We want the building procedure generates Docker images, so we can run PaddlePaddle applications on Kubernetes clusters.
We want it generates .deb packages, so that enterprises without Docker support can run PaddlePaddle applications as well.
We want to minimize the size of generated Docker images and .deb packages so to ease the deployment cost.
We want to encapsulate building tools and dependencies in a *development* Docker image so to ease the tools installation for developers.
We want developers can use whatever editing tools (emacs, vim, Eclipse, Jupyter Notebook), so the development Docker image contains only building tools, not editing tools, and developers are supposed to git clone source code into their development computers, instead of the container running the development Docker image.
We want the procedure and tools work also with testing, continuous integration, and releasing.
## Docker Images
We want two Docker images for each version of PaddlePaddle:
1.`paddle:<version>-dev`
This a development image contains only the development tools. This standardizes the building tools and procedure. Users include:
- developers -- no longer need to install development tools on the host, and can build their current work on the host (development computer).
- release engineers -- use this to build the official release from certain branch/tag on Github.com.
- document writers / Website developers -- Our documents are in the source repo in the form of .md/.rst files and comments in source code. We need tools to extract the information, typeset, and generate Web pages.
Of course developers can install building tools on their development computers. But different version of PaddlePaddle might require different set/version of building tools. Also, it makes collaborative debugging eaiser if all developers use a unified development environment.
The development image should include the following tools:
- gcc/clang
- nvcc
- Python
- sphinx
- woboq
- sshd
