Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
TonyTonyFun
Paddle
提交
9eaf4458
P
Paddle
项目概览
TonyTonyFun
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
9eaf4458
编写于
4月 08, 2018
作者:
Y
Yancey1989
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of github.com:PaddlePaddle/Paddle into prefech_prog_on_server
上级
f132f51e
3874c383
变更
146
展开全部
隐藏空白更改
内联
并排
Showing
146 changed file
with
2086 addition
and
1421 deletion
+2086
-1421
.gitignore
.gitignore
+0
-9
cmake/external/mklml.cmake
cmake/external/mklml.cmake
+1
-1
cmake/external/snappystream.cmake
cmake/external/snappystream.cmake
+3
-1
cmake/external/warpctc.cmake
cmake/external/warpctc.cmake
+2
-1
cmake/external/zlib.cmake
cmake/external/zlib.cmake
+2
-1
cmake/generic.cmake
cmake/generic.cmake
+3
-3
doc/design/file_manager/README.md
doc/design/file_manager/README.md
+0
-87
doc/design/file_manager/pfs/pfsclient.md
doc/design/file_manager/pfs/pfsclient.md
+0
-129
doc/design/file_manager/src/filemanager.graffle
doc/design/file_manager/src/filemanager.graffle
+0
-0
doc/design/file_manager/src/filemanager.png
doc/design/file_manager/src/filemanager.png
+0
-0
doc/fluid/CMakeLists.txt
doc/fluid/CMakeLists.txt
+2
-2
doc/fluid/api/CMakeLists.txt
doc/fluid/api/CMakeLists.txt
+1
-1
doc/fluid/dev/index_cn.rst
doc/fluid/dev/index_cn.rst
+1
-1
doc/fluid/dev/index_en.rst
doc/fluid/dev/index_en.rst
+1
-1
doc/fluid/dev/releasing_process_cn.md
doc/fluid/dev/releasing_process_cn.md
+30
-24
doc/fluid/dev/releasing_process_en.md
doc/fluid/dev/releasing_process_en.md
+210
-0
doc/templates/conf.py.cn.in
doc/templates/conf.py.cn.in
+1
-1
doc/templates/conf.py.en.in
doc/templates/conf.py.en.in
+1
-1
doc/v2/CMakeLists.txt
doc/v2/CMakeLists.txt
+2
-2
doc/v2/api/CMakeLists.txt
doc/v2/api/CMakeLists.txt
+1
-1
paddle/api/CMakeLists.txt
paddle/api/CMakeLists.txt
+6
-5
paddle/api/test/CMakeLists.txt
paddle/api/test/CMakeLists.txt
+5
-0
paddle/fluid/.clang-format
paddle/fluid/.clang-format
+0
-0
paddle/fluid/framework/CMakeLists.txt
paddle/fluid/framework/CMakeLists.txt
+2
-2
paddle/fluid/framework/block_desc.h
paddle/fluid/framework/block_desc.h
+3
-0
paddle/fluid/framework/channel.h
paddle/fluid/framework/channel.h
+4
-3
paddle/fluid/framework/channel_impl.h
paddle/fluid/framework/channel_impl.h
+11
-10
paddle/fluid/framework/channel_test.cc
paddle/fluid/framework/channel_test.cc
+80
-80
paddle/fluid/framework/details/CMakeLists.txt
paddle/fluid/framework/details/CMakeLists.txt
+1
-1
paddle/fluid/framework/lod_tensor.h
paddle/fluid/framework/lod_tensor.h
+1
-0
paddle/fluid/framework/operator.cc
paddle/fluid/framework/operator.cc
+11
-0
paddle/fluid/framework/operator.h
paddle/fluid/framework/operator.h
+2
-0
paddle/fluid/framework/parallel_executor.cc
paddle/fluid/framework/parallel_executor.cc
+19
-2
paddle/fluid/framework/parallel_executor.h
paddle/fluid/framework/parallel_executor.h
+5
-1
paddle/fluid/framework/selected_rows.cc
paddle/fluid/framework/selected_rows.cc
+5
-1
paddle/fluid/framework/selected_rows.h
paddle/fluid/framework/selected_rows.h
+13
-1
paddle/fluid/framework/tensor_impl.h
paddle/fluid/framework/tensor_impl.h
+12
-5
paddle/fluid/framework/tuple.h
paddle/fluid/framework/tuple.h
+8
-7
paddle/fluid/inference/io.cc
paddle/fluid/inference/io.cc
+3
-6
paddle/fluid/inference/io.h
paddle/fluid/inference/io.h
+1
-2
paddle/fluid/inference/tests/book/CMakeLists.txt
paddle/fluid/inference/tests/book/CMakeLists.txt
+1
-1
paddle/fluid/inference/tests/book/test_inference_fit_a_line.cc
...e/fluid/inference/tests/book/test_inference_fit_a_line.cc
+3
-3
paddle/fluid/inference/tests/book/test_inference_image_classification.cc
...ference/tests/book/test_inference_image_classification.cc
+7
-9
paddle/fluid/inference/tests/book/test_inference_label_semantic_roles.cc
...ference/tests/book/test_inference_label_semantic_roles.cc
+9
-25
paddle/fluid/inference/tests/book/test_inference_recognize_digits.cc
...d/inference/tests/book/test_inference_recognize_digits.cc
+7
-9
paddle/fluid/inference/tests/book/test_inference_recommender_system.cc
...inference/tests/book/test_inference_recommender_system.cc
+8
-8
paddle/fluid/inference/tests/book/test_inference_rnn_encoder_decoder.cc
...nference/tests/book/test_inference_rnn_encoder_decoder.cc
+5
-5
paddle/fluid/inference/tests/book/test_inference_understand_sentiment.cc
...ference/tests/book/test_inference_understand_sentiment.cc
+2
-4
paddle/fluid/inference/tests/book/test_inference_word2vec.cc
paddle/fluid/inference/tests/book/test_inference_word2vec.cc
+5
-5
paddle/fluid/inference/tests/test_helper.h
paddle/fluid/inference/tests/test_helper.h
+32
-35
paddle/fluid/memory/.clang-format
paddle/fluid/memory/.clang-format
+0
-5
paddle/fluid/memory/memory.cc
paddle/fluid/memory/memory.cc
+1
-1
paddle/fluid/memory/memory_test.cc
paddle/fluid/memory/memory_test.cc
+4
-4
paddle/fluid/operators/.clang-format
paddle/fluid/operators/.clang-format
+0
-5
paddle/fluid/operators/CMakeLists.txt
paddle/fluid/operators/CMakeLists.txt
+2
-2
paddle/fluid/operators/conv_cudnn_op.cu.cc
paddle/fluid/operators/conv_cudnn_op.cu.cc
+22
-0
paddle/fluid/operators/fc_mkldnn_op.cc
paddle/fluid/operators/fc_mkldnn_op.cc
+3
-3
paddle/fluid/operators/lookup_table_op.cc
paddle/fluid/operators/lookup_table_op.cc
+4
-18
paddle/fluid/operators/lookup_table_op.h
paddle/fluid/operators/lookup_table_op.h
+8
-10
paddle/fluid/operators/math/math_function.cu
paddle/fluid/operators/math/math_function.cu
+24
-9
paddle/fluid/operators/math/softmax.cu
paddle/fluid/operators/math/softmax.cu
+3
-0
paddle/fluid/operators/math/softmax_impl.h
paddle/fluid/operators/math/softmax_impl.h
+1
-1
paddle/fluid/operators/prior_box_op.cc
paddle/fluid/operators/prior_box_op.cc
+3
-4
paddle/fluid/operators/prior_box_op.cu
paddle/fluid/operators/prior_box_op.cu
+167
-0
paddle/fluid/operators/prior_box_op.h
paddle/fluid/operators/prior_box_op.h
+10
-35
paddle/fluid/operators/reader/create_batch_reader_op.cc
paddle/fluid/operators/reader/create_batch_reader_op.cc
+5
-2
paddle/fluid/operators/reader/create_double_buffer_reader_op.cc
.../fluid/operators/reader/create_double_buffer_reader_op.cc
+5
-2
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
+6
-3
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
+6
-2
paddle/fluid/operators/sgd_op.cc
paddle/fluid/operators/sgd_op.cc
+7
-6
paddle/fluid/operators/sgd_op.h
paddle/fluid/operators/sgd_op.h
+80
-43
paddle/fluid/operators/softmax_op.cc
paddle/fluid/operators/softmax_op.cc
+7
-2
paddle/fluid/operators/softmax_op.cu.cc
paddle/fluid/operators/softmax_op.cu.cc
+6
-5
paddle/fluid/platform/.clang-format
paddle/fluid/platform/.clang-format
+0
-5
paddle/fluid/platform/CMakeLists.txt
paddle/fluid/platform/CMakeLists.txt
+2
-2
paddle/fluid/platform/cpu_info_test.cc
paddle/fluid/platform/cpu_info_test.cc
+1
-1
paddle/fluid/platform/cudnn_helper.h
paddle/fluid/platform/cudnn_helper.h
+3
-1
paddle/fluid/platform/dynload/cublas.cc
paddle/fluid/platform/dynload/cublas.cc
+4
-0
paddle/fluid/platform/dynload/cublas.h
paddle/fluid/platform/dynload/cublas.h
+32
-24
paddle/fluid/platform/dynload/cudnn.cc
paddle/fluid/platform/dynload/cudnn.cc
+2
-1
paddle/fluid/platform/dynload/cudnn.h
paddle/fluid/platform/dynload/cudnn.h
+16
-15
paddle/fluid/platform/dynload/cupti.h
paddle/fluid/platform/dynload/cupti.h
+15
-14
paddle/fluid/platform/dynload/curand.h
paddle/fluid/platform/dynload/curand.h
+15
-14
paddle/fluid/platform/dynload/dynamic_loader.cc
paddle/fluid/platform/dynload/dynamic_loader.cc
+46
-43
paddle/fluid/platform/dynload/dynamic_loader.h
paddle/fluid/platform/dynload/dynamic_loader.h
+7
-49
paddle/fluid/platform/dynload/nccl.cc
paddle/fluid/platform/dynload/nccl.cc
+0
-5
paddle/fluid/platform/dynload/nccl.h
paddle/fluid/platform/dynload/nccl.h
+15
-13
paddle/fluid/platform/dynload/warpctc.h
paddle/fluid/platform/dynload/warpctc.h
+15
-14
paddle/fluid/platform/enforce.h
paddle/fluid/platform/enforce.h
+15
-15
paddle/fluid/platform/enforce_test.cc
paddle/fluid/platform/enforce_test.cc
+0
-4
paddle/fluid/platform/float16.h
paddle/fluid/platform/float16.h
+161
-66
paddle/fluid/platform/gpu_info.cc
paddle/fluid/platform/gpu_info.cc
+6
-5
paddle/fluid/platform/gpu_info.h
paddle/fluid/platform/gpu_info.h
+1
-5
paddle/fluid/platform/place.h
paddle/fluid/platform/place.h
+2
-1
paddle/fluid/pybind/.clang-format
paddle/fluid/pybind/.clang-format
+0
-5
paddle/fluid/pybind/CMakeLists.txt
paddle/fluid/pybind/CMakeLists.txt
+2
-0
paddle/fluid/pybind/const_value.cc
paddle/fluid/pybind/const_value.cc
+6
-6
paddle/fluid/pybind/const_value.h
paddle/fluid/pybind/const_value.h
+5
-4
paddle/fluid/pybind/exception.cc
paddle/fluid/pybind/exception.cc
+4
-3
paddle/fluid/pybind/exception.h
paddle/fluid/pybind/exception.h
+5
-2
paddle/fluid/pybind/protobuf.cc
paddle/fluid/pybind/protobuf.cc
+149
-133
paddle/fluid/pybind/protobuf.h
paddle/fluid/pybind/protobuf.h
+7
-7
paddle/fluid/pybind/pybind.cc
paddle/fluid/pybind/pybind.cc
+54
-12
paddle/fluid/pybind/recordio.cc
paddle/fluid/pybind/recordio.cc
+10
-2
paddle/fluid/pybind/recordio.h
paddle/fluid/pybind/recordio.h
+2
-1
paddle/fluid/pybind/tensor_py.h
paddle/fluid/pybind/tensor_py.h
+93
-47
paddle/fluid/pybind/tensor_py_test.cc
paddle/fluid/pybind/tensor_py_test.cc
+44
-0
paddle/fluid/recordio/chunk.cc
paddle/fluid/recordio/chunk.cc
+8
-6
paddle/fluid/recordio/chunk.h
paddle/fluid/recordio/chunk.h
+2
-2
paddle/fluid/recordio/chunk_test.cc
paddle/fluid/recordio/chunk_test.cc
+5
-7
paddle/fluid/recordio/header.h
paddle/fluid/recordio/header.h
+2
-2
paddle/fluid/recordio/header_test.cc
paddle/fluid/recordio/header_test.cc
+2
-4
paddle/fluid/recordio/scanner.cc
paddle/fluid/recordio/scanner.cc
+4
-0
paddle/fluid/recordio/scanner.h
paddle/fluid/recordio/scanner.h
+5
-2
paddle/fluid/recordio/writer.cc
paddle/fluid/recordio/writer.cc
+5
-0
paddle/fluid/recordio/writer.h
paddle/fluid/recordio/writer.h
+6
-5
paddle/fluid/recordio/writer_scanner_test.cc
paddle/fluid/recordio/writer_scanner_test.cc
+4
-3
paddle/fluid/string/.clang-format
paddle/fluid/string/.clang-format
+0
-1
paddle/fluid/string/piece.cc
paddle/fluid/string/piece.cc
+1
-1
paddle/fluid/string/printf.h
paddle/fluid/string/printf.h
+2
-0
paddle/fluid/string/printf_test.cc
paddle/fluid/string/printf_test.cc
+3
-2
paddle/fluid/string/to_string_test.cc
paddle/fluid/string/to_string_test.cc
+3
-4
paddle/gserver/tests/CMakeLists.txt
paddle/gserver/tests/CMakeLists.txt
+12
-7
paddle/gserver/tests/test_Upsample.cpp
paddle/gserver/tests/test_Upsample.cpp
+43
-42
paddle/trainer/tests/CMakeLists.txt
paddle/trainer/tests/CMakeLists.txt
+9
-4
paddle/utils/CMakeLists.txt
paddle/utils/CMakeLists.txt
+2
-2
proto/CMakeLists.txt
proto/CMakeLists.txt
+3
-2
python/CMakeLists.txt
python/CMakeLists.txt
+5
-3
python/paddle/fluid/__init__.py
python/paddle/fluid/__init__.py
+2
-1
python/paddle/fluid/distribute_transpiler.py
python/paddle/fluid/distribute_transpiler.py
+8
-16
python/paddle/fluid/distributed_splitter.py
python/paddle/fluid/distributed_splitter.py
+11
-4
python/paddle/fluid/framework.py
python/paddle/fluid/framework.py
+29
-8
python/paddle/fluid/layers/io.py
python/paddle/fluid/layers/io.py
+37
-8
python/paddle/fluid/parallel_executor.py
python/paddle/fluid/parallel_executor.py
+31
-10
python/paddle/fluid/tests/unittests/CMakeLists.txt
python/paddle/fluid/tests/unittests/CMakeLists.txt
+2
-2
python/paddle/fluid/tests/unittests/test_conv2d_op.py
python/paddle/fluid/tests/unittests/test_conv2d_op.py
+7
-4
python/paddle/fluid/tests/unittests/test_lookup_table_op.py
python/paddle/fluid/tests/unittests/test_lookup_table_op.py
+4
-4
python/paddle/fluid/tests/unittests/test_parallel_executor.py
...on/paddle/fluid/tests/unittests/test_parallel_executor.py
+49
-29
python/paddle/fluid/tests/unittests/test_prior_box_op.py
python/paddle/fluid/tests/unittests/test_prior_box_op.py
+27
-29
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
+21
-21
python/paddle/fluid/tests/unittests/test_recordio_reader.py
python/paddle/fluid/tests/unittests/test_recordio_reader.py
+2
-2
python/paddle/fluid/tests/unittests/test_sgd_op.py
python/paddle/fluid/tests/unittests/test_sgd_op.py
+67
-0
python/paddle/fluid/tests/unittests/test_softmax_op.py
python/paddle/fluid/tests/unittests/test_softmax_op.py
+11
-0
python/paddle/trainer_config_helpers/tests/CMakeLists.txt
python/paddle/trainer_config_helpers/tests/CMakeLists.txt
+4
-4
python/paddle/trainer_config_helpers/tests/configs/generate_protostr.sh
...trainer_config_helpers/tests/configs/generate_protostr.sh
+0
-1
python/setup.py.in
python/setup.py.in
+3
-2
未找到文件。
.gitignore
浏览文件 @
9eaf4458
...
...
@@ -25,12 +25,3 @@ third_party/
# clion workspace.
cmake-build-*
# generated while compiling
paddle/pybind/pybind.h
CMakeFiles
cmake_install.cmake
paddle/.timestamp
python/paddlepaddle.egg-info/
paddle/fluid/pybind/pybind.h
python/paddle/version.py
cmake/external/mklml.cmake
浏览文件 @
9eaf4458
...
...
@@ -28,7 +28,7 @@ INCLUDE(ExternalProject)
SET
(
MKLML_PROJECT
"extern_mklml"
)
SET
(
MKLML_VER
"mklml_lnx_2018.0.1.20171007"
)
SET
(
MKLML_URL
"http
s://github.com/01org/mkl-dnn/releases/download/v0.11
/
${
MKLML_VER
}
.tgz"
)
SET
(
MKLML_URL
"http
://paddlepaddledeps.bj.bcebos.com
/
${
MKLML_VER
}
.tgz"
)
SET
(
MKLML_SOURCE_DIR
"
${
THIRD_PARTY_PATH
}
/mklml"
)
SET
(
MKLML_DOWNLOAD_DIR
"
${
MKLML_SOURCE_DIR
}
/src/
${
MKLML_PROJECT
}
"
)
SET
(
MKLML_DST_DIR
"mklml"
)
...
...
cmake/external/snappystream.cmake
浏览文件 @
9eaf4458
...
...
@@ -54,5 +54,7 @@ add_library(snappystream STATIC IMPORTED GLOBAL)
set_property
(
TARGET snappystream PROPERTY IMPORTED_LOCATION
"
${
SNAPPYSTREAM_INSTALL_DIR
}
/lib/libsnappystream.a"
)
include_directories
(
${
SNAPPYSTREAM_INCLUDE_DIR
}
)
include_directories
(
${
SNAPPYSTREAM_INCLUDE_DIR
}
)
# For snappysteam to include its own headers.
include_directories
(
${
THIRD_PARTY_PATH
}
/install
)
# For Paddle to include snappy stream headers.
add_dependencies
(
snappystream extern_snappystream
)
cmake/external/warpctc.cmake
浏览文件 @
9eaf4458
...
...
@@ -62,7 +62,8 @@ ExternalProject_Add(
)
MESSAGE
(
STATUS
"warp-ctc library:
${
WARPCTC_LIBRARIES
}
"
)
INCLUDE_DIRECTORIES
(
${
WARPCTC_INCLUDE_DIR
}
)
INCLUDE_DIRECTORIES
(
${
WARPCTC_INCLUDE_DIR
}
)
# For warpctc code to include its headers.
INCLUDE_DIRECTORIES
(
${
THIRD_PARTY_PATH
}
/install
)
# For Paddle code to include warpctc headers.
ADD_LIBRARY
(
warpctc SHARED IMPORTED GLOBAL
)
SET_PROPERTY
(
TARGET warpctc PROPERTY IMPORTED_LOCATION
${
WARPCTC_LIBRARIES
}
)
...
...
cmake/external/zlib.cmake
浏览文件 @
9eaf4458
...
...
@@ -25,7 +25,8 @@ ELSE(WIN32)
SET
(
ZLIB_LIBRARIES
"
${
ZLIB_INSTALL_DIR
}
/lib/libz.a"
CACHE FILEPATH
"zlib library."
