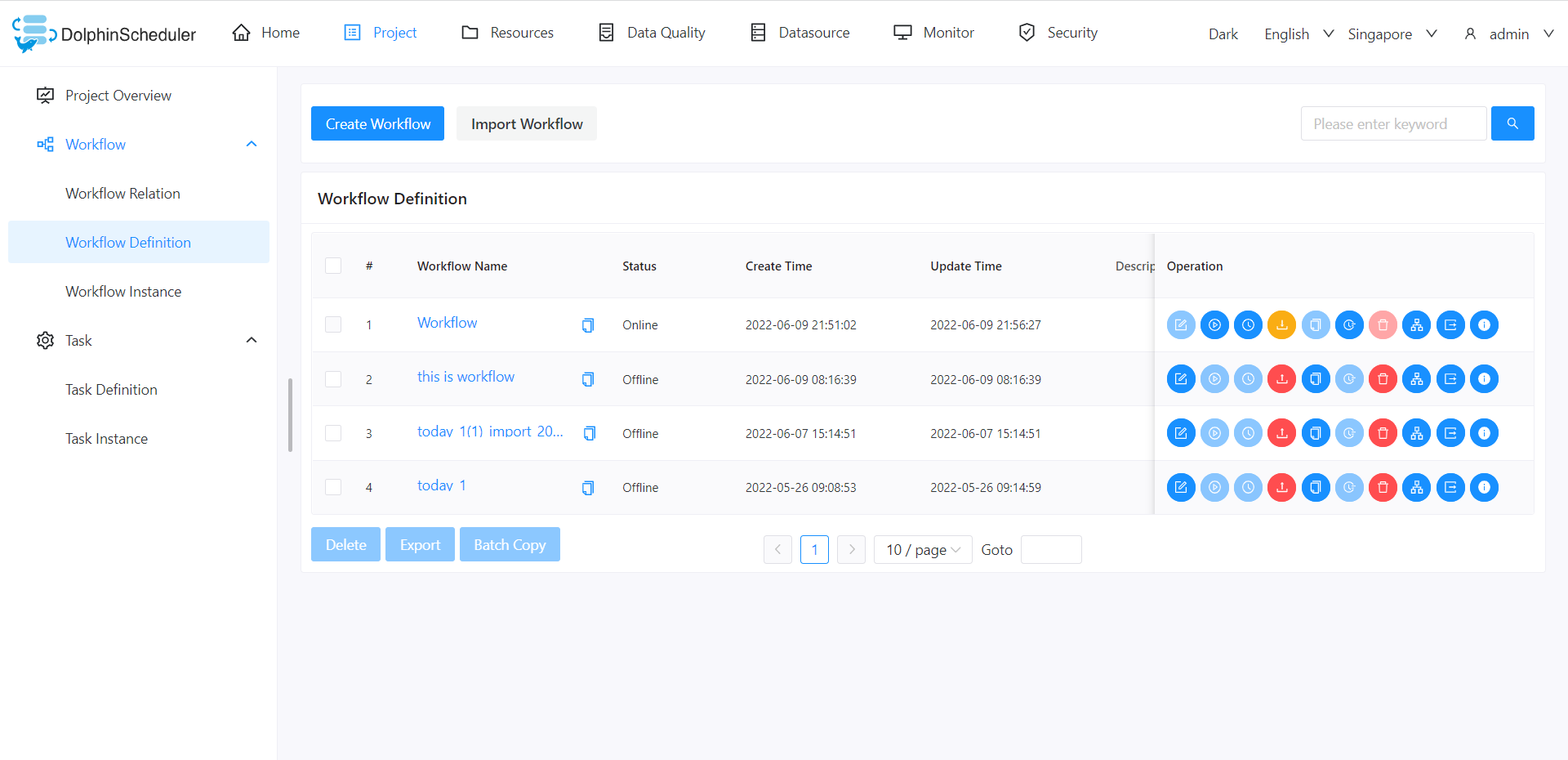
- Click `Project Management -> Workflow -> Workflow Definition`, enter the `Workflow Definition` page, and click the `Create Workflow` button to enter the **workflow DAG edit** page, as shown in the following figure:
Click `Project Management -> Workflow -> Workflow Definition`, enter the `Workflow Definition` page, and click the `Create Workflow` button to enter the **workflow DAG edit** page, as shown in the following figure:
-Drag from the toolbar <imgsrc="../../../../img/tasks/icons/shell.png"width="15"/> to the canvas, to add a shell task to the canvas, as shown in the figure below:
Drag from the toolbar <imgsrc="../../../../img/tasks/icons/shell.png"width="15"/> to the canvas, to add a shell task to the canvas, as shown in the figure below:
1. Fill in the `Node Name`, `Description` and `Script` fields;
2. Check “`Normal`” for “`Run Flag`”. If “`Prohibit Execution`” is checked, the task will not execute when the workflow runs;
3. Select `Task Priority`: when the number of worker threads is insufficient, high priority tasks will execute first in the execution queue, and tasks with the same priority will execute in the order of first in, first out;
4. Timeout alarm (optional): check the timeout alarm, timeout failure, and fill in the "timeout period". When the task execution time exceeds **timeout period**, an alert email will send and the task timeout fails;
5. Resources (optional). Resources are files create or upload in the `Resource Center -> File Management` page. For example, the file name is `test.sh`, and the command to call the resource in the script is `sh test.sh`;
