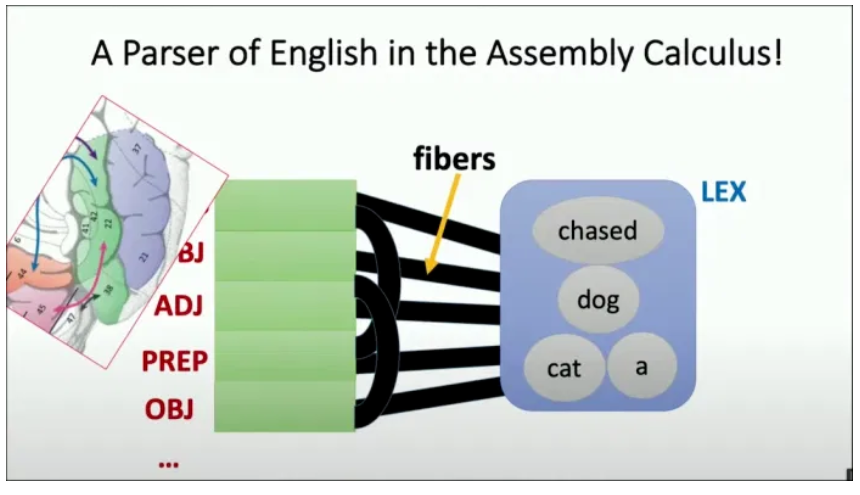
大脑模拟NLP,高德纳奖得主Papadimitriou:神经元集合演算用于句子解析
Showing
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:
| W: | H:
imgs/4.gif
已删除
100644 → 0
{kind=link}
1.6 MB
imgs/4.png
0 → 100644
{kind=link}
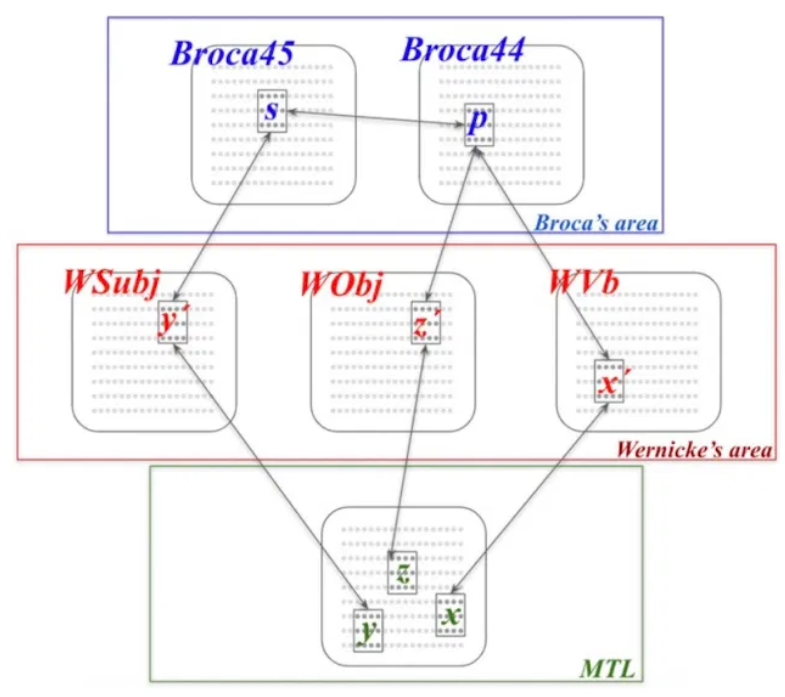
211.9 KB
imgs/5.png
已删除
100644 → 0
{kind=link}
50.2 KB
imgs/6.png
已删除
100644 → 0
{kind=link}
167.1 KB