FORCE
)
ENDIF
(
WIN32
)
INCLUDE_DIRECTORIES
(
${
ZLIB_INCLUDE_DIR
}
)
INCLUDE_DIRECTORIES
(
${
ZLIB_INCLUDE_DIR
}
)
# For zlib code to include its own headers.
INCLUDE_DIRECTORIES
(
${
THIRD_PARTY_PATH
}
/install
)
# For Paddle code to include zlib.h.
ExternalProject_Add
(
extern_zlib
...
...
cmake/generic.cmake
浏览文件 @
9eaf4458
...
...
@@ -251,7 +251,7 @@ function(cc_test TARGET_NAME)
add_dependencies
(
${
TARGET_NAME
}
${
cc_test_DEPS
}
paddle_gtest_main paddle_memory gtest gflags glog
)
add_test
(
NAME
${
TARGET_NAME
}
COMMAND
${
TARGET_NAME
}
${
cc_test_ARGS
}
WORKING_DIRECTORY
${
CMAKE_CURRENT_
SOURCE
_DIR
}
)
WORKING_DIRECTORY
${
CMAKE_CURRENT_
BINARY
_DIR
}
)
endif
()
endfunction
(
cc_test
)
...
...
@@ -561,9 +561,9 @@ function(py_test TARGET_NAME)
set
(
multiValueArgs SRCS DEPS ARGS ENVS
)
cmake_parse_arguments
(
py_test
"
${
options
}
"
"
${
oneValueArgs
}
"
"
${
multiValueArgs
}
"
${
ARGN
}
)
add_test
(
NAME
${
TARGET_NAME
}
COMMAND env PYTHONPATH=
${
PADDLE_
PYTHON_BUILD_DIR
}
/lib-
python
${
py_test_ENVS
}
COMMAND env PYTHONPATH=
${
PADDLE_
BINARY_DIR
}
/
python
${
py_test_ENVS
}
${
PYTHON_EXECUTABLE
}
-u
${
py_test_SRCS
}
${
py_test_ARGS
}
WORKING_DIRECTORY
${
CMAKE_CURRENT_
SOURCE
_DIR
}
)
WORKING_DIRECTORY
${
CMAKE_CURRENT_
BINARY
_DIR
}
)
endif
()
endfunction
()
...
...
doc/design/file_manager/README.md
已删除
100644 → 0
浏览文件 @
f132f51e
# FileManager设计文档
## 目标
在本文档中,我们设计说明了名为FileManager系统,方便用户上传自己的训练数据以进行分布式训练
主要功能包括:
-
提供常用的命令行管理命令管理文件和目录
-
支持大文件的断点上传、下载
## 名词解释
-
PFS:是
`Paddlepaddle cloud File System`
的缩写,是对用户文件存储空间的抽象,与之相对的是local filesystem。目前我们用CephFS来搭建。
-
[
CephFS
](
http://docs.ceph.com/docs/master/cephfs/
)
:一个POSIX兼容的文件系统。
-
Chunk:逻辑划上文件分块的单位。
## 模块
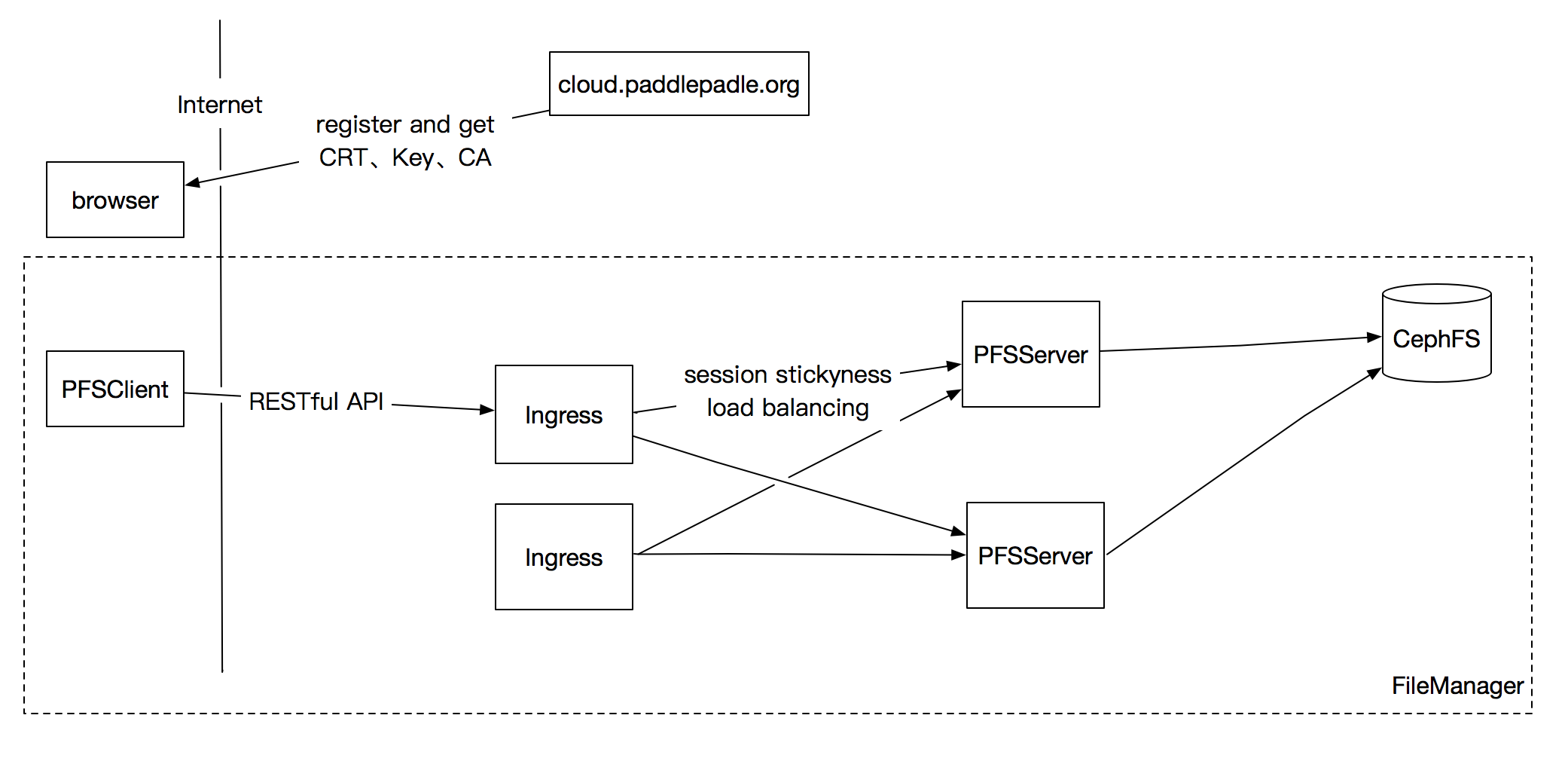
### 架构图
<image
src=
./src/filemanager.png
width=
900
>
### PFSClient
-
功能: 详细设计
[
link
](
./pfs/pfsclient.md
)
-
提供用户管理文件的命令
-
需要可以跨平台执行
-
双向验证
PFSClient需要和Ingress之间做双向验证
<sup>
[
tls
](
#tls
)
</sup>
,所以用户需要首先在
`cloud.paddlepaddle.org`
上注册一下,申请用户空间,并且把系统生成的CA(certificate authority)、Key、CRT(CA signed certificate)下载到本地,然后才能使用PFSClient。
### [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/)
-
功能:
提供七层协议的反向代理、基于粘性会话的负载均衡功能。
-
透传用户身份的办法
Ingress需要把PFSClient的身份信息传给PFSServer,配置的方法参考
[
link
](
http://www.integralist.co.uk/posts/clientcertauth.html#3
)
### PFSServer
PFSServer提供RESTful API接口,接收处理PFSClient端的文件管理请求,并且把结果返回PFSClient端。
RESTful API
-
/api/v1/files
-
`GET /api/v1/files`
: Get metadata of files or directories.
-
`POST /api/v1/files`
: Create files or directories.
-
`PATCH /api/v1/files`
: Update files or directories.
-
`DELETE /api/v1/files`
: Delete files or directories.
-
/api/v1/file/chunks
-
`GET /api/v1/storage/file/chunks`
: Get chunks's metadata of a file.
-
/api/v1/storage/files
-
`GET /api/v1/storage/files`
: Download files or directories.
-
`POST /api/v1/storage/files`
: Upload files or directories.
-
/api/v1/storage/file/chunks
-
`GET /api/v1/storage/file/chunks`
: Download chunks's data.
-
`POST /api/v1/storage/file/chunks`
: Upload chunks's data.
## 文件传输优化
### 分块文件传输
用户文件可能是比较大的,上传到Cloud或者下载到本地的时间可能比较长,而且在传输的过程中也可能出现网络不稳定的情况。为了应对以上的问题,我们提出了Chunk的概念,一个Chunk由所在的文件偏移、数据、数据长度及校验值组成。文件的上传和下载都是通过对Chunk的操作来实现的。由于Chunk比较小(默认256K),完成一个传输动作完成的时间也比较短,不容易出错。PFSClient需要在传输完毕最后一个Chunk的时候检查destination文件的MD5值是否和source文件一致。
一个典型的Chunk如下所示:
```
type Chunk struct {
fileOffset int64
checksum uint32
len uint32
data []byte
}
```
### 生成sparse文件
当destination文件不存在或者大小和source文件不一致时,可以用
[
Fallocate
](
https://Go.org/pkg/syscall/#Fallocate
)
生成sparse文件,然后就可以并发写入多个Chunk。
### 覆盖不一致的部分
文件传输的的关键在于需要PFSClient端对比source和destination的文件Chunks的checksum是否保持一致,不一致的由PFSClient下载或者传输Chunk完成。这样已经传输成功的部分就不用重新传输了。
## 用户使用流程
参考
[
link
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/cluster_train/data_dispatch.md
)
## 框架生成
用
[
swagger
](
https://github.com/swagger-api/swagger-codegen
)
生成PFSClient和PFSServer的框架部分,以便我们可以把更多的精力放到逻辑本身上。
## 参考文档
-
<a
name=
tls
></a>
[
TLS complete guide
](
https://github.com/k8sp/tls/blob/master/tls.md
)
-
[
aws.s3
](
http://docs.aws.amazon.com/cli/latest/reference/s3/
)
-
[
linux man document
](
https://linux.die.net/man/
)
doc/design/file_manager/pfs/pfsclient.md
已删除
100644 → 0
浏览文件 @
f132f51e
# PFSClient
## Description
The
`pfs`
command is a Command Line Interface to manage your files on PaddlePaddle Cloud
## Synopsis
```
paddle [options] pfs <subcommand> [parameters]
```
## Options
```
--profile (string)
Use a specific profile from your credential file.
--help (string)
Display more information about command
--version
Output version information and exit
--debug
Show detailed debugging log
--only-show-errors (boolean)
Only errors and warnings are displayed. All other output is suppressed.
```
## Path Arguments
When using a command, we need to specify path arguments. There are two path argument type:
`localpath`
and
`pfspath`
.
A
`pfspath`
begin with
`/pfs`
, eg:
`/pfs/$DATACENTER/home/$USER/folder`
.
[
Here
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/cluster_train/data_dispatch.md#上传训练文件
)
is how to config datacenters.
## order of Path Arguments
Commonly, if there are two path arguments, the first is the source, and the second is the destination.
## Subcommonds
-
rm - remove files or directories
```
Synopsis:
rm [-r] [-v] <PFSPath> ...
Options:
-r
Remove directories and their contents recursively
-v
Cause rm to be verbose, showing files after they are removed.
Examples:
paddle pfs rm /pfs/$DATACENTER/home/$USER/file
paddle pfs rm -r /pfs/$DATACENTER/home/$USER/folder
```
-
mv - move (rename) files
```
Synopsis:
mv [-f | -n] [-v] <LocalPath> <PFSPath>
mv [-f | -n] [-v] <LocalPath> ... <PFSPath>
mv [-f | -n] [-v] <PFSPath> <LocalPath>
mv [-f | -n] [-v] <PFSPath> ... <LocalPath>
mv [-f | -n] [-v] <PFSPath> <PFSPath>
mv [-f | -n] [-v] <PFSPath> ... <PFSPath>
Options:
-f
Do not prompt for confirmation before overwriting the destination path. (The -f option overrides previous -n options.)
-n
Do not overwrite an existing file. (The -n option overrides previous -f options.)
-v
Cause mv to be verbose, showing files after they are moved.
Examples:
paddle pfs mv ./text1.txt /pfs/$DATACENTER/home/$USER/text1.txt
```
-
cp - copy files or directories
```
Synopsis:
cp [-r] [-f | -n] [-v] [--preserve--links] <LocalPath> <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <LocalPath> ... <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> <LocalPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> ... <LocalPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> ... <PFSPath>
Options:
-r
Copy directories recursively
-f
Do not prompt for confirmation before overwriting the destination path. (The -f option overrides previous -n options.)
-n
Do not overwrite an existing file. (The -n option overrides previous -f options.)
-v
Cause cp to be verbose, showing files after they are copied.
--preserve--links
Reserve links when copy links
Examples:
paddle pfs cp ./file /pfs/$DATACENTER/home/$USER/file
paddle pfs cp /pfs/$DATACENTER/home/$USER/file ./file
```
-
ls- list files
```
Synopsis:
ls [-r] <PFSPath> ...
Options:
-R
List directory(ies) recursively
Examples:
paddle pfs ls /pfs/$DATACENTER/home/$USER/file
paddle pfs ls /pfs/$DATACENTER/home/$USER/folder
```
-
mkdir - mkdir directory(ies)
Create intermediate directory(ies) as required.
```
Synopsis:
mkdir <PFSPath> ...
Examples:
paddle pfs mkdir /pfs/$DATACENTER/home/$USER/folder
```
doc/design/file_manager/src/filemanager.graffle
已删除
100644 → 0
浏览文件 @
f132f51e
文件已删除
doc/design/file_manager/src/filemanager.png
已删除
100644 → 0
浏览文件 @
f132f51e
141.7 KB
doc/fluid/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -27,7 +27,7 @@ sphinx_add_target(paddle_fluid_docs
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_EN
}
)
add_dependencies
(
paddle_fluid_docs gen_proto_py
)
add_dependencies
(
paddle_fluid_docs gen_proto_py
paddle_python
)
# configured documentation tools and intermediate build results
set
(
BINARY_BUILD_DIR_CN
"
${
CMAKE_CURRENT_BINARY_DIR
}
/cn/_build"
)
...
...
@@ -50,6 +50,6 @@ sphinx_add_target(paddle_fluid_docs_cn
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_CN
}
)
add_dependencies
(
paddle_fluid_docs_cn gen_proto_py
)
add_dependencies
(
paddle_fluid_docs_cn gen_proto_py
paddle_python
)
add_subdirectory
(
api
)
doc/fluid/api/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -19,4 +19,4 @@ sphinx_add_target(paddle_fluid_apis
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_EN
}
)
add_dependencies
(
paddle_fluid_apis gen_proto_py framework_py_proto copy_paddle_pybind
)
add_dependencies
(
paddle_fluid_apis gen_proto_py framework_py_proto copy_paddle_pybind
paddle_python
)
doc/fluid/dev/index_cn.rst
浏览文件 @
9eaf4458
...
...
@@ -9,5 +9,5 @@
use_eigen_cn.md
name_convention.md
support_new_device.md
releasing_process.md
releasing_process
_cn
.md
op_markdown_format.md
doc/fluid/dev/index_en.rst
浏览文件 @
9eaf4458
...
...
@@ -9,5 +9,5 @@ Development
use_eigen_en.md
name_convention.md
support_new_device.md
releasing_process.md
releasing_process
_en
.md
op_markdown_format.md
doc/fluid/dev/releasing_process.md
→
doc/fluid/dev/releasing_process
_cn
.md
浏览文件 @
9eaf4458
...
...
@@ -10,19 +10,10 @@ PaddlePaddle每次发新的版本,遵循以下流程:
*
使用Regression Test List作为检查列表,测试本次release的正确性。
*
如果失败,记录下所有失败的例子,在这个
`release/版本号`
分支中,修复所有bug后,Patch号加一,到第二步
*
修改
`python/setup.py.in`
中的版本信息,并将
`istaged`
字段设为
`True`
。
*
编译这个版本的python wheel包,并发布到pypi。
*
由于pypi.python.org目前遵循
[
严格的命名规范PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
,在使用twine上传之前,需要重命名wheel包中platform相关的后缀,比如将
`linux_x86_64`
修改成
`manylinux1_x86_64`
。
*
pypi上的package名称为paddlepaddle和paddlepaddle_gpu,如果要上传GPU版本的包,需要修改build/python/setup.py中,name: "paddlepaddle_gpu"并重新打包wheel包:
`python setup.py bdist_wheel`
。
*
上传方法:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
编译这个版本的Docker发行镜像,发布到dockerhub。如果失败,修复Docker编译镜像问题,Patch号加一,返回第二步
1.
第三步完成后,将
`release/版本号`
分支合入master分支,并删除
`release/版本号`
分支。将master分支的合入commit打上tag,tag为
`版本号`
。同时再将
`master`
分支合入
`develop`
分支。最后删除
`release/版本号`
分支。
1.
协同完成Release Note的书写
*
将这个版本的python wheel包发布到pypi。
*
更新Docker镜像(参考后面的操作细节)。
1.
第三步完成后,将
`release/版本号`
分支合入master分支,将master分支的合入commit打上tag,tag为
`版本号`
。同时再将
`master`
分支合入
`develop`
分支。
1.
协同完成Release Note的书写。
需要注意的是:
...
...
@@ -31,13 +22,18 @@ PaddlePaddle每次发新的版本,遵循以下流程:
## 发布wheel包到pypi
使用
[
PaddlePaddle CI
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
1.
使用
[
PaddlePaddle CI
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
完成自动化二进制编译,参考下图,选择需要发布的版本(通常包含一个CPU版本和一个GPU版本),点击"run"右侧的"..."按钮,可以
弹出下面的选择框,在第二个tab (Changes)里选择需要发布的分支,这里选择0.11.0,然后点击"Run Build"按钮。等待编译完成后
可以在此页面的"Artifacts"下拉框中找到生成的3个二进制文件,分别对应CAPI,
`cp27m`
和
`cp27mu`
的版本。然后按照上述的方法
使用
`twine`
工具上传即可。
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
弹出下面的选择框,在第二个tab (Changes)里选择需要发布的分支,这里选择0.11.0,然后点击"Run Build"按钮。
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
1.
等待编译完成后可以在此页面的"Artifacts"下拉框中找到生成的3个二进制文件,分别对应CAPI,
`cp27m`
和
`cp27mu`
的版本。
1.
由于pypi.python.org目前遵循
[
严格的命名规范PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
,在使用twine上传之前,需要重命名wheel包中platform相关的后缀,比如将
`linux_x86_64`
修改成
`manylinux1_x86_64`
。
1.
上传:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
注:CI环境使用 https://github.com/PaddlePaddle/buildtools 这里的DockerImage作为编译环境以支持更多的Linux
发型版,如果需要手动编译,也可以使用这些镜像。这些镜像也可以从 https://hub.docker.com/r/paddlepaddle/paddle_manylinux_devel/tags/ 下载得到。
...
...
@@ -48,10 +44,20 @@ PaddlePaddle每次发新的版本,遵循以下流程:
上述PaddlePaddle CI编译wheel完成后会自动将Docker镜像push到DockerHub,所以,发布Docker镜像只需要对自动push的镜像打上
版本号对应的tag即可:
1.
进入 https://hub.docker.com/r/paddlepaddle/paddle/tags/ 查看latest tag的更新时间是否在上述编译wheel包完成后是否最新。
1.
执行
`docker pull paddlepaddle/paddle:[latest tag]`
,latest tag可以是latest或latest-gpu等。
1.
执行
`docker tag paddlepaddle/paddle:[latest tag] paddlepaddle/paddle:[version]`
1.