6. Customize parameters (optional);
1. Fill in the `Node Name`, `Description` and `Script` fields.
2. Check `Normal` for `Run Flag`. If `Prohibit Execution` is checked, the task will not execute when the workflow runs.
3. Select `Task Priority`: when the number of worker threads is insufficient, high priority tasks will execute first in the execution queue, and tasks with the same priority will execute in the order of first in, first out.
4. Timeout alarm (optional): check the timeout alarm, timeout failure, and fill in the "timeout period". When the task execution time exceeds **timeout period**, an alert email will send and the task timeout fails.
5. Resources (optional). Resources are files create or upload in the `Resource Center -> File Management` page. For example, the file name is `test.sh`, and the command to call the resource in the script is `sh test.sh`.
6. Customize parameters (optional).
7. Click the `Confirm Add` button to save the task settings.
-**Set dependencies between tasks:** Click the plus sign on the right of the task node to connect the task; as shown in the figure below, task Node_B and task Node_C execute in parallel, When task Node_A finished execution, tasks Node_B and Node_C will execute simultaneously.
### Set dependencies between tasks
Click the plus sign on the right of the task node to connect the task; as shown in the figure below, task Node_B and task Node_C execute in parallel, When task Node_A finished execution, tasks Node_B and Node_C will execute simultaneously.
-**Delete dependencies:** Click the "arrow" icon in the upper right corner <imgsrc="../../../../img/arrow.png"width="35"/>, select the connection line, and click the "Delete" icon in the upper right corner <imgsrc= "../../../../img/delete.png"width="35"/>, delete dependencies between tasks.
**Delete dependencies:** Using your mouse to select the connection line, and click the "Delete" icon in the upper right corner <imgsrc= "../../../../img/delete.png"width="35"/>, delete dependencies between tasks.
-**Save workflow definition:** Click the `Save` button, and the "Set DAG chart name" window pops up, as shown in the figure below. Enter the workflow definition name, workflow definition description, and set global parameters (optional, refer to [global parameters](../parameter/global.md)), click the `Add` button to finish workflow definition creation.
Click the `Save` button, and the "Set DAG chart name" window pops up, as shown in the figure below. Enter the workflow definition name, workflow definition description, and set global parameters (optional, refer to [global parameters](../parameter/global.md)), click the `Add` button to finish workflow definition creation.
> For other types of tasks, please refer to [Task Node Type and Parameter Settings](#TaskParamers). <!-- markdown-link-check-disable-line -->
***Failure strategy**: When a task node fails to execute, other parallel task nodes need to execute the strategy. "Continue" means: After a task fails, other task nodes execute normally; "End" means: Terminate all tasks being executed, and terminate the entire process.
***Notification strategy**: When the process ends, send process execution information notification emails according to the process status, including no status, success, failure, success or failure.
***Process priority**: the priority of process operation, divided into five levels: the highest (HIGHEST), high (HIGH), medium (MEDIUM), low (LOW), the lowest (LOWEST). When the number of master threads is insufficient, processes with higher levels will be executed first in the execution queue, and processes with the same priority will be executed in the order of first-in, first-out.