where `sshd` makes it easy for developers to have multiple terminals connecting into the container. `docker exec` works too, but if the container is running on a remote machine, it would be easier to ssh directly into the container than ssh to the box and run `docker exec`.
1.`paddle:<version>`
This is the production image, generated using the development image. This image might have multiple variants:
- GPU/AVX `paddle:<version>-gpu`
- GPU/no-AVX `paddle:<version>-gpu-noavx`
- no-GPU/AVX `paddle:<version>`
- no-GPU/no-AVX `paddle:<version>-noavx`
We'd like to give users the choice between GPU and no-GPU, because the GPU version image is much larger than then the no-GPU version.
We'd like to give users the choice between AVX and no-AVX, because some cloud providers don't provide AVX-enabled VMs.
## Development Environment
Here we describe how to use above two images. We start from considering our daily development environment.
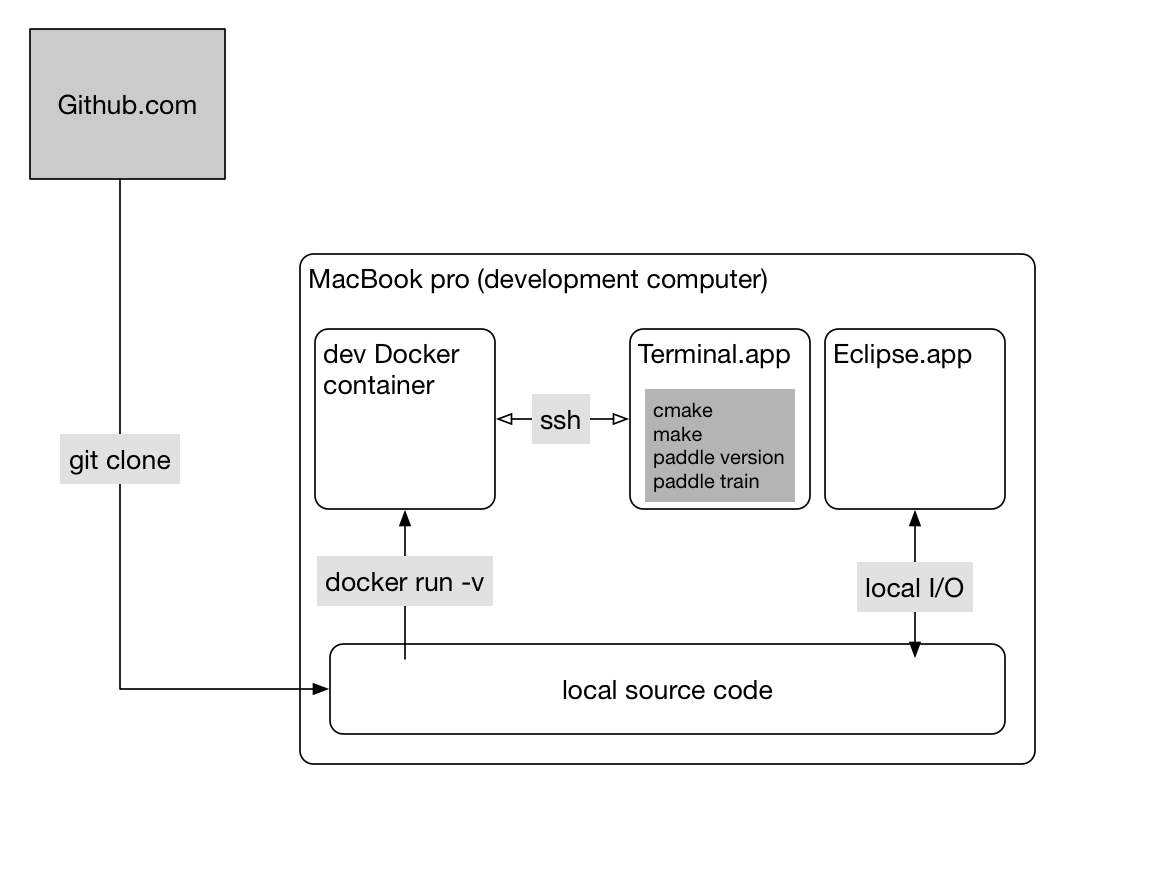
Developers work on a computer, which is usually a laptop or desktop:

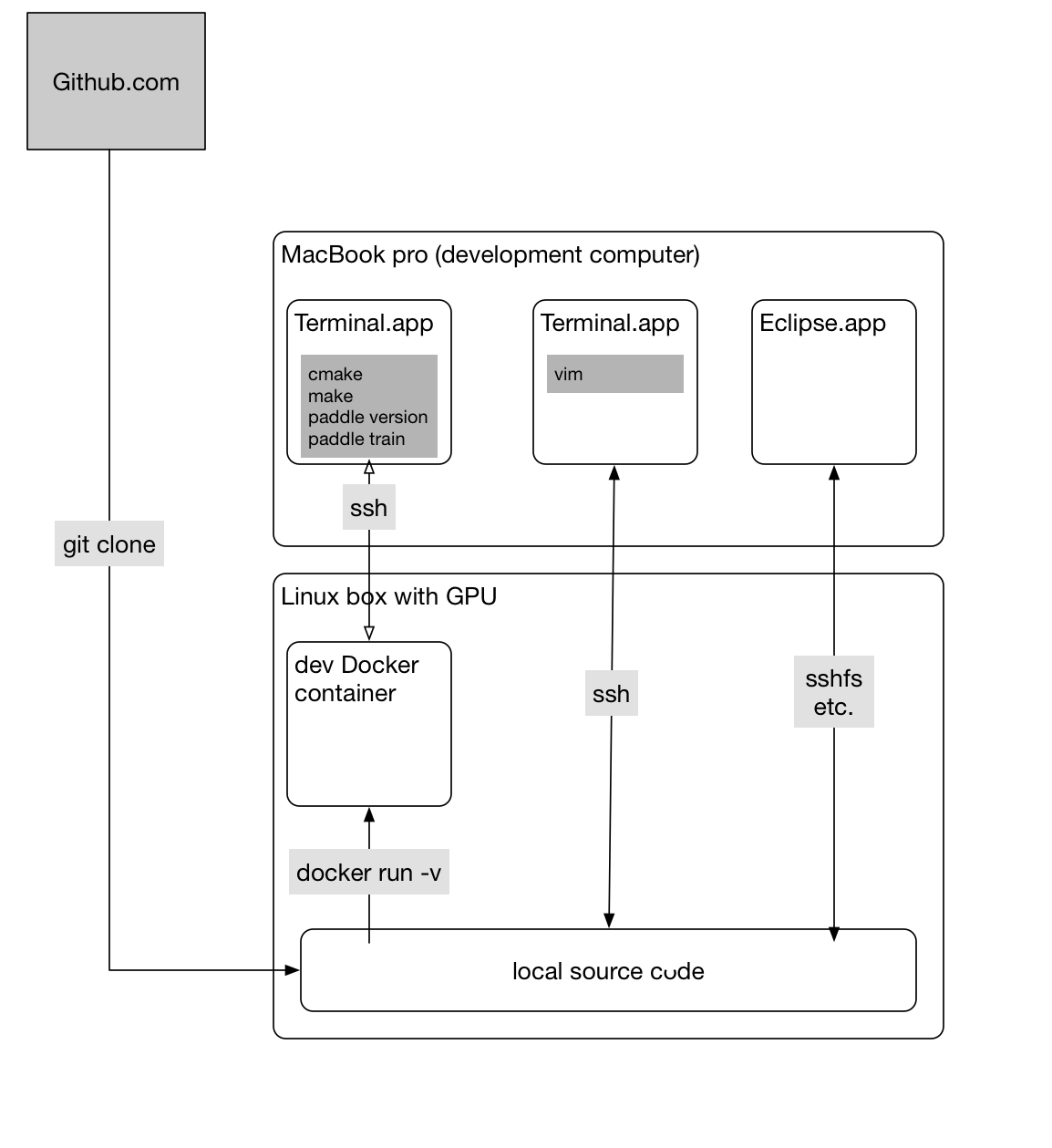
or, they might rely on a more sophisticated box (like with GPUs):

A basic principle is that source code lies on the development computer (host), so that editing tools like Eclipse can parse the source code and support auto-completion.
## Usages
### Build the Development Docker Image
The following commands check out the source code on the development computer (host) and build the development image `paddle:dev`:
The `docker build` command assumes that `Dockerfile` is in the root source tree. This is reasonable because this Dockerfile is this only on in our repo in this design.
### Build PaddlePaddle from Source Code
Given the development image `paddle:dev`, the following command builds PaddlePaddle from the source tree on the development computer (host):
```bash
docker run -v$PWD:/paddle -e"GPU=OFF"-e"AVX=ON"-e"TEST=ON" paddle:dev
```
This command mounts the source directory on the host into `/paddle` in the container, so the default entrypoint of `paddle:dev`, `build.sh`, would build the source code with possible local changes. When it writes to `/paddle/build` in the container, it actually writes to `$PWD/build` on the host.