执行
`docker push paddlepaddle/paddle:[version]`
```
docker pull [镜像]:latest
docker tag [镜像]:latest [镜像]:[version]
docker push [镜像]:[version]
```
需要更新的镜像tag包括:
*
`[version]`
: CPU版本
*
`[version]-openblas`
: openblas版本
*
`[version]-gpu`
: GPU版本(CUDA 8.0 cudnn 5)
*
`[version]-gpu-[cudaver]-[cudnnver]`
: 不同cuda, cudnn版本的镜像
之后可进入 https://hub.docker.com/r/paddlepaddle/paddle/tags/ 查看是否发布成功。
## PaddlePaddle 分支规范
...
...
@@ -76,7 +82,7 @@ PaddlePaddle开发过程使用[git-flow](http://nvie.com/posts/a-successful-git-
### PaddlePaddle Book中所有章节
PaddlePaddle每次发版本首先要保证PaddlePaddle Book中所有章节功能的正确性。功能的正确性包括验证PaddlePaddle目前的
`paddle_trainer`
训练和纯使用
`Python`
训练模型正确性。
PaddlePaddle每次发版本首先要保证PaddlePaddle Book中所有章节功能的正确性。功能的正确性包括验证PaddlePaddle目前的
`paddle_trainer`
训练和纯使用
`Python`
训练
(V2和Fluid)
模型正确性。
<table>
<thead>
...
...
doc/fluid/dev/releasing_process_en.md
0 → 100644
浏览文件 @
9eaf4458
# PaddlePaddle Releasing Process
PaddlePaddle manages its branches using "git-flow branching model", and
[
Semantic Versioning
](
http://semver.org/
)
as it's version number semantics.
Each time we release a new PaddlePaddle version, we should follow the below steps:
1.
Fork a new branch from
`develop`
named
`release/[version]`
, e.g.
`release/0.10.0`
.
1.
Push a new tag on the release branch, the tag name should be like
`[version]rc.patch`
. The
first tag should be
`0.10.0rc1`
, and the second should be
`0.10.0.rc2`
and so on.
1.
After that, we should do:
*
Run all regression test on the Regression Test List (see PaddlePaddle TeamCity CI), to confirm
that this release has no major bugs.
*
If regression test fails, we must fix those bugs and create a new
`release/[version]`
branch from previous release branch.
*
Modify
`python/setup.py.in`
, change the version number and change
`ISTAGED`
to
`True`
.
*
Publish PaddlePaddle release wheel packages to pypi (see below instructions for detail).
*
Update the Docker images (see below instructions for detail).
1.
After above step, merge
`release/[version]`
branch to master and push a tag on the master commit,
then merge
`master`
to
`develop`
.
1.
Update the Release Note.
***NOTE:**
*
*
Do
***NOT**
*
merge commits from develop branch to release branches to keep the release branch contain
features only for current release, so that we can test on that version.
*
If we want to fix bugs on release branches, we must merge the fix to master, develop and release branch.
## Publish Wheel Packages to pypi
1.
Use our
[
CI tool
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
to build all wheel packages needed to publish. As shown in the following picture, choose a build
version, click "..." button on the right side of "Run" button, and switch to the second tab in the
pop-up box, choose the current release branch and click "Run Build" button. You may repeat this
step to start different versions of builds.
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
1.
After the build succeeds, download the outputs under "Artifacts" including capi,
`cp27m`
and
`cp27mu`
.
1.
Since pypi.python.org follows
[
PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
, before we
upload the package using
`twine`
, we need to rename the package from
`linux_x86_64`
to
`manylinux1_x86_64`
.
1.
Start the upload:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
NOTE: We use a special Docker image to build our releases to support more Linux distributions, you can
download it from https://hub.docker.com/r/paddlepaddle/paddle_manylinux_devel/tags/, or build it using
scripts under
`tools/manylinux1`
.
*
pypi does not allow overwrite the already uploaded version of wheel package, even if you delete the
old version. you must change the version number before upload a new one.
## Publish Docker Images
Our CI tool will push latest images to DockerHub, so we only need to push a version tag like:
```
docker pull [image]:latest
docker tag [image]:latest [image]:[version]
docker push [image]:[version]
```
Tags that need to be updated are:
*
`[version]`
: CPU only version image
*
`[version]-openblas`
: openblas version image
*
`[version]-gpu`
: GPU version(using CUDA 8.0 cudnn 5)
*
`[version]-gpu-[cudaver]-[cudnnver]`
: tag for different cuda, cudnn versions
You can then checkout the latest pushed tags at https://hub.docker.com/r/paddlepaddle/paddle/tags/.
## Branching Model
We use
[
git-flow
](
http://nvie.com/posts/a-successful-git-branching-model/
)
as our branching model,
with some modifications:
*
`master`
branch is the stable branch. Each version on the master branch is tested and guaranteed.
*
`develop`
branch is for development. Each commit on develop branch has passed CI unit test, but no
regression tests are run.
*
`release/[version]`
branch is used to publish each release. Latest release version branches have
bugfix only for that version, but no feature updates.
*
Developer forks are not required to follow
[
git-flow
](
http://nvie.com/posts/a-successful-git-branching-model/
)
branching model, all forks is like a feature branch.
*
Advise: developer fork's develop branch is used to sync up with main repo's develop branch.
*
Advise: developer use it's fork's develop branch to for new branch to start developing.
*
Use that branch on developer's fork to create pull requests and start reviews.
*
developer can push new commits to that branch when the pull request is open.
*
Bug fixes are also started from developers forked repo. And, bug fixes branch can merge to
`master`
,
`develop`
and
`releases`
.
## PaddlePaddle Regression Test List
### All Chapters of PaddlePaddle Book
We need to guarantee that all the chapters of PaddlePaddle Book can run correctly. Including
V1 (
`paddle_trainer`
training) and V2 training and Fluid training.
<table>
<thead>
<tr>
<th></th>
<th>
Linear Regression
</th>
<th>
Recognize Digits
</th>
<th>
Image Classification
</th>
<th>
Word2Vec
</th>
<th>
Personalized Recommendation
</th>
<th>
Sentiment Analysis
</th>
<th>
Semantic Role Labeling
</th>
<th>
Machine Translation
</th>
</tr>
</thead>
<tbody>
<tr>
<td>
API.V2 + Docker + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Docker + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Docker + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Docker + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Ubuntu + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Ubuntu + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Ubuntu + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Ubuntu + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
</tbody>
</table>
doc/templates/conf.py.cn.in
浏览文件 @
9eaf4458
...
...
@@ -13,7 +13,7 @@
# serve to show the default.
import sys
import os, subprocess
sys.path.insert(0, os.path.abspath('@PADDLE_
SOURCE
_DIR@/python'))
sys.path.insert(0, os.path.abspath('@PADDLE_
BINARY
_DIR@/python'))
import shlex
from recommonmark import parser, transform
import paddle
...
...
doc/templates/conf.py.en.in
浏览文件 @
9eaf4458
...
...
@@ -13,7 +13,7 @@
# serve to show the default.
import sys
import os, subprocess
sys.path.insert(0, os.path.abspath('@PADDLE_
SOURCE
_DIR@/python'))
sys.path.insert(0, os.path.abspath('@PADDLE_
BINARY
_DIR@/python'))
import shlex
from recommonmark import parser, transform
import paddle
...
...
doc/v2/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -27,7 +27,7 @@ sphinx_add_target(paddle_v2_docs
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_EN
}
)
add_dependencies
(
paddle_v2_docs gen_proto_py
)
add_dependencies
(
paddle_v2_docs gen_proto_py
paddle_python
)
# configured documentation tools and intermediate build results
set
(
BINARY_BUILD_DIR_CN
"
${
CMAKE_CURRENT_BINARY_DIR
}
/cn/_build"
)
...
...
@@ -50,6 +50,6 @@ sphinx_add_target(paddle_v2_docs_cn
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_CN
}
)
add_dependencies
(
paddle_v2_docs_cn gen_proto_py
)
add_dependencies
(
paddle_v2_docs_cn gen_proto_py
paddle_python
)
add_subdirectory
(
api
)
doc/v2/api/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -19,4 +19,4 @@ sphinx_add_target(paddle_v2_apis
${
CMAKE_CURRENT_SOURCE_DIR
}
${
SPHINX_HTML_DIR_EN
}
)
add_dependencies
(
paddle_v2_apis gen_proto_py framework_py_proto copy_paddle_pybind
)
add_dependencies
(
paddle_v2_apis gen_proto_py framework_py_proto copy_paddle_pybind
paddle_python
)
paddle/api/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -89,16 +89,17 @@ SWIG_LINK_LIBRARIES(swig_paddle
${
START_END
}
)
add_custom_command
(
OUTPUT
${
PADDLE_SOURCE_DIR
}
/paddle/py_paddle/_swig_paddle.so
COMMAND cp
${
CMAKE_CURRENT_BINARY_DIR
}
/swig_paddle.py
${
PADDLE_SOURCE_DIR
}
/paddle/py_paddle
COMMAND cp
${
CMAKE_CURRENT_BINARY_DIR
}
/_swig_paddle.so
${
PADDLE_SOURCE_DIR
}
/paddle/py_paddle
COMMAND
${
CMAKE_COMMAND
}
-E touch .timestamp
add_custom_command
(
OUTPUT
${
PADDLE_BINARY_DIR
}
/python/py_paddle/_swig_paddle.so
COMMAND
${
CMAKE_COMMAND
}
-E make_directory
${
PADDLE_BINARY_DIR
}
/python/py_paddle
COMMAND cp
${
CMAKE_CURRENT_BINARY_DIR
}
/swig_paddle.py
${
PADDLE_BINARY_DIR
}
/python/py_paddle
COMMAND cp
${
CMAKE_CURRENT_BINARY_DIR
}
/_swig_paddle.so
${
PADDLE_BINARY_DIR
}
/python/py_paddle
COMMAND
${
CMAKE_COMMAND
}
-E touch
${
PADDLE_BINARY_DIR
}
/.timestamp
WORKING_DIRECTORY
${
PADDLE_SOURCE_DIR
}
/paddle
DEPENDS _swig_paddle
)
# TODO(yuyang18) : make wheel name calculated by cmake
add_custom_target
(
python_api_wheel ALL DEPENDS
${
PADDLE_
SOURCE_DIR
}
/paddle
/py_paddle/_swig_paddle.so
)
add_custom_target
(
python_api_wheel ALL DEPENDS
${
PADDLE_
BINARY_DIR
}
/python
/py_paddle/_swig_paddle.so
)
if
(
WITH_TESTING
)
IF
(
NOT PY_PIP_FOUND
)
...
...
paddle/api/test/CMakeLists.txt
浏览文件 @
9eaf4458
add_custom_command
(
OUTPUT
${
CMAKE_CURRENT_BINARY_DIR
}
/testTrain.py
COMMAND cp -r
${
CMAKE_CURRENT_SOURCE_DIR
}
/*.py
${
CMAKE_CURRENT_BINARY_DIR
}
)
add_custom_target
(
copy_api_test ALL DEPENDS testTrain.py
)
py_test
(
testTrain SRCS testTrain.py
)
py_test
(
testMatrix SRCS testMatrix.py
)
py_test
(
testVector SRCS testVector.py
)
...
...
paddle/fluid/
framework/
.clang-format
→
paddle/fluid/.clang-format
浏览文件 @
9eaf4458
文件已移动
paddle/fluid/framework/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -74,8 +74,8 @@ py_proto_compile(framework_py_proto SRCS framework.proto)
add_custom_target
(
framework_py_proto_init ALL COMMAND
${
CMAKE_COMMAND
}
-E touch __init__.py
)
add_dependencies
(
framework_py_proto framework_py_proto_init
)
add_custom_command
(
TARGET framework_py_proto POST_BUILD
COMMAND
${
CMAKE_COMMAND
}
-E make_directory
${
PADDLE_
SOURCE
_DIR
}
/python/paddle/fluid/proto
COMMAND cp *.py
${
PADDLE_
SOURCE
_DIR
}
/python/paddle/fluid/proto/
COMMAND
${
CMAKE_COMMAND
}
-E make_directory
${
PADDLE_
BINARY
_DIR
}
/python/paddle/fluid/proto
COMMAND cp *.py
${
PADDLE_
BINARY
_DIR
}
/python/paddle/fluid/proto/
COMMENT
"Copy generated python proto into directory paddle/fluid/proto."
WORKING_DIRECTORY
${
CMAKE_CURRENT_BINARY_DIR
}
)
...
...
paddle/fluid/framework/block_desc.h
浏览文件 @
9eaf4458
...
...
@@ -17,6 +17,7 @@ limitations under the License. */
#include <deque>
#include <memory>
#include <set>
#include <string>
#include <unordered_map>
#include <vector>
...
...
@@ -96,6 +97,8 @@ class BlockDesc {
*/
void
RemoveOp
(
size_t
s
,
size_t
e
);
void
RemoveVar
(
const
std
::
string
&
name
)
{
vars_
.
erase
(
name
);
}
std
::
vector
<
OpDesc
*>
AllOps
()
const
;
size_t
OpSize
()
const
{
return
ops_
.
size
();
}
...
...
paddle/fluid/framework/channel.h
浏览文件 @
9eaf4458
...
...
@@ -14,8 +14,8 @@ limitations under the License. */
#pragma once
#include <stddef.h> // for size_t
#include <condition_variable>
#include <stddef.h>
// for size_t
#include <condition_variable>
// NOLINT
#include <typeindex>
#include "paddle/fluid/platform/enforce.h"
...
...
@@ -216,7 +216,8 @@ class ChannelHolder {
template
<
typename
T
>
struct
PlaceholderImpl
:
public
Placeholder
{
PlaceholderImpl
(
size_t
buffer_size
)
:
type_
(
std
::
type_index
(
typeid
(
T
)))
{
explicit
PlaceholderImpl
(
size_t
buffer_size
)
:
type_
(
std
::
type_index
(
typeid
(
T
)))
{
channel_
.
reset
(
MakeChannel
<
T
>
(
buffer_size
));
}
...
...
paddle/fluid/framework/channel_impl.h
浏览文件 @
9eaf4458
...
...
@@ -15,7 +15,7 @@ limitations under the License. */
#pragma once
#include <stddef.h> // for size_t
#include <atomic>
#include <condition_variable>
#include <condition_variable>
// NOLINT
#include <deque>
#include "paddle/fluid/framework/channel.h"
#include "paddle/fluid/platform/enforce.h"
...
...
@@ -38,7 +38,7 @@ class ChannelImpl : public paddle::framework::Channel<T> {
virtual
void
Unlock
();
virtual
bool
IsClosed
();
virtual
void
Close
();
ChannelImpl
(
size_t
);
explicit
ChannelImpl
(
size_t
);
virtual
~
ChannelImpl
();
virtual
void
AddToSendQ
(
const
void
*
referrer
,
T
*
data
,
...
...
@@ -60,7 +60,7 @@ class ChannelImpl : public paddle::framework::Channel<T> {
const
void
*
referrer
;
// TODO(thuan): figure out better way to do this
std
::
function
<
bool
(
ChannelAction
)
>
callback
;
QueueMessage
(
T
*
item
)
explicit
QueueMessage
(
T
*
item
)
:
data
(
item
),
cond
(
std
::
make_shared
<
std
::
condition_variable_any
>
())
{}
QueueMessage
(
T
*
item
,
std
::
shared_ptr
<
std
::
condition_variable_any
>
cond
)
...
...
@@ -88,15 +88,15 @@ class ChannelImpl : public paddle::framework::Channel<T> {
}
std
::
shared_ptr
<
QueueMessage
>
get_first_message
(
std
::
deque
<
std
::
shared_ptr
<
QueueMessage
>>
&
queue
,
ChannelAction
action
)
{
while
(
!
queue
.
empty
())
{
std
::
deque
<
std
::
shared_ptr
<
QueueMessage
>>
*
queue
,
ChannelAction
action
)
{
while
(
!
queue
->
empty
())
{
// Check whether this message was added by Select
// If this was added by Select then execute the callback
// to check if you can execute this message. The callback
// can return false if some other case was executed in Select.
// In that case just discard this QueueMessage and process next.
std
::
shared_ptr
<
QueueMessage
>
m
=
queue
.
front
();
queue
.
pop_front
();
std
::
shared_ptr
<
QueueMessage
>
m
=
queue
->
front
();
queue
->
pop_front
();
if
(
m
->
callback
==
nullptr
||
m
->
callback
(
action
))
return
m
;
}
return
nullptr
;
...
...
@@ -147,7 +147,7 @@ void ChannelImpl<T>::Send(T *item) {
// to send to the receiver, bypassing the channel buffer if any
if
(
!
recvq
.
empty
())
{
std
::
shared_ptr
<
QueueMessage
>
m
=
get_first_message
(
recvq
,
ChannelAction
::
SEND
);
get_first_message
(
&
recvq
,
ChannelAction
::
SEND
);
if
(
m
!=
nullptr
)
{
*
(
m
->
data
)
=
std
::
move
(
*
item
);
...
...
@@ -198,7 +198,7 @@ bool ChannelImpl<T>::Receive(T *item) {
// buffer and move front of send queue to the buffer
if
(
!
sendq
.
empty
())
{
std
::
shared_ptr
<
QueueMessage
>
m
=
get_first_message
(
sendq
,
ChannelAction
::
RECEIVE
);
get_first_message
(
&
sendq
,
ChannelAction
::
RECEIVE
);
if
(
buf_
.
size
()
>
0
)
{
// Case 1 : Channel is Buffered
// Do Data transfer from front of buffer
...
...
@@ -219,8 +219,9 @@ bool ChannelImpl<T>::Receive(T *item) {
if
(
m
!=
nullptr
)
{
*
item
=
std
::
move
(
*
(
m
->
data
));
m
->
Notify
();
}
else
}
else
{
return
recv_return
(
Receive
(
item
));
}
}
return
recv_return
(
true
);
}
...
...
paddle/fluid/framework/channel_test.cc
浏览文件 @
9eaf4458
...
...
@@ -14,8 +14,8 @@ limitations under the License. */
#include "paddle/fluid/framework/channel.h"
#include <chrono>
#include <thread>
#include <chrono>
// NOLINT
#include <thread>
// NOLINT
#include "gtest/gtest.h"
using
paddle
::
framework
::
Channel
;
...
...
@@ -166,9 +166,9 @@ TEST(Channel, ConcurrentSendNonConcurrentReceiveWithSufficientBufferSize) {
std
::
thread
t
([
&
]()
{
// Try to write more than buffer size.
for
(
size_t
i
=
0
;
i
<
2
*
buffer_size
;
++
i
)
{
if
(
i
<
buffer_size
)
if
(
i
<
buffer_size
)
{
ch
->
Send
(
&
i
);
// should block after 10 iterations
else
{
}
else
{
bool
is_exception
=
false
;
try
{
ch
->
Send
(
&
i
);
...
...
@@ -212,12 +212,12 @@ TEST(Channel, RecevingOrderEqualToSendingOrderWithBufferedChannel3) {
}
void
ChannelCloseUnblocksReceiversTest
(
Channel
<
int
>
*
ch
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
// Launches threads that try to read and are blocked because of no writers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -230,7 +230,7 @@ void ChannelCloseUnblocksReceiversTest(Channel<int> *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait 0.2 sec
// Verify that all the threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
...
...
@@ -241,21 +241,21 @@ void ChannelCloseUnblocksReceiversTest(Channel<int> *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait 0.2 sec
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
void
ChannelCloseUnblocksSendersTest
(
Channel
<
int
>
*
ch
,
bool
isBuffered
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
bool
send_success
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
bool
send_success
[
kNumT
hreads
];
// Launches threads that try to write and are blocked because of no readers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
send_success
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
...
...
@@ -277,13 +277,13 @@ void ChannelCloseUnblocksSendersTest(Channel<int> *ch, bool isBuffered) {
if
(
isBuffered
)
{
// If ch is Buffered, atleast 4 threads must be blocked.
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
!
thread_ended
[
i
])
ct
++
;
}
EXPECT_GE
(
ct
,
4
);
}
else
{
// If ch is UnBuffered, all the threads should be blocked.
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
}
...
...