***Worker grouping**: This process can only be executed in the specified worker machine group. The default is Default, which can be executed on any worker.
***Notification Group**: Select Notification Policy||Timeout Alarm||When fault tolerance occurs, process information or emails will be sent to all members in the notification group.
***Recipient**: Select Notification Policy||Timeout Alarm||When fault tolerance occurs, process information or alarm email will be sent to the recipient list.
***Cc**: Select Notification Policy||Timeout Alarm||When fault tolerance occurs, the process information or alarm email will be copied to the Cc list.
***Startup parameters**: Set or override the value of global parameters when starting a new process instance.
***Complement**: There are 2 modes of serial complement and parallel complement. Serial complement: within the specified time range, perform complements in sequence from the start date to the end date, and generate N process instances in turn; parallel complement: within the specified time range, perform multiple complements at the same time, and generate N process instances at the same time .
***Complement**: Execute the workflow definition of the specified date, you can select the time range of the supplement (currently only supports the supplement for consecutive days), for example, the data from May 1st to May 10th needs to be supplemented, as shown in the following figure:
The following are the operation functions of the workflow definition list:
-**Edit:** Only "Offline" workflow definitions can be edited. Workflow DAG editing is the same as [Create Workflow Definition](#creatDag)<!-- markdown-link-check-disable-line -->
-**Edit:** Only "Offline" workflow definitions can be edited. Workflow DAG editing is the same as [Create Workflow Definition](#create-workflow-definition)
-**Online:** When the workflow status is "Offline", used to make workflow online. Only the workflow in the "Online" state can run, but cannot edit.
-**Offline:** When the workflow status is "Online", used to make workflow offline. Only the workflow in the "Offline" state can be edited, but cannot run.
-**Run:** Only workflow in the online state can run. See [2.3.3 Run Workflow](#run-the-workflow) for the operation steps.
-**Timing:** Timing can only set to online workflows, and the system automatically schedules to run the workflow on time. The status after creating a timing setting is "offline", and the timing must set online on the timing management page to make effect. See [2.3.4 Workflow Timing](#workflow-timing) for timing operation steps.
-**Run:** Only workflow in the online state can run. See [Run Workflow](#run-the-workflow) for the operation steps.
-**Timing:** Timing can only set to online workflows, and the system automatically schedules to run the workflow on time. The status after creating a timing setting is "offline", and the timing must set online on the timing management page to make effect. See [Workflow Timing](#workflow-schedule) for timing operation steps.
-**Timing Management:** The timing management page can edit, online or offline and delete timing.
-**Delete:** Delete the workflow definition. In the same project, only the workflow definition created by yourself can be deleted, and the workflow definition of other users cannot be deleted. If you need to delete it, please contact the user who created it or the administrator.
-**Download:** Download workflow definition to local.
...
...
@@ -102,20 +125,20 @@ The following are the operation functions of the workflow definition list:
- Create timing: Click `Project Management -> Workflow-> Workflow Definition`, enter the workflow definition page, make the workflow online, click the "timing" button <imgsrc="../../../../img/timing.png"width="35"/> , the timing parameter setting dialog box pops up, as shown in the figure below:
- Create schedule: Click `Project Management -> Workflow-> Workflow Definition`, enter the workflow definition page, make the workflow online, click the "timing" button <imgsrc="../../../../img/timing.png"width="35"/> , the timing parameter setting dialog box pops up, as shown in the figure below:
-Choose the start and end time. In the time range, the workflow runs at regular intervals; If not in the time range, no regular workflow instances generate.
-Select a start and end time. Within the start and end time range, the workflow is run regularly; outside the start and end time range, no timed workflow instance will be generated.
- Add a timing that execute 5 minutes once, as shown in the following figure:
- Failure strategy, notification strategy, process priority, worker group, notification group, recipient, and CC are the same as workflow running parameters.
- Click the "Create" button to create the timing. Now the timing status is "**Offline**" and the timing needs to be **Online** to make effect.
-Timing online: Click the `Timing Management` button <imgsrc="../../../../img/timeManagement.png"width="35"/>, enter the timing management page, click the `online` button, the timing status will change to `online`, as shown in the below figure, the workflow makes effect regularly.
-Schedule online: Click the `Timing Management` button <imgsrc="../../../../img/timeManagement.png"width="35"/>, enter the timing management page, click the `online` button, the timing status will change to `online`, as shown in the below figure, the workflow makes effect regularly.