`build.sh` builds the following:
- PaddlePaddle binaries,
-`$PWD/build/paddle-<version>.deb` for production installation, and
-`$PWD/build/Dockerfile`, which builds the production Docker image.
### Build the Production Docker Image
The following command builds the production image:
```bash
docker build -t paddle -f build/Dockerfile .
```
This production image is minimal -- it includes binary `paddle`, the share library `libpaddle.so`, and Python runtime.
### Run PaddlePaddle Applications
Again the development happens on the host. Suppoose that we have a simple application program in `a.py`, we can test and run it using the production image:
```bash
docker run -it-v$PWD:/work paddle /work/a.py
```
But this works only if all dependencies of `a.py` are in the production image. If this is not the case, we need to build a new Docker image from the production image and with more dependencies installs.
### Build and Run PaddlePaddle Appications
We need a Dockerfile in https://github.com/paddlepaddle/book that builds Docker image `paddlepaddle/book:<version>`, basing on the PaddlePaddle production image:
```
FROM paddlepaddle/paddle:<version>
RUN pip install -U matplotlib jupyter ...
COPY . /book
EXPOSE 8080
CMD ["jupyter"]
```
The book image is an example of PaddlePaddle application image. We can build it
```bash
git clone https://github.com/paddlepaddle/book
cd book
docker build -t book .
```
### Build and Run Distributed Applications
In our [API design doc](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/api.md#distributed-training), we proposed an API that starts a distributed training job on a cluster. This API need to build a PaddlePaddle application into a Docekr image as above, and calls kubectl to run it on the cluster. This API might need to generate a Dockerfile look like above and call `docker build`.
Of course, we can manually build an application image and launch the job using the kubectl tool:
{kind=link}
{kind=link}