@@ -294,21 +294,21 @@ void ChannelCloseUnblocksSendersTest(Channel<int> *ch, bool isBuffered) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
if
(
isBuffered
)
{
// Verify that only 1 send was successful
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
send_success
[
i
])
ct
++
;
}
// Only 1 send must be successful
EXPECT_EQ
(
ct
,
1
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
// This tests that closing a buffered channel also unblocks
...
...
@@ -409,13 +409,13 @@ TEST(Channel, UnbufferedMoreReceiveLessSendTest) {
// This tests that destroying a channel unblocks
// any senders waiting for channel to have write space
void
ChannelDestroyUnblockSenders
(
Channel
<
int
>
*
ch
,
bool
isBuffered
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
bool
send_success
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
bool
send_success
[
kNumT
hreads
];
// Launches threads that try to write and are blocked because of no readers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
send_success
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
...
...
@@ -438,14 +438,14 @@ void ChannelDestroyUnblockSenders(Channel<int> *ch, bool isBuffered) {
if
(
isBuffered
)
{
// If channel is buffered, verify that atleast 4 threads are blocked
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
thread_ended
[
i
]
==
false
)
ct
++
;
}
// Atleast 4 threads must be blocked
EXPECT_GE
(
ct
,
4
);
}
else
{
// Verify that all the threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
}
...
...
@@ -454,13 +454,13 @@ void ChannelDestroyUnblockSenders(Channel<int> *ch, bool isBuffered) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
// Count number of successful sends
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
send_success
[
i
])
ct
++
;
}
...
...
@@ -473,18 +473,18 @@ void ChannelDestroyUnblockSenders(Channel<int> *ch, bool isBuffered) {
}
// Join all threads
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
// This tests that destroying a channel also unblocks
// any receivers waiting on the channel
void
ChannelDestroyUnblockReceivers
(
Channel
<
int
>
*
ch
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
// Launches threads that try to read and are blocked because of no writers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -498,18 +498,18 @@ void ChannelDestroyUnblockReceivers(Channel<int> *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
100
));
// wait
// Verify that all threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
// delete the channel
delete
ch
;
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
TEST
(
Channel
,
BufferedChannelDestroyUnblocksReceiversTest
)
{
...
...
@@ -679,12 +679,12 @@ TEST(ChannelHolder, TypeMismatchReceiveTest) {
}
void
ChannelHolderCloseUnblocksReceiversTest
(
ChannelHolder
*
ch
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
// Launches threads that try to read and are blocked because of no writers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -697,7 +697,7 @@ void ChannelHolderCloseUnblocksReceiversTest(ChannelHolder *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait 0.2 sec
// Verify that all the threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
...
...
@@ -708,21 +708,21 @@ void ChannelHolderCloseUnblocksReceiversTest(ChannelHolder *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait 0.2 sec
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
void
ChannelHolderCloseUnblocksSendersTest
(
ChannelHolder
*
ch
,
bool
isBuffered
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
bool
send_success
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
bool
send_success
[
kNumT
hreads
];
// Launches threads that try to write and are blocked because of no readers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
send_success
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
...
...
@@ -744,13 +744,13 @@ void ChannelHolderCloseUnblocksSendersTest(ChannelHolder *ch, bool isBuffered) {
if
(
isBuffered
)
{
// If ch is Buffered, atleast 4 threads must be blocked.
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
!
thread_ended
[
i
])
ct
++
;
}
EXPECT_GE
(
ct
,
4
);
}
else
{
// If ch is UnBuffered, all the threads should be blocked.
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
}
...
...
@@ -761,21 +761,21 @@ void ChannelHolderCloseUnblocksSendersTest(ChannelHolder *ch, bool isBuffered) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
if
(
isBuffered
)
{
// Verify that only 1 send was successful
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
send_success
[
i
])
ct
++
;
}
// Only 1 send must be successful
EXPECT_EQ
(
ct
,
1
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
// This tests that closing a channelholder unblocks
...
...
@@ -813,13 +813,13 @@ TEST(Channel, ChannelHolderCloseUnblocksSendersTest) {
// This tests that destroying a channelholder unblocks
// any senders waiting for channel
void
ChannelHolderDestroyUnblockSenders
(
ChannelHolder
*
ch
,
bool
isBuffered
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
bool
send_success
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
bool
send_success
[
kNumT
hreads
];
// Launches threads that try to write and are blocked because of no readers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
send_success
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
...
...
@@ -841,14 +841,14 @@ void ChannelHolderDestroyUnblockSenders(ChannelHolder *ch, bool isBuffered) {
if
(
isBuffered
)
{
// If channel is buffered, verify that atleast 4 threads are blocked
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
thread_ended
[
i
]
==
false
)
ct
++
;
}
// Atleast 4 threads must be blocked
EXPECT_GE
(
ct
,
4
);
}
else
{
// Verify that all the threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
}
...
...
@@ -857,13 +857,13 @@ void ChannelHolderDestroyUnblockSenders(ChannelHolder *ch, bool isBuffered) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
// Count number of successfuld sends
int
ct
=
0
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
if
(
send_success
[
i
])
ct
++
;
}
...
...
@@ -876,18 +876,18 @@ void ChannelHolderDestroyUnblockSenders(ChannelHolder *ch, bool isBuffered) {
}
// Join all threads
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
// This tests that destroying a channelholder also unblocks
// any receivers waiting on the channel
void
ChannelHolderDestroyUnblockReceivers
(
ChannelHolder
*
ch
)
{
size_t
num_t
hreads
=
5
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
const
size_t
kNumT
hreads
=
5
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
// Launches threads that try to read and are blocked because of no writers
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -901,18 +901,18 @@ void ChannelHolderDestroyUnblockReceivers(ChannelHolder *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads are blocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
false
);
}
// delete the channel
delete
ch
;
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
200
));
// wait
// Verify that all threads got unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
TEST
(
ChannelHolder
,
ChannelHolderDestroyUnblocksReceiversTest
)
{
...
...
@@ -945,12 +945,12 @@ TEST(ChannelHolder, ChannelHolderDestroyUnblocksSendersTest) {
// This tests that closing a channelholder many times.
void
ChannelHolderManyTimesClose
(
ChannelHolder
*
ch
)
{
const
int
num_t
hreads
=
15
;
std
::
thread
t
[
num_t
hreads
];
bool
thread_ended
[
num_t
hreads
];
const
int
kNumT
hreads
=
15
;
std
::
thread
t
[
kNumT
hreads
];
bool
thread_ended
[
kNumT
hreads
];
// Launches threads that try to send data to channel.
for
(
size_t
i
=
0
;
i
<
num_t
hreads
/
3
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
/
3
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
ended
)
{
...
...
@@ -962,7 +962,7 @@ void ChannelHolderManyTimesClose(ChannelHolder *ch) {
}
// Launches threads that try to receive data to channel.
for
(
size_t
i
=
num_threads
/
3
;
i
<
2
*
num_t
hreads
/
3
;
i
++
)
{
for
(
size_t
i
=
kNumThreads
/
3
;
i
<
2
*
kNumT
hreads
/
3
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -976,7 +976,7 @@ void ChannelHolderManyTimesClose(ChannelHolder *ch) {
}
// Launches threads that try to close the channel.
for
(
size_t
i
=
2
*
num_threads
/
3
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
2
*
kNumThreads
/
3
;
i
<
kNumT
hreads
;
i
++
)
{
thread_ended
[
i
]
=
false
;
t
[
i
]
=
std
::
thread
(
[
&
](
bool
*
p
)
{
...
...
@@ -991,13 +991,13 @@ void ChannelHolderManyTimesClose(ChannelHolder *ch) {
std
::
this_thread
::
sleep_for
(
std
::
chrono
::
milliseconds
(
100
));
// wait
// Verify that all threads are unblocked
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
{
EXPECT_EQ
(
thread_ended
[
i
],
true
);
}
EXPECT_TRUE
(
ch
->
IsClosed
());
// delete the channel
delete
ch
;
for
(
size_t
i
=
0
;
i
<
num_t
hreads
;
i
++
)
t
[
i
].
join
();
for
(
size_t
i
=
0
;
i
<
kNumT
hreads
;
i
++
)
t
[
i
].
join
();
}
TEST
(
ChannelHolder
,
ChannelHolderManyTimesCloseTest
)
{
...
...
paddle/fluid/framework/details/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -16,6 +16,6 @@ else()
endif
()
cc_library
(
multi_devices_graph_builder SRCS multi_devices_graph_builder.cc DEPS ssa_graph_builder computation_op_handle
scale_loss_grad_op_handle
${
multi_devices_graph_builder_deps
}
)
cc_library
(
ssa_graph_executor SRCS ssa_graph_executor.cc DEPS ssa_graph
)
cc_library
(
ssa_graph_executor SRCS ssa_graph_executor.cc DEPS ssa_graph
framework_proto
)
cc_library
(
threaded_ssa_graph_executor SRCS threaded_ssa_graph_executor.cc DEPS fetch_op_handle ssa_graph_executor scope
simple_threadpool device_context
)
paddle/fluid/framework/lod_tensor.h
浏览文件 @
9eaf4458
...
...
@@ -142,6 +142,7 @@ class LoDTensor : public Tensor {
return
(
lod_
)[
level
].
size
()
-
1
;
}
// Split LoDTensor and copy to each place specified in places.
std
::
vector
<
LoDTensor
>
SplitLoDTensor
(
const
std
::
vector
<
platform
::
Place
>
places
)
const
;
...
...
paddle/fluid/framework/operator.cc
浏览文件 @
9eaf4458
...
...
@@ -35,6 +35,17 @@ std::vector<std::tuple<platform::Place, LibraryType>> kKernelPriority = {
std
::
make_tuple
(
platform
::
CPUPlace
(),
LibraryType
::
kPlain
),
};
proto
::
VarType
::
Type
GetDataTypeOfVar
(
const
Variable
*
var
)
{
if
(
var
->
IsType
<
framework
::
LoDTensor
>
())
{
return
framework
::
ToDataType
(
var
->
Get
<
framework
::
LoDTensor
>
().
type
());
}
else
if
(
var
->
IsType
<
framework
::
SelectedRows
>
())
{
return
framework
::
ToDataType
(
var
->
Get
<
framework
::
SelectedRows
>
().
value
().
type
());
}
else
{
PADDLE_THROW
(
"Var should be LoDTensor or SelectedRows"
);
}
}
static
DDim
GetDims
(
const
Scope
&
scope
,
const
std
::
string
&
name
)
{
Variable
*
var
=
scope
.
FindVar
(
name
);
if
(
var
==
nullptr
)
{
...
...
paddle/fluid/framework/operator.h
浏览文件 @
9eaf4458
...
...
@@ -61,6 +61,8 @@ inline std::string GradVarName(const std::string& var_name) {
return
var_name
+
kGradVarSuffix
;
}
proto
::
VarType
::
Type
GetDataTypeOfVar
(
const
Variable
*
var
);
class
OperatorBase
;
class
ExecutionContext
;
...
...
paddle/fluid/framework/parallel_executor.cc
浏览文件 @
9eaf4458
...
...
@@ -150,13 +150,30 @@ void ParallelExecutor::BCastParamsToGPUs(
#endif
}
void
ParallelExecutor
::
Run
(
const
std
::
vector
<
std
::
string
>
&
fetch_tensors
,
const
std
::
string
&
fetched_var_name
)
{
void
ParallelExecutor
::
Run
(
const
std
::
vector
<
std
::
string
>
&
fetch_tensors
,
const
std
::
string
&
fetched_var_name
,
const
std
::
unordered_map
<
std
::
string
,
LoDTensor
>
&
feed_tensors
)
{
platform
::
RecordBlock
b
(
0
);
SplitTensorToPlaces
(
feed_tensors
);
auto
fetch_data
=
member_
->
executor_
->
Run
(
fetch_tensors
);
*
member_
->
global_scope_
->
Var
(
fetched_var_name
)
->
GetMutable
<
FeedFetchList
>
()
=
fetch_data
;
}
void
ParallelExecutor
::
SplitTensorToPlaces
(
const
std
::
unordered_map
<
std
::
string
,
LoDTensor
>
&
feed_tensors
)
{
for
(
auto
it
:
feed_tensors
)
{
auto
lod_tensors
=
it
.
second
.
SplitLoDTensor
(
member_
->
places_
);
for
(
size_t
j
=
0
;
j
<
member_
->
places_
.
size
();
++
j
)
{
// TODO(panxy0718): Do I need to delete this var?
member_
->
local_scopes_
[
j
]
->
Var
(
it
.
first
)
->
GetMutable
<
LoDTensor
>
()
->
ShareDataWith
(
lod_tensors
[
j
]);
}
}
}
}
// namespace framework
}
// namespace paddle
paddle/fluid/framework/parallel_executor.h
浏览文件 @
9eaf4458
...
...
@@ -42,9 +42,13 @@ class ParallelExecutor {
bool
allow_op_delay
);
void
Run
(
const
std
::
vector
<
std
::
string
>&
fetch_tensors
,
const
std
::
string
&
fetched_var_name
=
"fetched_var"
);
const
std
::
string
&
fetched_var_name
,
const
std
::
unordered_map
<
std
::
string
,
LoDTensor
>&
feed_tensors
);
private:
void
SplitTensorToPlaces
(
const
std
::
unordered_map
<
std
::
string
,
LoDTensor
>&
feed_tensors
);
ParallelExecutorPrivate
*
member_
;
void
BCastParamsToGPUs
(
const
ProgramDesc
&
startup_program
)
const
;
...
...
paddle/fluid/framework/selected_rows.cc
浏览文件 @
9eaf4458
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
...
...
@@ -13,6 +16,7 @@ limitations under the License. */
namespace
paddle
{
namespace
framework
{
void
SerializeToStream
(
std
::
ostream
&
os
,
const
SelectedRows
&
selected_rows
,
const
platform
::
DeviceContext
&
dev_ctx
)
{
{
// the 1st field, uint32_t version
...
...
paddle/fluid/framework/selected_rows.h
浏览文件 @
9eaf4458
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
...
...
@@ -47,6 +50,15 @@ class SelectedRows {
void
set_rows
(
const
Vector
<
int64_t
>&
rows
)
{
rows_
=
rows
;
}
/**
* get the index of id in rows
*/
int64_t
index
(
int64_t
id
)
const
{
auto
it
=
std
::
find
(
rows_
.
begin
(),
rows_
.
end
(),
id
);
PADDLE_ENFORCE
(
it
!=
rows_
.
end
(),
"id should be in rows"
);
return
static_cast
<
int64_t
>
(
std
::
distance
(
rows_
.
begin
(),
it
));
}
DDim
GetCompleteDims
()
const
{
std
::
vector
<
int64_t
>
dims
=
vectorize
(
value_
->
dims
());
dims
[
0
]
=
height_
;
...
...
paddle/fluid/framework/tensor_impl.h
浏览文件 @
9eaf4458
...
...
@@ -128,13 +128,20 @@ inline void* Tensor::mutable_data(platform::Place place, std::type_index type) {
if
(
platform
::
is_cpu_place
(
place
))
{
holder_
.
reset
(
new
PlaceholderImpl
<
platform
::
CPUPlace
>
(
boost
::
get
<
platform
::
CPUPlace
>
(
place
),
size
,
type
));
}
else
if
(
platform
::
is_gpu_place
(
place
))
{
}
else
if
(
platform
::
is_gpu_place
(
place
)
||
platform
::
is_cuda_pinned_place
(
place
))
{
#ifndef PADDLE_WITH_CUDA
PADDLE_THROW
(
"'CUDAPlace' is not supported in CPU only device."
);
PADDLE_THROW
(
"CUDAPlace or CUDAPinnedPlace is not supported in CPU-only mode."
);
}
#else
holder_
.
reset
(
new
PlaceholderImpl
<
platform
::
CUDAPlace
>
(
boost
::
get
<
platform
::
CUDAPlace
>
(
place
),
size
,
type
));
if
(
platform
::
is_gpu_place
(
place
))
{
holder_
.
reset
(
new
PlaceholderImpl
<
platform
::
CUDAPlace
>
(
boost
::
get
<
platform
::
CUDAPlace
>
(
place
),
size
,
type
));
}
else
if
(
platform
::
is_cuda_pinned_place
(
place
))
{
holder_
.
reset
(
new
PlaceholderImpl
<
platform
::
CUDAPinnedPlace
>
(
boost
::
get
<
platform
::
CUDAPinnedPlace
>
(
place
),
size
,
type
));
}
}
#endif
offset_
=
0
;
...
...
@@ -145,7 +152,7 @@ inline void* Tensor::mutable_data(platform::Place place, std::type_index type) {
inline
void
*
Tensor
::
mutable_data
(
platform
::
Place
place
)
{
PADDLE_ENFORCE
(
this
->
holder_
!=
nullptr
,
"Cannot invoke mutable data if current hold nothing"
);
"Cannot invoke mutable data if current hold nothing
.
"
);
return
mutable_data
(
place
,
holder_
->
type
());
}
...
...
paddle/fluid/framework/tuple.h
浏览文件 @
9eaf4458
...
...
@@ -35,24 +35,25 @@ class Tuple {
public:
using
ElementVars
=
std
::
vector
<
ElementVar
>
;
Tuple
(
std
::
vector
<
ElementVar
>&
var
,
std
::
vector
<
VarDesc
>&
var_desc
)
Tuple
(
const
std
::
vector
<
ElementVar
>&
var
,
const
std
::
vector
<
VarDesc
>&
var_desc
)
:
var_
(
var
),
var_desc_
(
var_desc
)
{}
Tuple
(
std
::
vector
<
ElementVar
>&
var
)
:
var_
(
var
)
{}
explicit
Tuple
(
std
::
vector
<
ElementVar
>&
var
)
:
var_
(
var
)
{}
ElementVar
get
(
int
idx
)
const
{
return
var_
[
idx
];
}
;
ElementVar
get
(
int
idx
)
const
{
return
var_
[
idx
];
}
ElementVar
&
get
(
int
idx
)
{
return
var_
[
idx
];
}
;
ElementVar
&
get
(
int
idx
)
{
return
var_
[
idx
];
}
bool
isSameType
(
Tuple
&
t
)
const
;
bool
isSameType
(
const
Tuple
&
t
)
const
;
size_t
getSize
()
const
{
return
var_
.
size
();
}
;
size_t
getSize
()
const
{
return
var_
.
size
();
}
private:
ElementVars
var_
;
std
::
vector
<
VarDesc
>
var_desc_
;
};
bool
Tuple
::
isSameType
(
Tuple
&
t
)
const
{
bool
Tuple
::
isSameType
(
const
Tuple
&
t
)
const
{
size_t
tuple_size
=
getSize
();
if
(
tuple_size
!=
t
.
getSize
())
{
return
false
;
...
...
paddle/fluid/inference/io.cc
浏览文件 @
9eaf4458
...
...
@@ -41,8 +41,7 @@ bool IsPersistable(const framework::VarDesc* var) {
return
false
;
}
void
LoadPersistables
(
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
void
LoadPersistables
(
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
const
framework
::
ProgramDesc
&
main_program
,
const
std
::
string
&
dirname
,
const
std
::
string
&
param_filename
)
{
...
...
@@ -108,10 +107,8 @@ std::unique_ptr<framework::ProgramDesc> Load(framework::Executor& executor,
}
std
::
unique_ptr
<
framework
::
ProgramDesc
>
Load
(
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
const
std
::
string
&
prog_filename
,
const
std
::
string
&
param_filename
)
{
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
const
std
::
string
&
prog_filename
,
const
std
::
string
&
param_filename
)
{
std
::
string
model_filename
=
prog_filename
;
std
::
string
program_desc_str
;
ReadBinaryFile
(
model_filename
,
program_desc_str
);
...
...
paddle/fluid/inference/io.h
浏览文件 @
9eaf4458
...
...
@@ -24,8 +24,7 @@ limitations under the License. */
namespace
paddle
{
namespace
inference
{
void
LoadPersistables
(
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
void
LoadPersistables
(
framework
::
Executor
&
executor
,
framework
::
Scope
&
scope
,
const
framework
::
ProgramDesc
&
main_program
,
const
std
::
string
&
dirname
,
const
std
::
string
&
param_filename
);
...