-Click "View Log", a log window pops up, as shown in the figure below, you can also view the task log on the task instance page, refer to [Task View Log](./task-instance.md)
Click "View Log", a log window pops up, as shown in the figure below, you can also view the task log on the task instance page, refer to [Task View Log](./task-instance.md)
- Click `Project Management -> Workflow -> Workflow Instance`, enter the workflow instance page, and click the workflow name to enter the workflow DAG page;
- Double-click the task node, as shown in the figure below, click `View History` to jump to the task instance page, and display a list of task instances running by the workflow instance.
Click `Project Management -> Workflow -> Workflow Instance` to enter the workflow instance page, click the workflow name to enter the workflow DAG page;
Double-click the task node, click `View History` to jump to the task instance page, and display the list of task instances run by the workflow instance.
Click `Project Management -> Workflow -> Workflow Instance` to enter the workflow instance page, click the workflow name to enter the workflow DAG page;
- Click `Project Management -> Workflow -> Workflow Instance`, enter the workflow instance page, and click the workflow name to enter the workflow DAG page;
- Click the icon in the upper left corner <imgsrc="../../../../img/run_params_button.png"width="35"/>,View the startup parameters of the workflow instance; click the icon <imgsrc="../../../../img/global_param.png"width="35"/>,View the global and local parameters of the workflow instance, as shown in the following figure:
Click the icon in the upper left corner <imgsrc="../../../../img/run_params_button.png"width="35"/> to view the startup parameters of the workflow instance; click the icon <imgsrc="../../../../img/global_param.png"width="35"/> to view the global parameters and local parameters of the workflow instance, as shown in the following figure:
-**Edit:** only processes with success/failed/stop status can be edited. Click the "Edit" button or the workflow instance name to enter the DAG edit page. After the edit, click the "Save" button to confirm, as shown in the figure below. In the pop-up box, check "Whether to update the workflow definition", after saving, the information modified by the instance will be updated to the workflow definition; if not checked, the workflow definition would not be updated.
-**Edit:** Only processes with success/failed/stop status can be edited. Click the "Edit" button or the workflow instance name to enter the DAG edit page. After the edit, click the "Save" button to confirm, as shown in the figure below. In the pop-up box, check "Whether to update the workflow definition", after saving, the information modified by the instance will be updated to the workflow definition; if not checked, the workflow definition would not be updated.
-**Recovery failed:** for failed processes, you can perform failure recovery operations, starting from the failed node
-**Stop:** to **stop** the running process, the background code will first `kill` the worker process, and then execute `kill -9` operation
-**Pause:**Perform a **pause** operation on the running process, the system status will change to **waiting for execution**, it will wait for the task to finish, and pause the next sequence task.
-**Resume pause:**to resume the paused process, start running directly from the **paused node**
-**Delete:**delete the workflow instance and the task instance under the workflow instance
-**Gantt chart:** the vertical axis of the Gantt chart is the topological sorting of task instances of the workflow instance, and the horizontal axis is the running time of the task instances, as shown in the figure below:
-**Rerun:**Re-execute the terminated process
-**Recovery Failed:** For failed processes, you can perform failure recovery operations, starting from the failed node
-**Stop:****Stop** the running process, the background code will first `kill` the worker process, and then execute `kill -9` operation
-**Pause:****Pause** the running process, the system status will change to **waiting for execution**, it will wait for the task to finish, and pause the next sequence task.
-**Resume pause:**Resume the paused process, start running directly from the **paused node**
-**Delete:**Delete the workflow instance and the task instance under the workflow instance
-**Gantt Chart:** The vertical axis of the Gantt chart is the topological sorting of task instances of the workflow instance, and the horizontal axis is the running time of the task instances, as shown in the figure:
When third party jars are used in the scheduling process or user defined scripts are required, these can be created from this page. The types of files that can be created include: txt, log, sh, conf, py, java and so on. Files can be edited, renamed, downloaded and deleted.
When the third-party jar needs to be used in the scheduling process or the user needs to customize the script, the related operations can be completed on this page. The file types that can be created include: `txt`, `log`, `sh`, `conf`, `py`, `java` etc. And you can edit, rename, download and delete files.
