Add benchmark config and document
Showing
benchmark/README.md
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
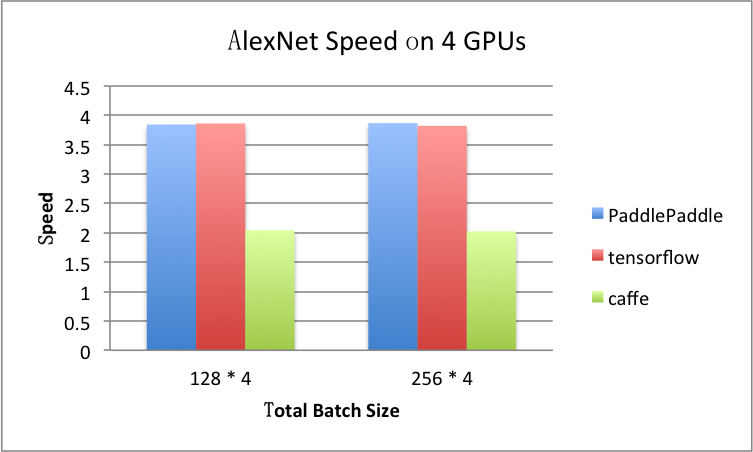
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
80.1 KB
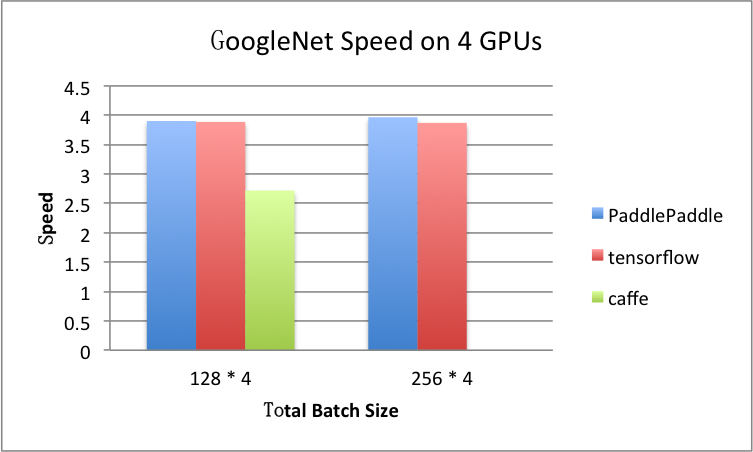
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}
80.6 KB
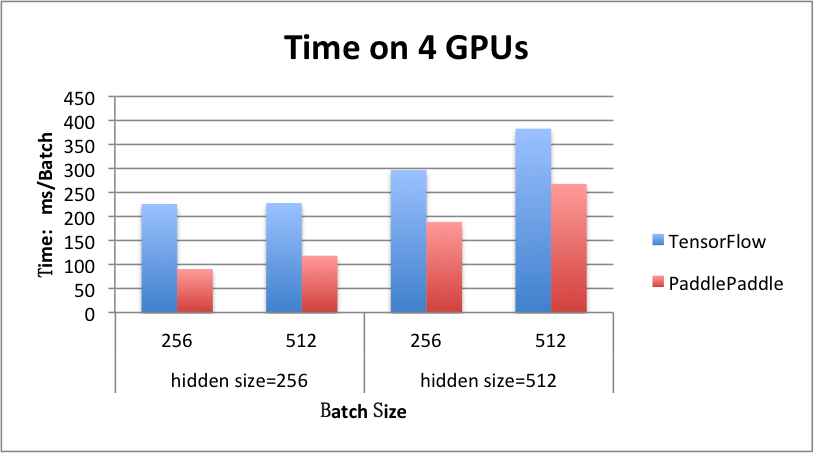
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}

114.9 KB
benchmark/paddle/image/alexnet.py
0 → 100644
benchmark/paddle/image/run.sh
0 → 100755
benchmark/paddle/rnn/imdb.py
0 → 100755
benchmark/paddle/rnn/provider.py
0 → 100644
benchmark/paddle/rnn/rnn.py
0 → 100755
benchmark/paddle/rnn/run.sh
0 → 100755
benchmark/paddle/rnn/run_multi.sh
0 → 100755
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。