...
paddle/fluid/inference/tests/book/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -4,7 +4,7 @@ function(inference_test TARGET_NAME)
set
(
multiValueArgs ARGS
)
cmake_parse_arguments
(
inference_test
"
${
options
}
"
"
${
oneValueArgs
}
"
"
${
multiValueArgs
}
"
${
ARGN
}
)
set
(
PYTHON_TESTS_DIR
${
PADDLE_
SOURCE
_DIR
}
/python/paddle/fluid/tests
)
set
(
PYTHON_TESTS_DIR
${
PADDLE_
BINARY
_DIR
}
/python/paddle/fluid/tests
)
set
(
arg_list
""
)
if
(
inference_test_ARGS
)
foreach
(
arg
${
inference_test_ARGS
}
)
...
...
paddle/fluid/inference/tests/book/test_inference_fit_a_line.cc
浏览文件 @
9eaf4458
...
...
@@ -9,8 +9,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -30,8 +30,8 @@ TEST(inference, fit_a_line) {
// The second dim of the input tensor should be 13
// The input data should be >= 0
int64_t
batch_size
=
10
;
SetupTensor
<
float
>
(
input
,
{
batch_size
,
13
},
static_cast
<
float
>
(
0
),
static_cast
<
float
>
(
10
));
SetupTensor
<
float
>
(
&
input
,
{
batch_size
,
13
},
static_cast
<
float
>
(
0
),
static_cast
<
float
>
(
10
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
input
);
...
...
paddle/fluid/inference/tests/book/test_inference_image_classification.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -35,10 +35,8 @@ TEST(inference, image_classification) {
paddle
::
framework
::
LoDTensor
input
;
// Use normilized image pixels as input data,
// which should be in the range [0.0, 1.0].
SetupTensor
<
float
>
(
input
,
{
FLAGS_batch_size
,
3
,
32
,
32
},
static_cast
<
float
>
(
0
),
static_cast
<
float
>
(
1
));
SetupTensor
<
float
>
(
&
input
,
{
FLAGS_batch_size
,
3
,
32
,
32
},
static_cast
<
float
>
(
0
),
static_cast
<
float
>
(
1
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
input
);
...
...
@@ -48,8 +46,8 @@ TEST(inference, image_classification) {
// Run inference on CPU
LOG
(
INFO
)
<<
"--- CPU Runs: ---"
;
TestInference
<
paddle
::
platform
::
CPUPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs1
,
FLAGS_repeat
);
TestInference
<
paddle
::
platform
::
CPUPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs1
,
FLAGS_repeat
);
LOG
(
INFO
)
<<
output1
.
dims
();
#ifdef PADDLE_WITH_CUDA
...
...
@@ -59,8 +57,8 @@ TEST(inference, image_classification) {
// Run inference on CUDA GPU
LOG
(
INFO
)
<<
"--- GPU Runs: ---"
;
TestInference
<
paddle
::
platform
::
CUDAPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs2
,
FLAGS_repeat
);
TestInference
<
paddle
::
platform
::
CUDAPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs2
,
FLAGS_repeat
);
LOG
(
INFO
)
<<
output2
.
dims
();
CheckError
<
float
>
(
output1
,
output2
);
...
...
paddle/fluid/inference/tests/book/test_inference_label_semantic_roles.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -36,37 +36,21 @@ TEST(inference, label_semantic_roles) {
int64_t
predicate_dict_len
=
3162
;
int64_t
mark_dict_len
=
2
;
SetupLoDTensor
(
word
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
word
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
predicate
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
predicate
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
predicate_dict_len
-
1
));
SetupLoDTensor
(
ctx_n2
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
ctx_n2
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
ctx_n1
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
ctx_n1
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
ctx_0
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
ctx_0
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
ctx_p1
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
ctx_p1
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
ctx_p2
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
ctx_p2
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
SetupLoDTensor
(
mark
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
mark
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
mark_dict_len
-
1
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
...
...
paddle/fluid/inference/tests/book/test_inference_recognize_digits.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -35,10 +35,8 @@ TEST(inference, recognize_digits) {
paddle
::
framework
::
LoDTensor
input
;
// Use normilized image pixels as input data,
// which should be in the range [-1.0, 1.0].
SetupTensor
<
float
>
(
input
,
{
FLAGS_batch_size
,
1
,
28
,
28
},
static_cast
<
float
>
(
-
1
),
static_cast
<
float
>
(
1
));
SetupTensor
<
float
>
(
&
input
,
{
FLAGS_batch_size
,
1
,
28
,
28
},
static_cast
<
float
>
(
-
1
),
static_cast
<
float
>
(
1
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
input
);
...
...
@@ -49,8 +47,8 @@ TEST(inference, recognize_digits) {
// Run inference on CPU
LOG
(
INFO
)
<<
"--- CPU Runs: is_combined="
<<
is_combined
<<
" ---"
;
TestInference
<
paddle
::
platform
::
CPUPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs1
,
FLAGS_repeat
,
is_combined
);
TestInference
<
paddle
::
platform
::
CPUPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs1
,
FLAGS_repeat
,
is_combined
);
LOG
(
INFO
)
<<
output1
.
dims
();
#ifdef PADDLE_WITH_CUDA
...
...
@@ -60,8 +58,8 @@ TEST(inference, recognize_digits) {
// Run inference on CUDA GPU
LOG
(
INFO
)
<<
"--- GPU Runs: is_combined="
<<
is_combined
<<
" ---"
;
TestInference
<
paddle
::
platform
::
CUDAPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs2
,
FLAGS_repeat
,
is_combined
);
TestInference
<
paddle
::
platform
::
CUDAPlace
>
(
dirname
,
cpu_feeds
,
cpu_fetchs2
,
FLAGS_repeat
,
is_combined
);
LOG
(
INFO
)
<<
output2
.
dims
();
CheckError
<
float
>
(
output1
,
output2
);
...
...
paddle/fluid/inference/tests/book/test_inference_recommender_system.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -36,25 +36,25 @@ TEST(inference, recommender_system) {
// Use the first data from paddle.dataset.movielens.test() as input
std
::
vector
<
int64_t
>
user_id_data
=
{
1
};
SetupTensor
<
int64_t
>
(
user_id
,
{
batch_size
,
1
},
user_id_data
);
SetupTensor
<
int64_t
>
(
&
user_id
,
{
batch_size
,
1
},
user_id_data
);
std
::
vector
<
int64_t
>
gender_id_data
=
{
1
};
SetupTensor
<
int64_t
>
(
gender_id
,
{
batch_size
,
1
},
gender_id_data
);
SetupTensor
<
int64_t
>
(
&
gender_id
,
{
batch_size
,
1
},
gender_id_data
);
std
::
vector
<
int64_t
>
age_id_data
=
{
0
};
SetupTensor
<
int64_t
>
(
age_id
,
{
batch_size
,
1
},
age_id_data
);
SetupTensor
<
int64_t
>
(
&
age_id
,
{
batch_size
,
1
},
age_id_data
);
std
::
vector
<
int64_t
>
job_id_data
=
{
10
};
SetupTensor
<
int64_t
>
(
job_id
,
{
batch_size
,
1
},
job_id_data
);
SetupTensor
<
int64_t
>
(
&
job_id
,
{
batch_size
,
1
},
job_id_data
);
std
::
vector
<
int64_t
>
movie_id_data
=
{
783
};
SetupTensor
<
int64_t
>
(
movie_id
,
{
batch_size
,
1
},
movie_id_data
);
SetupTensor
<
int64_t
>
(
&
movie_id
,
{
batch_size
,
1
},
movie_id_data
);
std
::
vector
<
int64_t
>
category_id_data
=
{
10
,
8
,
9
};
SetupLoDTensor
<
int64_t
>
(
category_id
,
{
3
,
1
},
{{
0
,
3
}},
category_id_data
);
SetupLoDTensor
<
int64_t
>
(
&
category_id
,
{
3
,
1
},
{{
0
,
3
}},
category_id_data
);
std
::
vector
<
int64_t
>
movie_title_data
=
{
1069
,
4140
,
2923
,
710
,
988
};
SetupLoDTensor
<
int64_t
>
(
movie_title
,
{
5
,
1
},
{{
0
,
5
}},
movie_title_data
);
SetupLoDTensor
<
int64_t
>
(
&
movie_title
,
{
5
,
1
},
{{
0
,
5
}},
movie_title_data
);
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
user_id
);
...
...
paddle/fluid/inference/tests/book/test_inference_rnn_encoder_decoder.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -32,10 +32,10 @@ TEST(inference, rnn_encoder_decoder) {
paddle
::
framework
::
LoDTensor
word_data
,
trg_word
;
paddle
::
framework
::
LoD
lod
{{
0
,
4
,
10
}};
SetupLoDTensor
(
word_data
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
1
));
SetupLoDTensor
(
trg_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
1
));
SetupLoDTensor
(
&
word_data
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
1
));
SetupLoDTensor
(
&
trg_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
1
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
word_data
);
...
...
paddle/fluid/inference/tests/book/test_inference_understand_sentiment.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -33,9 +33,7 @@ TEST(inference, understand_sentiment) {
paddle
::
framework
::
LoD
lod
{{
0
,
4
,
10
}};
int64_t
word_dict_len
=
5147
;
SetupLoDTensor
(
words
,
lod
,
static_cast
<
int64_t
>
(
0
),
SetupLoDTensor
(
&
words
,
lod
,
static_cast
<
int64_t
>
(
0
),
static_cast
<
int64_t
>
(
word_dict_len
-
1
));
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
...
...
paddle/fluid/inference/tests/book/test_inference_word2vec.cc
浏览文件 @
9eaf4458
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "gflags/gflags.h"
#include "gtest/gtest.h"
#include "paddle/fluid/inference/tests/test_helper.h"
DEFINE_string
(
dirname
,
""
,
"Directory of the inference model."
);
...
...
@@ -33,10 +33,10 @@ TEST(inference, word2vec) {
paddle
::
framework
::
LoD
lod
{{
0
,
1
}};
int64_t
dict_size
=
2073
;
// The size of dictionary
SetupLoDTensor
(
first_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
second_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
third_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
fourth_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
&
first_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
&
second_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
&
third_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
SetupLoDTensor
(
&
fourth_word
,
lod
,
static_cast
<
int64_t
>
(
0
),
dict_size
-
1
);
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>
cpu_feeds
;
cpu_feeds
.
push_back
(
&
first_word
);
...
...
paddle/fluid/inference/tests/test_helper.h
浏览文件 @
9eaf4458
...
...
@@ -11,59 +11,59 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <map>
#include <random>
#include <string>
#include <vector>
#include <time.h>
#include "paddle/fluid/framework/lod_tensor.h"
#include "paddle/fluid/inference/io.h"
#include "paddle/fluid/platform/profiler.h"
template
<
typename
T
>
void
SetupTensor
(
paddle
::
framework
::
LoDTensor
&
input
,
paddle
::
framework
::
DDim
dims
,
T
lower
,
T
upper
)
{
srand
(
time
(
0
));
T
*
input_ptr
=
input
.
mutable_data
<
T
>
(
dims
,
paddle
::
platform
::
CPUPlace
());
for
(
int
i
=
0
;
i
<
input
.
numel
();
++
i
)
{
input_ptr
[
i
]
=
(
static_cast
<
T
>
(
rand
())
/
static_cast
<
T
>
(
RAND_MAX
))
*
(
upper
-
lower
)
+
lower
;
void
SetupTensor
(
paddle
::
framework
::
LoDTensor
*
input
,
paddle
::
framework
::
DDim
dims
,
T
lower
,
T
upper
)
{
std
::
mt19937
rng
(
100
);
// An arbitrarily chosen but fixed seed.
std
::
uniform_real_distribution
<
double
>
uniform_dist
(
0
,
1
);
T
*
input_ptr
=
input
->
mutable_data
<
T
>
(
dims
,
paddle
::
platform
::
CPUPlace
());
for
(
int
i
=
0
;
i
<
input
->
numel
();
++
i
)
{
input_ptr
[
i
]
=
static_cast
<
T
>
(
uniform_dist
(
rng
)
*
(
upper
-
lower
)
+
lower
);
}
}
template
<
typename
T
>
void
SetupTensor
(
paddle
::
framework
::
LoDTensor
&
input
,
paddle
::
framework
::
DDim
dims
,
std
::
vector
<
T
>&
data
)
{
void
SetupTensor
(
paddle
::
framework
::
LoDTensor
*
input
,
paddle
::
framework
::
DDim
dims
,
const
std
::
vector
<
T
>&
data
)
{
CHECK_EQ
(
paddle
::
framework
::
product
(
dims
),
static_cast
<
int64_t
>
(
data
.
size
()));
T
*
input_ptr
=
input
.
mutable_data
<
T
>
(
dims
,
paddle
::
platform
::
CPUPlace
());
memcpy
(
input_ptr
,
data
.
data
(),
input
.
numel
()
*
sizeof
(
T
));
T
*
input_ptr
=
input
->
mutable_data
<
T
>
(
dims
,
paddle
::
platform
::
CPUPlace
());
memcpy
(
input_ptr
,
data
.
data
(),
input
->
numel
()
*
sizeof
(
T
));
}
template
<
typename
T
>
void
SetupLoDTensor
(
paddle
::
framework
::
LoDTensor
&
input
,
paddle
::
framework
::
LoD
&
lod
,
T
lower
,
T
upper
)
{
input
.
set_lod
(
lod
);
void
SetupLoDTensor
(
paddle
::
framework
::
LoDTensor
*
input
,
const
paddle
::
framework
::
LoD
&
lod
,
T
lower
,
T
upper
)
{
input
->
set_lod
(
lod
);
int
dim
=
lod
[
0
][
lod
[
0
].
size
()
-
1
];
SetupTensor
<
T
>
(
input
,
{
dim
,
1
},
lower
,
upper
);
}
template
<
typename
T
>
void
SetupLoDTensor
(
paddle
::
framework
::
LoDTensor
&
input
,
void
SetupLoDTensor
(
paddle
::
framework
::
LoDTensor
*
input
,
paddle
::
framework
::
DDim
dims
,
paddle
::
framework
::
LoD
lod
,
std
::
vector
<
T
>&
data
)
{
const
paddle
::
framework
::
LoD
lod
,
const
std
::
vector
<
T
>&
data
)
{
const
size_t
level
=
lod
.
size
()
-
1
;
CHECK_EQ
(
dims
[
0
],
static_cast
<
int64_t
>
((
lod
[
level
]).
back
()));
input
.
set_lod
(
lod
);
input
->
set_lod
(
lod
);
SetupTensor
<
T
>
(
input
,
dims
,
data
);
}
template
<
typename
T
>
void
CheckError
(
paddle
::
framework
::
LoDTensor
&
output1
,
paddle
::
framework
::
LoDTensor
&
output2
)
{
void
CheckError
(
const
paddle
::
framework
::
LoDTensor
&
output1
,
const
paddle
::
framework
::
LoDTensor
&
output2
)
{
// Check lod information
EXPECT_EQ
(
output1
.
lod
(),
output2
.
lod
());
...
...
@@ -91,9 +91,8 @@ void CheckError(paddle::framework::LoDTensor& output1,
template
<
typename
Place
>
void
TestInference
(
const
std
::
string
&
dirname
,
const
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>&
cpu_feeds
,
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>&
cpu_fetchs
,
const
int
repeat
=
1
,
const
bool
is_combined
=
false
)
{
const
std
::
vector
<
paddle
::
framework
::
LoDTensor
*>&
cpu_fetchs
,
const
int
repeat
=
1
,
const
bool
is_combined
=
false
)
{
// 1. Define place, executor, scope
auto
place
=
Place
();
auto
executor
=
paddle
::
framework
::
Executor
(
place
);
...
...
@@ -132,11 +131,9 @@ void TestInference(const std::string& dirname,
// `fluid.io.save_inference_model`.
std
::
string
prog_filename
=
"__model_combined__"
;
std
::
string
param_filename
=
"__params_combined__"
;
inference_program
=
paddle
::
inference
::
Load
(
executor
,
*
scope
,
dirname
+
"/"
+
prog_filename
,
dirname
+
"/"
+
param_filename
);
inference_program
=
paddle
::
inference
::
Load
(
executor
,
*
scope
,
dirname
+
"/"
+
prog_filename
,
dirname
+
"/"
+
param_filename
);
}
else
{
// Parameters are saved in separate files sited in the specified
// `dirname`.
...
...
paddle/fluid/memory/.clang-format
已删除
100644 → 0
浏览文件 @
f132f51e
---
Language: Cpp
BasedOnStyle: Google
Standard: Cpp11
...
paddle/fluid/memory/memory.cc
浏览文件 @
9eaf4458
...
...
@@ -95,7 +95,7 @@ void* Alloc<platform::CUDAPlace>(platform::CUDAPlace place, size_t size) {
int
cur_dev
=
platform
::
GetCurrentDeviceId
();
platform
::
SetDeviceId
(
place
.
device
);
size_t
avail
,
total
;
platform
::
GpuMemoryUsage
(
avail
,
total
);
platform
::
GpuMemoryUsage
(
&
avail
,
&
total
);
LOG
(
WARNING
)
<<
"Cannot allocate "
<<
size
<<
" bytes in GPU "
<<
place
.
device
<<
", available "
<<
avail
<<
" bytes"
;
LOG
(
WARNING
)
<<
"total "
<<
total
;
...
...
paddle/fluid/memory/memory_test.cc
浏览文件 @
9eaf4458
...
...
@@ -13,16 +13,16 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/memory/memory.h"
#include <unordered_map>
#include "gtest/gtest.h"
#include "paddle/fluid/memory/detail/memory_block.h"
#include "paddle/fluid/memory/detail/meta_data.h"
#include "paddle/fluid/platform/cpu_info.h"
#include "paddle/fluid/platform/gpu_info.h"
#include "paddle/fluid/platform/place.h"
#include <gtest/gtest.h>
#include <unordered_map>
inline
bool
is_aligned
(
void
const
*
p
)
{
return
0
==
(
reinterpret_cast
<
uintptr_t
>
(
p
)
&
0x3
);
}
...
...
paddle/fluid/operators/.clang-format
已删除
100644 → 0
浏览文件 @
f132f51e
---
Language: Cpp
BasedOnStyle: Google
Standard: Cpp11
...
paddle/fluid/operators/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -3,8 +3,8 @@ string(REPLACE "_mkldnn" "" GENERAL_OPS "${GENERAL_OPS}")
string
(
REPLACE
".cc"
""
GENERAL_OPS
"
${
GENERAL_OPS
}
"
)
list
(
REMOVE_DUPLICATES GENERAL_OPS
)
set
(
DEPS_OPS
""
)
set
(
pybind_file
${
PADDLE_
SOURCE
_DIR
}
/paddle/fluid/pybind/pybind.h
)
file
(
WRITE
${
pybind_file
}
"// Generated by the paddle/operator/CMakeLists.txt. DO NOT EDIT!
\n\n
"
)
set
(
pybind_file
${
PADDLE_
BINARY
_DIR
}
/paddle/fluid/pybind/pybind.h
)
file
(
WRITE
${
pybind_file
}
"// Generated by the paddle/
fluid/
operator/CMakeLists.txt. DO NOT EDIT!
\n\n
"
)
function
(
op_library TARGET
)
# op_library is a function to create op library. The interface is same as
# cc_library. But it handle split GPU/CPU code and link some common library
...
...
paddle/fluid/operators/conv_cudnn_op.cu.cc
浏览文件 @
9eaf4458
...
...
@@ -128,10 +128,32 @@ class CUDNNConvOpKernel : public framework::OpKernel<T> {
handle
,
cudnn_input_desc
,
cudnn_filter_desc
,
cudnn_conv_desc
,
cudnn_output_desc
,
CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT
,
workspace_size_limit
,
&
algo
));
#if CUDA_VERSION >= 9000 && CUDNN_VERSION_MIN(7, 0, 1)
// Tensor core is supported since the volta GPU and
// is only enabled when input and filter data are float16
if
(
dev_ctx
.