Click the "Re-upload File" button in the file list to re-upload the file, drag and drop the file to the upload area, and the file name will be automatically completed with the uploaded file name.
> Click the "Download" button in the file list to download the file or click the "Download" button in the upper right corner of the file details to download the file.
Click the "Download" button in the file list to download the file or click the "Download" button in the upper right corner of the file details to download the file.
### Rename File
...
...
@@ -40,18 +46,12 @@ Click the "Upload File" button to upload, drag the file to the upload area, the
File list -> Click the "Delete" button to delete the specified file.
### Re-upload file
Click the "Re-upload File" button to upload a new file to replace the old file, drag the file to the re-upload area, the file name will be automatically completed with the new uploaded file name.
> Note: File name or source name of your local file can not contain specific characters like `.` or `/` when you trying to
> upload, create or rename file in resource center.
## Example
The example uses a simple shell script to demonstrate the use of resource center files in workflow definitions. The same is true for tasks such as MR and Spark, which require jar packages.
This sample mainly uses a simple shell script to demonstrate how to use Content Center files in a workflow definition. The same is true for tasks such as MR and Spark that require jar packages.
The task group is mainly used to control the concurrency of task instances and is designed to control the pressure of other resources (it can also control the pressure of the Hadoop cluster, the cluster will have queue control it). When creating a new task definition, you can configure the corresponding task group and configure the priority of the task running in the task group.
The task group is mainly used to control the concurrency of task instances, and is designed to control the pressure of other resources (it can also control the pressure of the Hadoop cluster, the cluster will have queue control it). When creating a new task definition, you can configure the corresponding task group and configure the priority of the task running in the task group.
## Task Group Configuration
...
...
@@ -8,17 +8,15 @@ The task group is mainly used to control the concurrency of task instances and i
You need to enter the information inside the picture:
- Task group name: the name displayed of the task group
- Project name: the project range that the task group functions, this item is optional, if not selected, all the projects in the whole system can use this task group.
- Resource pool size: The maximum number of concurrent task instances allowed.
-**Task group name**: The name displayed when the task group is used
-**Project name**: The project that the task group functions, this item is optional, if not selected, all the projects in the whole system can use this task group.
-**Resource pool size**: The maximum number of concurrent task instances allowed.
### View Task Group Queue
...
...
@@ -30,7 +28,9 @@ Click the button to view task group usage information:
### Use of Task Groups
**Note**: The usage of task groups is applicable to tasks executed by workers, such as [switch] nodes, [condition] nodes, [sub_process] and other node types executed by the master are not controlled by the task group. Let's take the shell node as an example:
**Note**: The use of task groups is applicable to tasks executed by workers, such as `switch` nodes, `condition` nodes, `sub_process` and other node types executed by the master are not controlled by the task group.
The resource management and file management functions are similar. The difference is that the resource management is the UDF upload function, and the file management uploads the user programs, scripts and configuration files. Operation function: rename, download, delete.
## Resource Management
- The resource management and file management functions are similar. The difference is that the resource management is the UDF upload function, and the file management uploads the user programs, scripts and configuration files.
- It mainly includes the following operations: rename, download, delete, etc.
- Upload UDF resources: Same as uploading files.
## Function Management
- Create UDF function
### Create UDF function
> Click `Create UDF Function`, enter the UDF function parameters, select the UDF resource, and click `Submit` to create the UDF function.
> Currently, only supports temporary UDF functions of `HIVE`.
Click `Create UDF Function`, enter the UDF function parameters, select the UDF resource, and click `Submit` to create the UDF function.
Currently only temporary UDF functions for HIVE are supported.
- UDF function name: Enter the name of the UDF function.
- Package name Class name: Enter the full path of the UDF function.
...
...
@@ -21,21 +23,21 @@ The resource management and file management functions are similar. The differenc
### Write UDF functions
You can customize UDF functions based on actual production requirements. Write a function that adds "HelloWorld" to the end of any string. As shown below:
Users can customize the desired UDF function according to actual production requirements. Here's a function that appends "HelloWorld" to the end of any string. As shown below:
Before configuring the UDF function, upload the jar package of the UDF function through resource management. Then enter function management and configure related information. As shown below:
Before configuring UDF functions, you need to upload the required function jar package through resource management. Then enter the function management and configure the relevant information. As shown below:
When using UDF functions, you only need to write specific functions and upload the configuration through the resource center. The system automatically configures the create function statement as follows: [SqlTask](https://github.com/apache/dolphinscheduler/blob/923f3f38e3271d7f1d22b3abc3497cecb6957e4a/dolphinscheduler-task-plugin/dolphinscheduler-task-sql/src/main/java/org/apache/dolphinscheduler/plugin/task/sql/SqlTask.java#L507-L531)
In the process of using UDF functions, users only need to pay attention to the specific function writing, and upload the configuration through the resource center. The system will automatically configure the create function statement, refer to the following: [SqlTask](https://github.com/apache/dolphinscheduler/blob/923f3f38e3271d7f1d22b3abc3497cecb6957e4a/dolphinscheduler-task-plugin/dolphinscheduler-task-sql/src/main/java/org/apache/dolphinscheduler/plugin/task/sql/SqlTask.java#L507-L531)
Enter the workflow and define an SQL node. Set the data source type to HIVE and the data source instance type to HIVE/IMPALA.
Enter the workflow to define an SQL node, the data source type is HIVE, and the data source instance type is HIVE/IMPALA.
- SQL statement: `select HwUdf("abc");` This function is used in the same way as the built-in functions, and can be accessed directly using the function name.
- UDF function: Select the one configured for the resource center.
- Only the administrator account in the security center has the authority to operate. It has functions such as queue management, tenant management, user management, alarm group management, worker group management, token management, etc. In the user management module, can authorize to the resources, data sources, projects, etc.
- Administrator login, the default username and password is `admin/dolphinscheduler123`.
Only the administrator account in the security center has permission to operate, which includes queue management, tenant management, user management, alarm group management, worker group management, token management and other functions. In the user management module, you can authorize resources, data sources, projects, etc.
- The tenant corresponds to the Linux user, which is used by the worker to submit the job. The task will fail if Linux does not have this user exists. You can set the parameter `worker.tenant.auto.create` as `true` in configuration file `worker.properties`. After that DolphinScheduler will create a user if not exists, The property `worker.tenant.auto.create=true` requests worker run `sudo` command without password.
- Tenant Code: **Tenant Code is the only user on Linux and cannot be repeated**
- The administrator enters the `Security Center->Tenant Management` page and clicks the `Create Tenant` button to create a tenant.
- The tenant corresponds to the Linux user, which is used by the worker to submit the job. If linux does not have this user, it will cause the task to fail. You can automatically create a linux user when the user does not exist by modifying the parameters in the `worker.properties` configuration file. The parameter will require that the worker can run the command `worker.tenant.auto.create = true; worker.tenant.auto.create = truesudo`
- Tenant Code: **The tenant code is the user on Linux, unique and cannot be repeated**
- The administrator enters the `Security Center->Tenant Management` page, and clicks the `Create Tenant` button to create a tenant.
- Users are divided into **administrator users** and **normal users**
Users are divided into **administrator users** and **ordinary users**
- The administrator has authorization to authorize and user management authorities but does not have the authority to create project and workflow definition operations.
- Normal users can create projects and create, edit and execute workflow definitions.
-**Note**: If the user switches tenants, all resources under the tenant to which the user belongs will be copied to the new tenant that is switched.
- Administrators have permissions such as authorization and user management, but do not have permissions to create projects and actions defined by workflows.
- Ordinary users can create projects and create, edit, and execute workflow definitions.
-**Note**: If the user switches tenants, all resources under the tenant to which the user belongs will be copied to the new tenant that is switched.
- The administrator enters the `Security Center -> User Management` page and clicks the `Create User` button to create a user.
Go to the `Security Center -> User Management` page and click the `Create User` button to create a user, administrator only.
The administrator enters the `Security Center->User Management` page and clicks the `Edit` button to edit user information.
After logging in as an ordinary user, click the user information in the drop-down box of the user name to enter the user information page, and click the `Edit` button to edit the user information.
- The administrator enters the `Security Center->User Management` page and clicks the `Edit` button to edit user information.
- After a normal user logs in, click the user information in the username drop-down box to enter the user information page, and click the `Edit` button to edit the user information.
### Modify user password
> **Modify user password**
The administrator enters the `Security Center -> User Management` page and clicks the `Edit` button. When editing user information, enter the new password to modify the user password.