GetComputeCapability
()
>=
70
&&
std
::
type_index
(
typeid
(
T
))
==
std
::
type_index
(
typeid
(
platform
::
float16
)))
{
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnSetConvolutionMathType
(
cudnn_conv_desc
,
CUDNN_TENSOR_OP_MATH
));
// Currently tensor core is only enabled using this algo
algo
=
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM
;
}
else
{
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnSetConvolutionMathType
(
cudnn_conv_desc
,
CUDNN_DEFAULT_MATH
));
}
#endif
// get workspace size able to allocate
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnGetConvolutionForwardWorkspaceSize
(
handle
,
cudnn_input_desc
,
cudnn_filter_desc
,
cudnn_conv_desc
,
cudnn_output_desc
,
algo
,
&
workspace_size_in_bytes
));
// It is possible for float16 on Volta GPU to allocate more memory than
// the limit because the algo is overrided to use tensor core.
PADDLE_ENFORCE_LE
(
workspace_size_in_bytes
,
workspace_size_limit
,
"workspace_size to be allocated exceeds the limit"
);
// Allocate on GPU memory
platform
::
CUDAPlace
gpu
=
boost
::
get
<
platform
::
CUDAPlace
>
(
ctx
.
GetPlace
());
cudnn_workspace
=
paddle
::
memory
::
Alloc
(
gpu
,
workspace_size_in_bytes
);
...
...
paddle/fluid/operators/fc_mkldnn_op.cc
浏览文件 @
9eaf4458
...
...
@@ -27,8 +27,8 @@ template <typename T>
class
MKLDNNMD
{
public:
explicit
MKLDNNMD
(
const
T
*
in
,
const
T
*
w
,
bool
bias
)
:
in
{
paddle
::
framework
::
vectorize2int
(
in
->
dims
())}
,
w
{
paddle
::
framework
::
vectorize2int
(
w
->
dims
())}
{
:
in
(
paddle
::
framework
::
vectorize2int
(
in
->
dims
()))
,
w
(
paddle
::
framework
::
vectorize2int
(
w
->
dims
()))
{
with_bias_
=
bias
;
}
...
...
@@ -78,7 +78,7 @@ class MKLDNNMD {
class
MKLDNNMemory
{
public:
MKLDNNMemory
(
MKLDNNMD
<
Tensor
>*
t
,
const
mkldnn
::
engine
&
e
)
:
md_
{
t
},
engine_
{
e
}
{}
:
md_
(
t
),
engine_
(
e
)
{}
virtual
~
MKLDNNMemory
()
=
default
;
template
<
typename
Output
>
...
...
paddle/fluid/operators/lookup_table_op.cc
浏览文件 @
9eaf4458
...
...
@@ -18,22 +18,6 @@ limitations under the License. */
namespace
paddle
{
namespace
operators
{
static
inline
framework
::
OpKernelType
ExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
{
auto
*
table_var
=
ctx
.
InputVar
(
"W"
);
if
(
table_var
->
IsType
<
LoDTensor
>
())
{
return
framework
::
OpKernelType
(
framework
::
ToDataType
(
table_var
->
Get
<
LoDTensor
>
().
type
()),
ctx
.
device_context
());
}
else
if
(
table_var
->
IsType
<
SelectedRows
>
())
{
return
framework
::
OpKernelType
(
framework
::
ToDataType
(
table_var
->
Get
<
SelectedRows
>
().
value
().
type
()),
ctx
.
device_context
());
}
else
{
PADDLE_THROW
(
"W should be LoDTensor or SelectedRows"
);
}
}
class
LookupTableOp
:
public
framework
::
OperatorWithKernel
{
public:
using
framework
::
OperatorWithKernel
::
OperatorWithKernel
;
...
...
@@ -67,7 +51,8 @@ class LookupTableOp : public framework::OperatorWithKernel {
protected:
framework
::
OpKernelType
GetExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
ExpectedKernelType
(
ctx
);
auto
data_type
=
framework
::
GetDataTypeOfVar
(
ctx
.
InputVar
(
"W"
));
return
framework
::
OpKernelType
(
data_type
,
ctx
.
device_context
());
}
};
...
...
@@ -138,7 +123,8 @@ class LookupTableOpGrad : public framework::OperatorWithKernel {
protected:
framework
::
OpKernelType
GetExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
ExpectedKernelType
(
ctx
);
auto
data_type
=
framework
::
GetDataTypeOfVar
(
ctx
.
InputVar
(
"W"
));
return
framework
::
OpKernelType
(
data_type
,
ctx
.
device_context
());
}
};
...
...
paddle/fluid/operators/lookup_table_op.h
浏览文件 @
9eaf4458
...
...
@@ -30,13 +30,7 @@ using LoDTensor = framework::LoDTensor;
using
SelectedRows
=
framework
::
SelectedRows
;
using
DDim
=
framework
::
DDim
;
static
constexpr
int64_t
kNoPadding
=
-
1
;
inline
size_t
getIndex
(
const
std
::
vector
<
int64_t
>
&
rows
,
int64_t
value
)
{
auto
it
=
std
::
find
(
rows
.
begin
(),
rows
.
end
(),
value
);
PADDLE_ENFORCE
(
it
!=
rows
.
end
(),
"id should be in rows"
);
return
static_cast
<
size_t
>
(
std
::
distance
(
rows
.
begin
(),
it
));
}
constexpr
int64_t
kNoPadding
=
-
1
;
template
<
typename
T
>
class
LookupTableKernel
:
public
framework
::
OpKernel
<
T
>
{
...
...
@@ -55,7 +49,9 @@ class LookupTableKernel : public framework::OpKernel<T> {
auto
*
table_t
=
context
.
Input
<
SelectedRows
>
(
"W"
);
table_dim
=
table_t
->
value
().
dims
();
}
else
{
PADDLE_THROW
(
"table only support LoDTensor and SelectedRows"
);
PADDLE_THROW
(
"The parameter W of a LookupTable "
"must be either LoDTensor or SelectedRows"
);
}
int64_t
*
ids
;
...
...
@@ -107,7 +103,7 @@ class LookupTableKernel : public framework::OpKernel<T> {
memset
(
output
+
i
*
row_width
,
0
,
row_width
*
sizeof
(
T
));
}
else
{
PADDLE_ENFORCE_GE
(
ids
[
i
],
0
);
auto
id_index
=
getIndex
(
table_t
.
rows
(),
ids
[
i
]);
auto
id_index
=
table_t
.
index
(
ids
[
i
]);
memcpy
(
output
+
i
*
row_width
,
table
+
id_index
*
row_width
,
row_width
*
sizeof
(
T
));
}
...
...
@@ -128,7 +124,9 @@ class LookupTableGradKernel : public framework::OpKernel<T> {
auto
*
table_t
=
context
.
Input
<
SelectedRows
>
(
"W"
);
table_dim
=
table_t
->
value
().
dims
();
}
else
{
PADDLE_THROW
(
"table only support LoDTensor and SelectedRows"
);
PADDLE_THROW
(
"The parameter W of a LookupTable "
"must be either LoDTensor or SelectedRows"
);
}
bool
is_sparse
=
context
.
Attr
<
bool
>
(
"is_sparse"
);
...
...
paddle/fluid/operators/math/math_function.cu
浏览文件 @
9eaf4458
...
...
@@ -39,18 +39,33 @@ void gemm<platform::CUDADeviceContext, float16>(
cublasOperation_t
cuTransB
=
(
transB
==
CblasNoTrans
)
?
CUBLAS_OP_N
:
CUBLAS_OP_T
;
const
half
h_alpha
=
static_cast
<
const
half
>
(
alpha
);
const
half
h_beta
=
static_cast
<
const
half
>
(
beta
);
const
half
*
h_A
=
reinterpret_cast
<
const
half
*>
(
A
);
const
half
*
h_B
=
reinterpret_cast
<
const
half
*>
(
B
);
half
*
h_C
=
reinterpret_cast
<
half
*>
(
C
);
float
h_alpha
=
static_cast
<
float
>
(
alpha
);
float
h_beta
=
static_cast
<
float
>
(
beta
);
// TODO(kexinzhao): add processing code for compute capability < 53 case
PADDLE_ENFORCE_GE
(
context
.
GetComputeCapability
(),
53
,
"cublas Hgemm requires GPU compute capability >= 53"
);
PADDLE_ENFORCE
(
platform
::
dynload
::
cublasHgemm
(
context
.
cublas_handle
(),
cuTransB
,
cuTransA
,
N
,
M
,
K
,
&
h_alpha
,
h_B
,
ldb
,
h_A
,
lda
,
&
h_beta
,
h_C
,
N
));
"cublas fp16 gemm requires GPU compute capability >= 53"
);
cublasGemmAlgo_t
algo
=
CUBLAS_GEMM_DFALT
;
#if CUDA_VERSION >= 9000
if
(
context
.
GetComputeCapability
()
>=
70
)
{
PADDLE_ENFORCE
(
platform
::
dynload
::
cublasSetMathMode
(
context
.
cublas_handle
(),
CUBLAS_TENSOR_OP_MATH
));
algo
=
CUBLAS_GEMM_DFALT_TENSOR_OP
;
}
else
{
PADDLE_ENFORCE
(
platform
::
dynload
::
cublasSetMathMode
(
context
.
cublas_handle
(),
CUBLAS_DEFAULT_MATH
));
}
#endif
// cublasHgemm does true FP16 computation which is slow for non-Volta
// GPUs. So use cublasGemmEx instead which does pesudo FP16 computation:
// input/output in fp16, computation in fp32, which can also be accelerated
// using tensor cores in volta GPUs.
PADDLE_ENFORCE
(
platform
::
dynload
::
cublasGemmEx
(
context
.
cublas_handle
(),
cuTransB
,
cuTransA
,
N
,
M
,
K
,
&
h_alpha
,
B
,
CUDA_R_16F
,
ldb
,
A
,
CUDA_R_16F
,
lda
,
&
h_beta
,
C
,
CUDA_R_16F
,
N
,
CUDA_R_32F
,
algo
));
}
template
<
>
...
...
paddle/fluid/operators/math/softmax.cu
浏览文件 @
9eaf4458
...
...
@@ -14,6 +14,8 @@ limitations under the License. */
#define EIGEN_USE_GPU
#include <vector>
#include "paddle/fluid/operators/math/math_function.h"
#include "paddle/fluid/operators/math/softmax.h"
#include "paddle/fluid/operators/math/softmax_impl.h"
...
...
@@ -95,6 +97,7 @@ template class SoftmaxCUDNNFunctor<double>;
template
class
SoftmaxGradCUDNNFunctor
<
float
>;
template
class
SoftmaxGradCUDNNFunctor
<
double
>;
template
class
SoftmaxFunctor
<
platform
::
CUDADeviceContext
,
platform
::
float16
>;
template
class
SoftmaxFunctor
<
platform
::
CUDADeviceContext
,
float
>;
template
class
SoftmaxFunctor
<
platform
::
CUDADeviceContext
,
double
>;
template
class
SoftmaxGradFunctor
<
platform
::
CUDADeviceContext
,
float
>;
...
...
paddle/fluid/operators/math/softmax_impl.h
浏览文件 @
9eaf4458
...
...
@@ -27,7 +27,7 @@ using EigenMatrix = framework::EigenMatrix<T, MajorType, IndexType>;
template
<
typename
T
>
struct
ValueClip
{
HOSTDEVICE
T
operator
()(
const
T
&
x
)
const
{
const
T
kThreshold
=
-
64.
;
const
T
kThreshold
=
static_cast
<
T
>
(
-
64.
)
;
return
x
<
kThreshold
?
kThreshold
:
x
;
}
};
...
...
paddle/fluid/operators/prior_box_op.cc
浏览文件 @
9eaf4458
...
...
@@ -73,7 +73,7 @@ class PriorBoxOp : public framework::OperatorWithKernel {
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
framework
::
OpKernelType
(
framework
::
ToDataType
(
ctx
.
Input
<
framework
::
Tensor
>
(
"Input"
)
->
type
()),
platform
::
CPUPlace
());
ctx
.
device_context
());
}
};
...
...
@@ -171,6 +171,5 @@ namespace ops = paddle::operators;
REGISTER_OPERATOR
(
prior_box
,
ops
::
PriorBoxOp
,
ops
::
PriorBoxOpMaker
,
paddle
::
framework
::
EmptyGradOpMaker
);
REGISTER_OP_CPU_KERNEL
(
prior_box
,
ops
::
PriorBoxOpKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
ops
::
PriorBoxOpKernel
<
paddle
::
platform
::
CPUPlace
,
double
>
);
REGISTER_OP_CPU_KERNEL
(
prior_box
,
ops
::
PriorBoxOpKernel
<
float
>
,
ops
::
PriorBoxOpKernel
<
double
>
);
paddle/fluid/operators/prior_box_op.cu
0 → 100644
浏览文件 @
9eaf4458
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/operators/prior_box_op.h"
namespace
paddle
{
namespace
operators
{
template
<
typename
T
>
__device__
inline
T
clip
(
T
in
)
{
return
min
(
max
(
in
,
0.
),
1.
);
}
template
<
typename
T
>
__global__
void
GenPriorBox
(
T
*
out
,
const
T
*
aspect_ratios
,
const
int
height
,
const
int
width
,
const
int
im_height
,
const
int
im_width
,
const
int
as_num
,
const
T
offset
,
const
T
step_width
,
const
T
step_height
,
const
T
*
min_sizes
,
const
T
*
max_sizes
,
const
int
min_num
,
bool
is_clip
)
{
int
num_priors
=
max_sizes
?
as_num
*
min_num
+
min_num
:
as_num
*
min_num
;
int
box_num
=
height
*
width
*
num_priors
;
for
(
int
i
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
i
<
box_num
;
i
+=
blockDim
.
x
*
gridDim
.
x
)
{
int
h
=
i
/
(
num_priors
*
width
);
int
w
=
(
i
/
num_priors
)
%
width
;
int
p
=
i
%
num_priors
;
int
m
=
max_sizes
?
p
/
(
as_num
+
1
)
:
p
/
as_num
;
T
cx
=
(
w
+
offset
)
*
step_width
;
T
cy
=
(
h
+
offset
)
*
step_height
;
T
bw
,
bh
;
T
min_size
=
min_sizes
[
m
];
if
(
max_sizes
)
{
int
s
=
p
%
(
as_num
+
1
);
if
(
s
<
as_num
)
{
T
ar
=
aspect_ratios
[
s
];
bw
=
min_size
*
sqrt
(
ar
)
/
2.
;
bh
=
min_size
/
sqrt
(
ar
)
/
2.
;
}
else
{
T
max_size
=
max_sizes
[
m
];
bw
=
sqrt
(
min_size
*
max_size
)
/
2.
;
bh
=
bw
;
}
}
else
{
int
s
=
p
%
as_num
;
T
ar
=
aspect_ratios
[
s
];
bw
=
min_size
*
sqrt
(
ar
)
/
2.
;
bh
=
min_size
/
sqrt
(
ar
)
/
2.
;
}
T
xmin
=
(
cx
-
bw
)
/
im_width
;
T
ymin
=
(
cy
-
bh
)
/
im_height
;
T
xmax
=
(
cx
+
bw
)
/
im_width
;
T
ymax
=
(
cy
+
bh
)
/
im_height
;
out
[
i
*
4
]
=
is_clip
?
clip
<
T
>
(
xmin
)
:
xmin
;
out
[
i
*
4
+
1
]
=
is_clip
?
clip
<
T
>
(
ymin
)
:
ymin
;
out
[
i
*
4
+
2
]
=
is_clip
?
clip
<
T
>
(
xmax
)
:
xmax
;
out
[
i
*
4
+
3
]
=
is_clip
?
clip
<
T
>
(
ymax
)
:
ymax
;
}
}
template
<
typename
T
>
__global__
void
SetVariance
(
T
*
out
,
const
T
*
var
,
const
int
vnum
,
const
int
num
)
{
for
(
int
i
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
i
<
num
;
i
+=
blockDim
.
x
*
gridDim
.
x
)
{
out
[
i
]
=
var
[
i
%
vnum
];
}
}
template
<
typename
T
>
class
PriorBoxOpCUDAKernel
:
public
framework
::
OpKernel
<
T
>
{
public:
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
auto
*
input
=
ctx
.
Input
<
paddle
::
framework
::
Tensor
>
(
"Input"
);
auto
*
image
=
ctx
.
Input
<
paddle
::
framework
::
Tensor
>
(
"Image"
);
auto
*
boxes
=
ctx
.
Output
<
paddle
::
framework
::
Tensor
>
(
"Boxes"
);
auto
*
vars
=
ctx
.
Output
<
paddle
::
framework
::
Tensor
>
(
"Variances"
);
auto
min_sizes
=
ctx
.
Attr
<
std
::
vector
<
float
>>
(
"min_sizes"
);
auto
max_sizes
=
ctx
.
Attr
<
std
::
vector
<
float
>>
(
"max_sizes"
);
auto
input_aspect_ratio
=
ctx
.
Attr
<
std
::
vector
<
float
>>
(
"aspect_ratios"
);
auto
variances
=
ctx
.
Attr
<
std
::
vector
<
float
>>
(
"variances"
);
auto
flip
=
ctx
.
Attr
<
bool
>
(
"flip"
);
auto
clip
=
ctx
.
Attr
<
bool
>
(
"clip"
);
std
::
vector
<
float
>
aspect_ratios
;
ExpandAspectRatios
(
input_aspect_ratio
,
flip
,
aspect_ratios
);
T
step_w
=
static_cast
<
T
>
(
ctx
.
Attr
<
float
>
(
"step_w"
));
T
step_h
=
static_cast
<
T
>
(
ctx
.
Attr
<
float
>
(
"step_h"
));
T
offset
=
static_cast
<
T
>
(
ctx
.
Attr
<
float
>
(
"offset"
));
auto
im_width
=
image
->
dims
()[
3
];
auto
im_height
=
image
->
dims
()[
2
];
auto
width
=
input
->
dims
()[
3
];
auto
height
=
input
->
dims
()[
2
];
T
step_width
,
step_height
;
if
(
step_w
==
0
||
step_h
==
0
)
{
step_width
=
static_cast
<
T
>
(
im_width
)
/
width
;
step_height
=
static_cast
<
T
>
(
im_height
)
/
height
;
}
else
{
step_width
=
step_w
;
step_height
=
step_h
;
}
int
num_priors
=
aspect_ratios
.
size
()
*
min_sizes
.
size
();
if
(
max_sizes
.
size
()
>
0
)
{
num_priors
+=
max_sizes
.
size
();
}
int
min_num
=
static_cast
<
int
>
(
min_sizes
.
size
());
int
box_num
=
width
*
height
*
num_priors
;
int
block
=
512
;
int
grid
=
(
box_num
+
block
-
1
)
/
block
;
auto
stream
=
ctx
.
template
device_context
<
platform
::
CUDADeviceContext
>().
stream
();
boxes
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
vars
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
framework
::
Tensor
r
;
framework
::
TensorFromVector
(
aspect_ratios
,
ctx
.
device_context
(),
&
r
);
framework
::
Tensor
min
;
framework
::
TensorFromVector
(
min_sizes
,
ctx
.
device_context
(),
&
min
);
T
*
max_data
=
nullptr
;
framework
::
Tensor
max
;
if
(
max_sizes
.
size
()
>
0
)
{
framework
::
TensorFromVector
(
max_sizes
,
ctx
.
device_context
(),
&
max
);
max_data
=
max
.
data
<
T
>
();
}
GenPriorBox
<
T
><<<
grid
,
block
,
0
,
stream
>>>
(
boxes
->
data
<
T
>
(),
r
.
data
<
T
>
(),
height
,
width
,
im_height
,
im_width
,
aspect_ratios
.
size
(),
offset
,
step_width
,
step_height
,
min
.
data
<
T
>
(),
max_data
,
min_num
,
clip
);
framework
::
Tensor
v
;
framework
::
TensorFromVector
(
variances
,
ctx
.
device_context
(),
&
v
);
grid
=
(
box_num
*
4
+
block
-
1
)
/
block
;
SetVariance
<
T
><<<
grid
,
block
,
0
,
stream
>>>
(
vars
->
data
<
T
>
(),
v
.
data
<
T
>
(),
variances
.
size
(),
box_num
*
4
);
}
};
// namespace operators
}
// namespace operators
}
// namespace paddle
namespace
ops
=
paddle
::
operators
;
REGISTER_OP_CUDA_KERNEL
(
prior_box
,
ops
::
PriorBoxOpCUDAKernel
<
float
>
,
ops
::
PriorBoxOpCUDAKernel
<
double
>
);
paddle/fluid/operators/prior_box_op.h
浏览文件 @
9eaf4458
...