- The administrator enters the `Security Center->User Management` page and clicks the `Edit` button. When editing user information, enter the new password to modify the user password.
- After a normal user logs in, click the user information in the username drop-down box to enter the password modification page, enter the password and confirm the password and click the `Edit` button, then the password modification is a success.
After logging in as an ordinary user, click the user information in the user name drop-down box to enter the password modification page, enter the password and confirm the password and click the `Edit` button, then the password modification is successful.
## Create Alarm Group
-The alarm group is a parameter set at startup. After the process ends, the status of the process and other information will be sent to the alarm group by email.
The alarm group is a parameter set at startup. After the process ends, the status of the process and other information will be sent to the alarm group by email.
*The administrator enters the `Security Center -> Alarm Group Management` page and clicks the `Create Alarm Group` button to create an alarm group.
The administrator enters the `Security Center -> Alarm Group Management` page and clicks the `Create Alarm Group` button to create an alarm group.
Since the back-end interface has login check, token management provides a way to execute various operations on the system by calling interfaces.
Since the back-end interface has a login check, token management provides a way to perform various operations on the system by calling the interface.
-The administrator enters the `Security Center -> Token Management page`, clicks the `Create Token` button, selects the expiration time and user, clicks the `Generate Token` button, and clicks the `Submit` button, then create the selected user's token successfully.
The administrator enters the `Security Center -> Token Management page`, clicks the `Create Token` button, selects the expiration time and user, clicks the `Generate Token` button, and clicks the `Submit` button, then create the selected user's token successfully.
- After a normal user logs in, click the user information in the username drop-down box, enter the token management page, select the expiration time, click the `Generate Token` button, and click the `Submit` button, then the user creates a token successfully.
- Call example:
After a normal user logs in, click the user information in the username drop-down box, enter the token management page, select the expiration time, click the `Generate Token` button, and click the `Submit` button, then the user creates a token successfully.
- Granted permissions include project permissions, resource permissions, data source permissions, UDF function permissions.
- The administrator can authorize the projects, resources, data sources and UDF functions to normal users which not created by them. Because the way to authorize projects, resources, data sources and UDF functions to users is the same, we take project authorization as an example.
- Note: The user has all permissions to the projects created by them. Projects will not be displayed in the project list and the selected project list.
- Granted permissions include project permissions, resource permissions, data source permissions, and UDF function permissions.
- Administrators can authorize projects, resources, data sources, and UDF functions that ordinary users do not create. Because the authorization methods of projects, resources, data sources and UDF functions are all the same, the project authorization is used as an example to introduce.
- Note: For projects created by the user, the user has all permissions. The item list and the selected items list are not displayed.
- The administrator enters the `Security Center -> User Management` page, and clicks the "Authorize" button of the user to be authorized, as shown in the following figure:
- The administrator enters the `Security Center -> User Management` page and clicks the `Authorize` button of the user who needs to be authorized, as shown in the figure below:
- Resources, data sources, and UDF function authorization are the same as project authorization.
...
...
@@ -116,35 +120,35 @@ Since the back-end interface has login check, token management provides a way to
Each worker node will belong to its own worker group, and the default group is "default".
When executing a task, the task can be assigned to the specified worker group, and the task will be executed by the worker node in the group.
When the task is executed, the task can be assigned to the specified worker group, and finally the worker node in the group will execute the task.
> Add or update worker group
### Add or update worker group
- Open the `conf/worker.properties` configuration file on the worker node where you want to configure the groups and modify the `worker.groups` parameter.
- The `worker.groups` parameter is followed by the name of the group corresponding to the worker node, which is `default`.
- If the worker node corresponds to more than one group, they are separated by commas.
- If the worker node corresponds to multiple groups, separate them with commas. Example:
```conf
worker.groups=default,test
```
- You can also change the worker group for the worker during execution, and if the modification is successful, the worker will use the new group and ignore the configuration in `worker.properties`. The step to modify work group as below: `Security Center -> Worker Group Management -> click 'New Worker Group' -> click 'New Worker Group' -> enter 'Group Name' -> Select Exists Worker -> Click Submit`.
## Environmental Management
* Configure the Worker operating environment online. A Worker can specify multiple environments, and each environment is equivalent to the `dolphinscheduler_env.sh` file.