...
@@ -51,7 +51,7 @@ struct ClipFunctor {
}
};
template
<
typename
Place
,
typename
T
>
template
<
typename
T
>
class
PriorBoxOpKernel
:
public
framework
::
OpKernel
<
T
>
{
public:
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
...
...
@@ -106,49 +106,24 @@ class PriorBoxOpKernel : public framework::OpKernel<T> {
int
idx
=
0
;
for
(
size_t
s
=
0
;
s
<
min_sizes
.
size
();
++
s
)
{
auto
min_size
=
min_sizes
[
s
];
// first prior: aspect_ratio = 1, size = min_size
box_width
=
box_height
=
min_size
/
2.
;
// xmin
e_boxes
(
h
,
w
,
idx
,
0
)
=
(
center_x
-
box_width
)
/
img_width
;
// ymin
e_boxes
(
h
,
w
,
idx
,
1
)
=
(
center_y
-
box_height
)
/
img_height
;
// xmax
e_boxes
(
h
,
w
,
idx
,
2
)
=
(
center_x
+
box_width
)
/
img_width
;
// ymax
e_boxes
(
h
,
w
,
idx
,
3
)
=
(
center_y
+
box_height
)
/
img_height
;
idx
++
;
if
(
max_sizes
.
size
()
>
0
)
{
auto
max_size
=
max_sizes
[
s
];
// second prior: aspect_ratio = 1,
// size = sqrt(min_size * max_size)
box_width
=
box_height
=
sqrt
(
min_size
*
max_size
)
/
2.
;
// xmin
// priors with different aspect ratios
for
(
size_t
r
=
0
;
r
<
aspect_ratios
.
size
();
++
r
)
{
float
ar
=
aspect_ratios
[
r
];
box_width
=
min_size
*
sqrt
(
ar
)
/
2.
;
box_height
=
min_size
/
sqrt
(
ar
)
/
2.
;
e_boxes
(
h
,
w
,
idx
,
0
)
=
(
center_x
-
box_width
)
/
img_width
;
// ymin
e_boxes
(
h
,
w
,
idx
,
1
)
=
(
center_y
-
box_height
)
/
img_height
;
// xmax
e_boxes
(
h
,
w
,
idx
,
2
)
=
(
center_x
+
box_width
)
/
img_width
;
// ymax
e_boxes
(
h
,
w
,
idx
,
3
)
=
(
center_y
+
box_height
)
/
img_height
;
idx
++
;
}
// rest of priors
for
(
size_t
r
=
0
;
r
<
aspect_ratios
.
size
();
++
r
)
{
float
ar
=
aspect_ratios
[
r
];
if
(
fabs
(
ar
-
1.
)
<
1e-6
)
{
continue
;
}
box_width
=
min_size
*
sqrt
(
ar
)
/
2.
;
box_height
=
min_size
/
sqrt
(
ar
)
/
2.
;
// xmin
if
(
max_sizes
.
size
()
>
0
)
{
auto
max_size
=
max_sizes
[
s
];
// square prior with size sqrt(minSize * maxSize)
box_width
=
box_height
=
sqrt
(
min_size
*
max_size
)
/
2.
;
e_boxes
(
h
,
w
,
idx
,
0
)
=
(
center_x
-
box_width
)
/
img_width
;
// ymin
e_boxes
(
h
,
w
,
idx
,
1
)
=
(
center_y
-
box_height
)
/
img_height
;
// xmax
e_boxes
(
h
,
w
,
idx
,
2
)
=
(
center_x
+
box_width
)
/
img_width
;
// ymax
e_boxes
(
h
,
w
,
idx
,
3
)
=
(
center_y
+
box_height
)
/
img_height
;
idx
++
;
}
...
...
paddle/fluid/operators/reader/create_batch_reader_op.cc
浏览文件 @
9eaf4458
...
...
@@ -39,10 +39,13 @@ class CreateBatchReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
*
out
=
scope
.
FindVar
(
Output
(
"Out"
))
->
template
GetMutable
<
framework
::
ReaderHolder
>();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
out
->
Reset
(
new
BatchReader
(
underlying_reader
.
Get
(),
Attr
<
int
>
(
"batch_size"
)));
}
...
...
paddle/fluid/operators/reader/create_double_buffer_reader_op.cc
浏览文件 @
9eaf4458
...
...
@@ -99,10 +99,13 @@ class CreateDoubleBufferReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
*
out
=
scope
.
FindVar
(
Output
(
"Out"
))
->
template
GetMutable
<
framework
::
ReaderHolder
>();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
place_str
=
Attr
<
std
::
string
>
(
"place"
);
platform
::
Place
place
;
...
...
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
浏览文件 @
9eaf4458
...
...
@@ -62,12 +62,15 @@ class CreateMultiPassReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
auto
*
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)))
.
GetMutable
<
framework
::
ReaderHolder
>
();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
&
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)));
int
pass_num
=
Attr
<
int
>
(
"pass_num"
);
out
.
GetMutable
<
framework
::
ReaderHolder
>
()
->
Reset
(
new
MultiPassReader
(
underlying_reader
.
Get
(),
pass_num
));
out
->
Reset
(
new
MultiPassReader
(
underlying_reader
.
Get
(),
pass_num
));
}
};
...
...
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
浏览文件 @
9eaf4458
...
...
@@ -80,10 +80,14 @@ class CreateShuffleReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
auto
*
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)))
.
GetMutable
<
framework
::
ReaderHolder
>
();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
&
var
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)));
var
.
GetMutable
<
framework
::
ReaderHolder
>
()
->
Reset
(
out
->
Reset
(
new
ShuffleReader
(
underlying_reader
.
Get
(),
static_cast
<
size_t
>
(
Attr
<
int
>
(
"buffer_size"
))));
}
...
...
paddle/fluid/operators/sgd_op.cc
浏览文件 @
9eaf4458
...
...
@@ -43,9 +43,8 @@ class SGDOp : public framework::OperatorWithKernel {
protected:
framework
::
OpKernelType
GetExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
framework
::
OpKernelType
(
framework
::
ToDataType
(
ctx
.
Input
<
framework
::
LoDTensor
>
(
"Param"
)
->
type
()),
ctx
.
GetPlace
());
auto
data_type
=
framework
::
GetDataTypeOfVar
(
ctx
.
InputVar
(
"Param"
));
return
framework
::
OpKernelType
(
data_type
,
ctx
.
device_context
());
}
};
...
...
@@ -53,10 +52,12 @@ class SGDOpMaker : public framework::OpProtoAndCheckerMaker {
public:
SGDOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"Param"
,
"(Tensor) Input parameter"
);
AddInput
(
"Param"
,
"(Tensor
or SelectedRows
) Input parameter"
);
AddInput
(
"LearningRate"
,
"(Tensor) Learning rate of SGD"
);
AddInput
(
"Grad"
,
"(Tensor) Input gradient"
);
AddOutput
(
"ParamOut"
,
"(Tensor) Output parameter"
);
AddInput
(
"Grad"
,
"(Tensor or SelectedRows) Input gradient"
);
AddOutput
(
"ParamOut"
,
"(Tensor or SelectedRows, same with Param) "
"Output parameter, should share the same memory with Param"
);
AddComment
(
R"DOC(
SGD operator
...
...
paddle/fluid/operators/sgd_op.h
浏览文件 @
9eaf4458
...
...
@@ -23,60 +23,97 @@ namespace operators {
template
<
typename
T
>
class
SGDOpKernel
:
public
framework
::
OpKernel
<
T
>
{
public:
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
auto
*
param
=
ctx
.
Input
<
framework
::
Tensor
>
(
"Param"
);
auto
*
param_out
=
ctx
.
Output
<
framework
::
Tensor
>
(
"ParamOut"
);
auto
*
learning_rate
=
ctx
.
Input
<
framework
::
Tensor
>
(
"LearningRate"
);
auto
*
grad_var
=
ctx
.
InputVar
(
"Grad"
);
// Actually, all tensors are LoDTensor except SelectedRows.
if
(
grad_var
->
IsType
<
framework
::
LoDTensor
>
())
{
param_out
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
auto
*
grad
=
ctx
.
Input
<
framework
::
Tensor
>
(
"Grad"
);
auto
p
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
param
);
auto
g
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
grad
);
auto
o
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
param_out
);
auto
*
lr
=
learning_rate
->
data
<
T
>
();
o
=
p
-
lr
[
0
]
*
g
;
}
else
if
(
grad_var
->
IsType
<
framework
::
SelectedRows
>
())
{
// TODO(qijun): In Sparse SGD operator, in-place update is enforced.
// This manual optimization brings difficulty to track data dependency.
// It's better to find a more elegant solution.
PADDLE_ENFORCE_EQ
(
param
,
param_out
);
auto
*
grad
=
ctx
.
Input
<
framework
::
SelectedRows
>
(
"Grad"
);
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
const
auto
*
learning_rate
=
ctx
.
Input
<
framework
::
Tensor
>
(
"LearningRate"
);
const
auto
*
param_var
=
ctx
.
InputVar
(
"Param"
);
const
auto
*
grad_var
=
ctx
.
InputVar
(
"Grad"
);
if
(
param_var
->
IsType
<
framework
::
LoDTensor
>
())
{
const
auto
*
param
=
ctx
.
Input
<
framework
::
Tensor
>
(
"Param"
);
auto
*
param_out
=
ctx
.
Output
<
framework
::
Tensor
>
(
"ParamOut"
);
// Actually, all tensors are LoDTensor except SelectedRows.
if
(
grad_var
->
IsType
<
framework
::
LoDTensor
>
())
{
param_out
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
const
auto
*
grad
=
ctx
.
Input
<
framework
::
Tensor
>
(
"Grad"
);
auto
p
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
param
);
auto
g
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
grad
);
auto
o
=
framework
::
EigenVector
<
T
>::
Flatten
(
*
param_out
);
auto
*
lr
=
learning_rate
->
data
<
T
>
();
o
=
p
-
lr
[
0
]
*
g
;
}
else
if
(
grad_var
->
IsType
<
framework
::
SelectedRows
>
())
{
// TODO(qijun): In Sparse SGD operator, in-place update is enforced.
// This manual optimization brings difficulty to track data dependency.
// It's better to find a more elegant solution.
PADDLE_ENFORCE_EQ
(
param
,
param_out
);
const
auto
*
grad
=
ctx
.
Input
<
framework
::
SelectedRows
>
(
"Grad"
);
// for distributed training, a sparse var may be empty,
// just skip updating.
if
(
grad
->
rows
().
size
()
==
0
)
{
return
;
}
auto
grad_height
=
grad
->
height
();
auto
out_dims
=
param_out
->
dims
();
PADDLE_ENFORCE_EQ
(
grad_height
,
out_dims
[
0
]);
auto
&
grad_value
=
grad
->
value
();
auto
&
grad_rows
=
grad
->
rows
();
size_t
grad_row_numel
=
grad_value
.
numel
()
/
grad_rows
.
size
();
PADDLE_ENFORCE_EQ
(
grad_row_numel
,
param_out
->
numel
()
/
grad_height
);
auto
*
grad_data
=
grad_value
.
data
<
T
>
();
auto
*
out_data
=
param_out
->
data
<
T
>
();
auto
*
lr
=
learning_rate
->
data
<
T
>
();
for
(
size_t
i
=
0
;
i
<
grad_rows
.
size
();
i
++
)
{
PADDLE_ENFORCE
(
grad_rows
[
i
]
<
grad_height
,
"Input rows index should less than height"
);
for
(
int64_t
j
=
0
;
j
<
grad_row_numel
;
j
++
)
{
out_data
[
grad_rows
[
i
]
*
grad_row_numel
+
j
]
-=
lr
[
0
]
*
grad_data
[
i
*
grad_row_numel
+
j
];
}
}
}
else
{
PADDLE_THROW
(
"Unsupported Variable Type of Grad"
);
}
}
else
if
(
param_var
->
IsType
<
framework
::
SelectedRows
>
())
{
PADDLE_ENFORCE
(
grad_var
->
IsType
<
framework
::
SelectedRows
>
(),
"when param "
"is SelectedRows, gradient should also be SelectedRows"
);
const
auto
&
param
=
param_var
->
Get
<
framework
::
SelectedRows
>
();
auto
*
param_out
=
ctx
.
Output
<
framework
::
SelectedRows
>
(
"ParamOut"
);
const
auto
&
grad
=
grad_var
->
Get
<
framework
::
SelectedRows
>
();
// for distributed training, a sparse var may be empty,
// just skip updating.
if
(
grad
->
rows
().
size
()
==
0
)
{
if
(
grad
.
rows
().
size
()
==
0
)
{
return
;
}
auto
in_height
=
grad
->
height
();
auto
out_dims
=
param_out
->
dims
();
PADDLE_ENFORCE_EQ
(
in_height
,
out_dims
[
0
]);
auto
&
in_value
=
grad
->
value
();
auto
&
in_rows
=
grad
->
rows
();
size_t
param_row_width
=
param
.
value
().
numel
()
/
param
.
rows
().
size
();
size_t
grad_row_width
=
grad
.
value
().
numel
()
/
grad
.
rows
().
size
();
PADDLE_ENFORCE_EQ
(
param_row_width
,
grad_row_width
,
"param_row should have the same size with grad_row"
);
int64_t
in_row_numel
=
in_value
.
numel
()
/
in_rows
.
size
();
PADDLE_ENFORCE_EQ
(
in_row_numel
,
param_out
->
numel
()
/
in_height
);
auto
*
in_data
=
in_value
.
data
<
T
>
();
auto
*
out_data
=
param_out
->
data
<
T
>
();
auto
*
lr
=
learning_rate
->
data
<
T
>
();
for
(
size_t
i
=
0
;
i
<
in_rows
.
size
();
i
++
)
{
PADDLE_ENFORCE
(
in_rows
[
i
]
<
in_height
,
const
auto
*
lr
=
learning_rate
->
data
<
T
>
();
const
auto
*
grad_data
=
grad
.
value
().
data
<
T
>
();
auto
*
out_data
=
param_out
->
mutable_value
()
->
data
<
T
>
();
for
(
size_t
i
=
0
;
i
<
grad
.
rows
().
size
();
i
++
)
{
PADDLE_ENFORCE
(
grad
.
rows
()[
i
]
<
grad
.
height
(),
"Input rows index should less than height"
);
for
(
int64_t
j
=
0
;
j
<
in_row_numel
;
j
++
)
{
out_data
[
in_rows
[
i
]
*
in_row_numel
+
j
]
-=
lr
[
0
]
*
in_data
[
i
*
in_row_numel
+
j
];
int64_t
id_index
=
param
.
index
(
grad
.
rows
()[
i
]);
for
(
int64_t
j
=
0
;
j
<
grad_row_width
;
j
++
)
{
out_data
[
id_index
*
grad_row_width
+
j
]
-=
lr
[
0
]
*
grad_data
[
i
*
grad_row_width
+
j
];
}
}
}
else
{
PADDLE_THROW
(
"Unsupported Variable Type of
Grad
"
);
PADDLE_THROW
(
"Unsupported Variable Type of
Parameter
"
);
}
}
};
...
...
paddle/fluid/operators/softmax_op.cc
浏览文件 @
9eaf4458
...
...
@@ -13,6 +13,9 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/operators/softmax_op.h"
#include <string>
#ifdef PADDLE_WITH_CUDA
#include "paddle/fluid/platform/cudnn_helper.h"
#endif
...
...
@@ -20,6 +23,7 @@ limitations under the License. */
#ifdef PADDLE_WITH_MKLDNN
#include "paddle/fluid/platform/mkldnn_helper.h"
#endif
namespace
paddle
{
namespace
operators
{
...
...
@@ -60,8 +64,8 @@ class SoftmaxOp : public framework::OperatorWithKernel {
auto
input_data_type
=
framework
::
ToDataType
(
ctx
.
Input
<
Tensor
>
(
"X"
)
->
type
());
if
(
input_data_type
==
framework
::
proto
::
VarType
::
FP16
)
{
PADDLE_ENFORCE
_EQ
(
library_
,
framework
::
LibraryType
::
kCUDNN
,
"float16 can only be used when CUDNN is used
"
);
PADDLE_ENFORCE
(
platform
::
is_gpu_place
(
ctx
.
GetPlace
())
,
"float16 can only be used on GPU place
"
);
}
std
::
string
data_format
=
ctx
.
Attr
<
std
::
string
>
(
"data_format"
);
...
...
@@ -70,6 +74,7 @@ class SoftmaxOp : public framework::OperatorWithKernel {
library_
);
}
};
class
SoftmaxOpMaker
:
public
framework
::
OpProtoAndCheckerMaker
{
public:
SoftmaxOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
...
...
paddle/fluid/operators/softmax_op.cu.cc
浏览文件 @
9eaf4458
...
...
@@ -13,11 +13,12 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/operators/softmax_op.h"
#include "paddle/fluid/platform/float16.h"
namespace
ops
=
paddle
::
operators
;
REGISTER_OP_CUDA_KERNEL
(
softmax
,
ops
::
SoftmaxKernel
<
paddle
::
platform
::
CUDADeviceContext
,
float
>
);
namespace
plat
=
paddle
::
platform
;
REGISTER_OP_CUDA_KERNEL
(
softmax_grad
,
ops
::
SoftmaxGradKernel
<
paddle
::
platform
::
CUDADeviceContext
,
float
>
);
softmax
,
ops
::
SoftmaxKernel
<
plat
::
CUDADeviceContext
,
float
>
,
ops
::
SoftmaxKernel
<
plat
::
CUDADeviceContext
,
plat
::
float16
>
);
REGISTER_OP_CUDA_KERNEL
(
softmax_grad
,
ops
::
SoftmaxGradKernel
<
plat
::
CUDADeviceContext
,
float
>
);
paddle/fluid/platform/.clang-format
已删除
100644 → 0
浏览文件 @
f132f51e
---
Language: Cpp
BasedOnStyle: Google
Standard: Cpp11
...
paddle/fluid/platform/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -6,8 +6,8 @@ add_custom_target(profiler_py_proto_init ALL COMMAND ${CMAKE_COMMAND} -E touch _
add_dependencies
(
profiler_py_proto profiler_py_proto_init
)
add_custom_command
(
TARGET profiler_py_proto POST_BUILD
COMMAND
${
CMAKE_COMMAND
}
-E make_directory
${
PADDLE_
SOURCE
_DIR
}
/python/paddle/fluid/proto/profiler
COMMAND cp *.py
${
PADDLE_
SOURCE
_DIR
}
/python/paddle/fluid/proto/profiler
COMMAND
${
CMAKE_COMMAND
}
-E make_directory
${
PADDLE_
BINARY
_DIR
}
/python/paddle/fluid/proto/profiler
COMMAND cp *.py
${
PADDLE_
BINARY
_DIR
}
/python/paddle/fluid/proto/profiler
COMMENT
"Copy generated python proto into directory paddle/fluid/proto/profiler."
WORKING_DIRECTORY
${
CMAKE_CURRENT_BINARY_DIR
}
)
...
...
paddle/fluid/platform/cpu_info_test.cc
浏览文件 @
9eaf4458
...
...
@@ -12,7 +12,6 @@
// See the License for the specific language governing permissions and
// limitations under the License.
#include "paddle/fluid/platform/cpu_info.h"
#include "paddle/fluid/string/printf.h"
#include <ostream>
#include <sstream>
...
...