* The default environment is the `dolphinscheduler_env.sh` file.
- Configure the worker running environment online, a worker can specify multiple environments, each environment is equivalent to the `dolphinscheduler_env.sh` file.
- The default environment is the `dolphinscheduler_env.sh` file.
- When the task is executed, the task can be assigned to the specified worker group, and the corresponding environment can be selected according to the worker group, and finally the worker node in the group executes the environment and then executes the task.
* When executing a task, the task can be assigned to the specified worker group, and select the corresponding environment according to the worker group. Finally, the worker node executes the environment first and then executes the task.
### Add or update environment
> Add or update environment
- The environment configuration is equivalent to the configuration in the `dolphinscheduler_env.sh` file.
The environment configuration is equivalent to the configuration in the `dolphinscheduler_env.sh` file.
- Create a task node in the workflow definition, select the worker group and the environment corresponding to the worker group. When executing the task, the Worker will execute the environment first before executing the task.
### Usage environment
Create a task node in the workflow definition, select the worker group and the environment corresponding to the worker group. When executing the task, the Worker will execute the environment first before executing the task.
This is a Quick Start guide to help you get a basic idea of working with Apache DolphinScheduler. Once you've gone through the tutorial video, we encourage you to find out more about Apache DolphinScheduler functions and examples in .
After you finish creating the workflow, you can run the workflow online. You can view the execution status of each task on the workflow instance page. As shown below:
@@ -15,36 +15,36 @@ Flink task type, used to execute Flink programs. For Flink nodes:
## Task Parameters
| **Parameter**| **Description** |
| ------- | ---------- |
| Node name | The node name in a workflow definition is unique. |
| Run flag | Identifies whether this node schedules normally, if it does not need to execute, select the `prohibition execution`. |
| Description | Describe the function of the node. |
| Task priority | When the number of worker threads is insufficient, execute in the order of priority from high to low, and tasks with the same priority will execute in a first-in first-out order. |
| Worker grouping | Assign tasks to the machines of the worker group to execute. If `Default` is selected, randomly select a worker machine for execution. |
| Environment Name | Configure the environment name in which run the script. |
| Times of failed retry attempts | The number of times the task failed to resubmit. |
| Failed retry interval | The time interval (unit minute) for resubmitting the task after a failed task. |
| Delayed execution time | The time (unit minute) that a task delays in execution. |
| Timeout alarm | Check the timeout alarm and timeout failure. When the task runs exceed the "timeout", an alarm email will send and the task execution will fail. |
| Program type | Support Java, Scala, Python and SQL four languages. |
| Class of main function**: The **full path** of Main Class, the entry point of the Flink program. |
| Main jar package | The jar package of the Flink program (upload by Resource Center). |
| Deployment mode | Support 3 deployment modes: cluster, local and application (Flink 1.11 and later. See also [Run an application in Application Mode](https://nightlies.apache.org/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html#run-an-application-in-application-mode)). |
| Node name | The node name in a workflow definition is unique. |
| Run flag | Identifies whether this node schedules normally, if it does not need to execute, select the `prohibition execution`. |
| Description | Describe the function of the node. |
| Task priority | When the number of worker threads is insufficient, execute in the order of priority from high to low, and tasks with the same priority will execute in a first-in first-out order. |
| Worker grouping | Assign tasks to the machines of the worker group to execute. If `Default` is selected, randomly select a worker machine for execution. |
| Environment Name | Configure the environment name in which run the script. |
| Times of failed retry attempts | The number of times the task failed to resubmit. |
| Failed retry interval | The time interval (unit minute) for resubmitting the task after a failed task. |
| Delayed execution time | The time (unit minute) that a task delays in execution. |
| Timeout alarm | Check the timeout alarm and timeout failure. When the task runs exceed the "timeout", an alarm email will send and the task execution will fail. |
| Program type | Support Java, Scala, Python and SQL four languages. |
| Class of main function | The **full path** of Main Class, the entry point of the Flink program. |
| Main jar package | The jar package of the Flink program (upload by Resource Center). |
| Deployment mode | Support 3 deployment modes: cluster, local and application (Flink 1.11 and later. See also [Run an application in Application Mode](https://nightlies.apache.org/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html#run-an-application-in-application-mode)). |
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