@@ -20,6 +19,7 @@
#include "gflags/gflags.h"
#include "glog/logging.h"
#include "gtest/gtest.h"
#include "paddle/fluid/string/printf.h"
DECLARE_double
(
fraction_of_cpu_memory_to_use
);
...
...
paddle/fluid/platform/cudnn_helper.h
浏览文件 @
9eaf4458
...
...
@@ -257,9 +257,11 @@ class ScopedConvolutionDescriptor {
}
#endif
cudnnDataType_t
compute_type
=
(
type
==
CUDNN_DATA_DOUBLE
)
?
CUDNN_DATA_DOUBLE
:
CUDNN_DATA_FLOAT
;
PADDLE_ENFORCE
(
dynload
::
cudnnSetConvolutionNdDescriptor
(
desc_
,
pads
.
size
(),
pads
.
data
(),
strides
.
data
(),
dilations
.
data
(),
CUDNN_CROSS_CORRELATION
,
type
));
CUDNN_CROSS_CORRELATION
,
compute_
type
));
return
desc_
;
}
...
...
paddle/fluid/platform/dynload/cublas.cc
浏览文件 @
9eaf4458
...
...
@@ -24,6 +24,10 @@ void *cublas_dso_handle = nullptr;
CUBLAS_BLAS_ROUTINE_EACH
(
DEFINE_WRAP
);
#ifdef CUBLAS_BLAS_ROUTINE_EACH_R2
CUBLAS_BLAS_ROUTINE_EACH_R2
(
DEFINE_WRAP
);
#endif
}
// namespace dynload
}
// namespace platform
}
// namespace paddle
paddle/fluid/platform/dynload/cublas.h
浏览文件 @
9eaf4458
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <cublas_v2.h>
#include <cuda.h>
#include <dlfcn.h>
#include <mutex>
#include <mutex>
// NOLINT
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
namespace
paddle
{
...
...
@@ -34,18 +35,18 @@ extern void *cublas_dso_handle;
* note: default dynamic linked libs
*/
#ifdef PADDLE_USE_DSO
#define DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
inline cublasStatus_t operator()(Args... args) { \
typedef cublasStatus_t (*cublasFunc)(Args...); \
std::call_once(cublas_dso_flag, \
paddle::platform::dynload::GetCublasDsoHandle,
\
&cublas_dso_handle);
\
void *p_##__name = dlsym(cublas_dso_handle, #__name); \
return reinterpret_cast<cublasFunc>(p_##__name)(args...); \
} \
}; \
#define DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP(__name)
\
struct DynLoad__##__name {
\
template <typename... Args>
\
inline cublasStatus_t operator()(Args... args) {
\
typedef cublasStatus_t (*cublasFunc)(Args...);
\
std::call_once(cublas_dso_flag,
[]() {
\
cublas_dso_handle = paddle::platform::dynload::GetCublasDsoHandle();
\
});
\
void *p_##__name = dlsym(cublas_dso_handle, #__name);
\
return reinterpret_cast<cublasFunc>(p_##__name)(args...);
\
}
\
};
\
extern DynLoad__##__name __name
#else
#define DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP(__name) \
...
...
@@ -70,6 +71,7 @@ extern void *cublas_dso_handle;
__macro(cublasDgemm_v2); \
__macro(cublasHgemm); \
__macro(cublasSgemmEx); \
__macro(cublasGemmEx); \
__macro(cublasSgeam_v2); \
__macro(cublasDgeam_v2); \
__macro(cublasCreate_v2); \
...
...
@@ -89,9 +91,15 @@ extern void *cublas_dso_handle;
__macro(cublasSgetrfBatched); \
__macro(cublasSgetriBatched); \
__macro(cublasDgetrfBatched); \
__macro(cublasDgetriBatched)
__macro(cublasDgetriBatched)
;
CUBLAS_BLAS_ROUTINE_EACH
(
DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP
);
CUBLAS_BLAS_ROUTINE_EACH
(
DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP
)
// APIs available after CUDA 9.0
#if CUDA_VERSION >= 9000
#define CUBLAS_BLAS_ROUTINE_EACH_R2(__macro) __macro(cublasSetMathMode);
CUBLAS_BLAS_ROUTINE_EACH_R2
(
DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP
)
#endif
#undef DECLARE_DYNAMIC_LOAD_CUBLAS_WRAP
}
// namespace dynload
...
...
paddle/fluid/platform/dynload/cudnn.cc
浏览文件 @
9eaf4458
...
...
@@ -44,7 +44,8 @@ CUDNN_DNN_ROUTINE_EACH_R7(DEFINE_WRAP);
#ifdef PADDLE_USE_DSO
bool
HasCUDNN
()
{
std
::
call_once
(
cudnn_dso_flag
,
GetCUDNNDsoHandle
,
&
cudnn_dso_handle
);
std
::
call_once
(
cudnn_dso_flag
,
[]()
{
cudnn_dso_handle
=
GetCUDNNDsoHandle
();
});
return
cudnn_dso_handle
!=
nullptr
;
}
...
...
paddle/fluid/platform/dynload/cudnn.h
浏览文件 @
9eaf4458
...
...
@@ -16,7 +16,7 @@ limitations under the License. */
#include <cudnn.h>
#include <dlfcn.h>
#include <mutex>
#include <mutex>
// NOLINT
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
namespace
paddle
{
...
...
@@ -30,19 +30,19 @@ extern bool HasCUDNN();
#ifdef PADDLE_USE_DSO
extern
void
EnforceCUDNNLoaded
(
const
char
*
fn_name
);
#define DECLARE_DYNAMIC_LOAD_CUDNN_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
auto operator()(Args... args) -> decltype(__name(args...)) { \
using cudnn_func = decltype(__name(args...)) (*)(Args...); \
std::call_once(cudnn_dso_flag, \
paddle::platform::dynload::GetCUDNNDsoHandle,
\
&cudnn_dso_handle);
\
EnforceCUDNNLoaded(#__name); \
void* p_##__name = dlsym(cudnn_dso_handle, #__name); \
return reinterpret_cast<cudnn_func>(p_##__name)(args...); \
} \
}; \
#define DECLARE_DYNAMIC_LOAD_CUDNN_WRAP(__name)
\
struct DynLoad__##__name {
\
template <typename... Args>
\
auto operator()(Args... args) -> decltype(__name(args...)) {
\
using cudnn_func = decltype(__name(args...)) (*)(Args...);
\
std::call_once(cudnn_dso_flag,
[]() {
\
cudnn_dso_handle = paddle::platform::dynload::GetCUDNNDsoHandle();
\
});
\
EnforceCUDNNLoaded(#__name);
\
void* p_##__name = dlsym(cudnn_dso_handle, #__name);
\
return reinterpret_cast<cudnn_func>(p_##__name)(args...);
\
}
\
};
\
extern struct DynLoad__##__name __name
#else
...
...
@@ -140,7 +140,8 @@ CUDNN_DNN_ROUTINE_EACH_R5(DECLARE_DYNAMIC_LOAD_CUDNN_WRAP)
#if CUDNN_VERSION >= 7001
#define CUDNN_DNN_ROUTINE_EACH_R7(__macro) \
__macro(cudnnSetConvolutionGroupCount);
__macro(cudnnSetConvolutionGroupCount); \
__macro(cudnnSetConvolutionMathType);
CUDNN_DNN_ROUTINE_EACH_R7
(
DECLARE_DYNAMIC_LOAD_CUDNN_WRAP
)
#endif
...
...
paddle/fluid/platform/dynload/cupti.h
浏览文件 @
9eaf4458
...
...
@@ -11,14 +11,15 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#ifdef PADDLE_WITH_CUPTI
#include <cuda.h>
#include <cupti.h>
#include <dlfcn.h>
#include <mutex>
#include <mutex> // NOLINT
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
namespace
paddle
{
...
...
@@ -36,18 +37,18 @@ extern void *cupti_dso_handle;
* note: default dynamic linked libs
*/
#ifdef PADDLE_USE_DSO
#define DECLARE_DYNAMIC_LOAD_CUPTI_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
inline CUptiResult CUPTIAPI operator()(Args... args) { \
typedef CUptiResult CUPTIAPI (*cuptiFunc)(Args...); \
std::call_once(cupti_dso_flag, \
paddle::platform::dynload::GetCUPTIDsoHandle,
\
&cupti_dso_handle);
\
void *p_##__name = dlsym(cupti_dso_handle, #__name); \
return reinterpret_cast<cuptiFunc>(p_##__name)(args...); \
} \
}; \
#define DECLARE_DYNAMIC_LOAD_CUPTI_WRAP(__name)
\
struct DynLoad__##__name {
\
template <typename... Args>
\
inline CUptiResult CUPTIAPI operator()(Args... args) {
\
typedef CUptiResult CUPTIAPI (*cuptiFunc)(Args...);
\
std::call_once(cupti_dso_flag,
[]() {
\
cupti_dso_handle = paddle::platform::dynload::GetCUPTIDsoHandle();
\
});
\
void *p_##__name = dlsym(cupti_dso_handle, #__name);
\
return reinterpret_cast<cuptiFunc>(p_##__name)(args...);
\
}
\
};
\
extern DynLoad__##__name __name
#else
#define DECLARE_DYNAMIC_LOAD_CUPTI_WRAP(__name) \
...
...
paddle/fluid/platform/dynload/curand.h
浏览文件 @
9eaf4458
...
...
@@ -11,12 +11,13 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <curand.h>
#include <dlfcn.h>
#include <mutex>
#include <mutex> // NOLINT
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
namespace
paddle
{
...
...
@@ -25,18 +26,18 @@ namespace dynload {
extern
std
::
once_flag
curand_dso_flag
;
extern
void
*
curand_dso_handle
;
#ifdef PADDLE_USE_DSO
#define DECLARE_DYNAMIC_LOAD_CURAND_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
curandStatus_t operator()(Args... args) { \
typedef curandStatus_t (*curandFunc)(Args...); \
std::call_once(curand_dso_flag, \
paddle::platform::dynload::GetCurandDsoHandle,
\
&curand_dso_handle);
\
void *p_##__name = dlsym(curand_dso_handle, #__name); \
return reinterpret_cast<curandFunc>(p_##__name)(args...); \
} \
}; \
#define DECLARE_DYNAMIC_LOAD_CURAND_WRAP(__name)
\
struct DynLoad__##__name {
\
template <typename... Args>
\
curandStatus_t operator()(Args... args) {
\
typedef curandStatus_t (*curandFunc)(Args...);
\
std::call_once(curand_dso_flag,
[]() {
\
curand_dso_handle = paddle::platform::dynload::GetCurandDsoHandle();
\
});
\
void *p_##__name = dlsym(curand_dso_handle, #__name);
\
return reinterpret_cast<curandFunc>(p_##__name)(args...);
\
}
\
};
\
extern DynLoad__##__name __name
#else
#define DECLARE_DYNAMIC_LOAD_CURAND_WRAP(__name) \
...
...
paddle/fluid/platform/dynload/dynamic_loader.cc
浏览文件 @
9eaf4458
...
...
@@ -11,12 +11,14 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
#include <dlfcn.h>
#include <memory>
#include <mutex>
#include <mutex>
// NOLINT
#include <string>
#include "gflags/gflags.h"
#include "glog/logging.h"
#include "paddle/fluid/platform/dynload/cupti_lib_path.h"
...
...
@@ -65,22 +67,21 @@ static inline std::string join(const std::string& part1,
return
ret
;
}
static
inline
void
GetDsoHandleFromDefaultPath
(
std
::
string
&
dso_path
,
void
**
dso_handle
,
int
dynload_flags
)
{
static
inline
void
*
GetDsoHandleFromDefaultPath
(
const
std
::
string
&
dso_path
,
int
dynload_flags
)
{
VLOG
(
3
)
<<
"Try to find library: "
<<
dso_path
<<
" from default system path."
;
// default search from LD_LIBRARY_PATH/DYLD_LIBRARY_PATH
*
dso_handle
=
dlopen
(
dso_path
.
c_str
(),
dynload_flags
);
void
*
dso_handle
=
dlopen
(
dso_path
.
c_str
(),
dynload_flags
);
// DYLD_LIBRARY_PATH is disabled after Mac OS 10.11 to
// bring System Integrity Projection (SIP), if dso_handle
// is null, search from default package path in Mac OS.
#if defined(__APPLE__) || defined(__OSX__)
if
(
nullptr
==
*
dso_handle
)
{
dso_
path
=
join
(
"/usr/local/cuda/lib/"
,
dso_path
);
*
dso_handle
=
dlopen
(
dso_path
.
c_str
(),
dynload_flags
);
if
(
nullptr
==
*
dso_handle
)
{
if
(
nullptr
==
dso_handle
)
{
dso_
handle
=
dlopen
(
join
(
"/usr/local/cuda/lib/"
,
dso_path
)
.
c_str
(),
dynload_flags
);
if
(
nullptr
==
dso_handle
)
{
if
(
dso_path
==
"libcudnn.dylib"
)
{
LOG
(
WARNING
)
<<
"Note: [Recommend] copy cudnn into /usr/local/cuda/
\n
"
"For instance, sudo tar -xzf "
...
...
@@ -91,28 +92,29 @@ static inline void GetDsoHandleFromDefaultPath(std::string& dso_path,
}
}
#endif
return
dso_handle
;
}
static
inline
void
GetDsoHandleFromSearchPath
(
const
std
::
string
&
search_root
,
const
std
::
string
&
dso_name
,
void
**
dso_handle
,
bool
throw_on_error
=
true
)
{
static
inline
void
*
GetDsoHandleFromSearchPath
(
const
std
::
string
&
search_root
,
const
std
::
string
&
dso_name
,
bool
throw_on_error
=
true
)
{
int
dynload_flags
=
RTLD_LAZY
|
RTLD_LOCAL
;
*
dso_handle
=
nullptr
;
void
*
dso_handle
=
nullptr
;
std
::
string
dlPath
=
dso_name
;
if
(
search_root
.
empty
())
{
GetDsoHandleFromDefaultPath
(
dlPath
,
dso_handle
,
dynload_flags
);
dso_handle
=
GetDsoHandleFromDefaultPath
(
dlPath
,
dynload_flags
);
}
else
{
// search xxx.so from custom path
dlPath
=
join
(
search_root
,
dso_name
);
*
dso_handle
=
dlopen
(
dlPath
.
c_str
(),
dynload_flags
);
dso_handle
=
dlopen
(
dlPath
.
c_str
(),
dynload_flags
);
// if not found, search from default path
if
(
nullptr
==
*
dso_handle
)
{
if
(
nullptr
==
dso_handle
)
{
LOG
(
WARNING
)
<<
"Failed to find dynamic library: "
<<
dlPath
<<
" ("
<<
dlerror
()
<<
")"
;
dlPath
=
dso_name
;
GetDsoHandleFromDefaultPath
(
dlPath
,
dso_handle
,
dynload_flags
);
dso_handle
=
GetDsoHandleFromDefaultPath
(
dlPath
,
dynload_flags
);
}
}
auto
error_msg
=
...
...
@@ -124,70 +126,71 @@ static inline void GetDsoHandleFromSearchPath(const std::string& search_root,
"using the DYLD_LIBRARY_PATH is impossible unless System "
"Integrity Protection (SIP) is disabled."
;
if
(
throw_on_error
)
{
PADDLE_ENFORCE
(
nullptr
!=
*
dso_handle
,
error_msg
,
dlPath
,
dlerror
());
}
else
if
(
nullptr
==
*
dso_handle
)
{
PADDLE_ENFORCE
(
nullptr
!=
dso_handle
,
error_msg
,
dlPath
,
dlerror
());
}
else
if
(
nullptr
==
dso_handle
)
{
LOG
(
WARNING
)
<<
string
::
Sprintf
(
error_msg
,
dlPath
,
dlerror
());
}
return
dso_handle
;
}
void
GetCublasDsoHandle
(
void
**
dso_handle
)
{
void
*
GetCublasDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcublas.dylib"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcublas.dylib"
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcublas.so"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcublas.so"
);
#endif
}
void
GetCUDNNDsoHandle
(
void
**
dso_handle
)
{
void
*
GetCUDNNDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_cudnn_dir
,
"libcudnn.dylib"
,
dso_handle
,
false
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cudnn_dir
,
"libcudnn.dylib"
,
false
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_cudnn_dir
,
"libcudnn.so"
,
dso_handle
,
false
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cudnn_dir
,
"libcudnn.so"
,
false
);
#endif
}
void
GetCUPTIDsoHandle
(
void
**
dso_handle
)
{
void
*
GetCUPTIDsoHandle
(
)
{
std
::
string
cupti_path
=
cupti_lib_path
;
if
(
!
FLAGS_cupti_dir
.
empty
())
{
cupti_path
=
FLAGS_cupti_dir
;
}
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
cupti_path
,
"libcupti.dylib"
,
dso_handle
,
false
);
return
GetDsoHandleFromSearchPath
(
cupti_path
,
"libcupti.dylib"
,
false
);
#else
GetDsoHandleFromSearchPath
(
cupti_path
,
"libcupti.so"
,
dso_handle
,
false
);
return
GetDsoHandleFromSearchPath
(
cupti_path
,
"libcupti.so"
,
false
);
#endif
}
void
GetCurandDsoHandle
(
void
**
dso_handle
)
{
void
*
GetCurandDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcurand.dylib"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcurand.dylib"
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcurand.so"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_cuda_dir
,
"libcurand.so"
);
#endif
}
void
GetWarpCTCDsoHandle
(
void
**
dso_handle
)
{
void
*
GetWarpCTCDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_warpctc_dir
,
"libwarpctc.dylib"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_warpctc_dir
,
"libwarpctc.dylib"
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_warpctc_dir
,
"libwarpctc.so"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_warpctc_dir
,
"libwarpctc.so"
);
#endif
}
void
GetLapackDsoHandle
(
void
**
dso_handle
)
{
void
*
GetLapackDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_lapack_dir
,
"liblapacke.dylib"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_lapack_dir
,
"liblapacke.dylib"
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_lapack_dir
,
"liblapacke.so"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_lapack_dir
,
"liblapacke.so"
);
#endif
}
void
GetNCCLDsoHandle
(
void
**
dso_handle
)
{
void
*
GetNCCLDsoHandle
(
)
{
#if defined(__APPLE__) || defined(__OSX__)
GetDsoHandleFromSearchPath
(
FLAGS_nccl_dir
,
"libnccl.dylib"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_nccl_dir
,
"libnccl.dylib"
);
#else
GetDsoHandleFromSearchPath
(
FLAGS_nccl_dir
,
"libnccl.so"
,
dso_handle
);
return
GetDsoHandleFromSearchPath
(
FLAGS_nccl_dir
,
"libnccl.so"
);
#endif
}
...
...
paddle/fluid/platform/dynload/dynamic_loader.h
浏览文件 @
9eaf4458
...
...
@@ -18,55 +18,13 @@ namespace paddle {
namespace
platform
{
namespace
dynload
{
/**
* @brief load the DSO of CUBLAS
*
* @param **dso_handle dso handler
*
*/
void
GetCublasDsoHandle
(
void
**
dso_handle
);
/**
* @brief load the DSO of CUDNN
*
* @param **dso_handle dso handler
*
*/
void
GetCUDNNDsoHandle
(
void
**
dso_handle
);
void
GetCUPTIDsoHandle
(
void
**
dso_handle
);
/**
* @brief load the DSO of CURAND
*
* @param **dso_handle dso handler
*
*/
void
GetCurandDsoHandle
(
void
**
dso_handle
);
/**
* @brief load the DSO of warp-ctc
*
* @param **dso_handle dso handler
*
*/
void
GetWarpCTCDsoHandle
(
void
**
dso_handle
);
/**
* @brief load the DSO of lapack
*
* @param **dso_handle dso handler
*
*/
void
GetLapackDsoHandle
(
void
**
dso_handle
);
/**
* @brief load the DSO of NVIDIA nccl
*
* @param **dso_handle dso handler
*
*/
void
GetNCCLDsoHandle
(
void
**
dso_handle
);
void
*
GetCublasDsoHandle
();
void
*
GetCUDNNDsoHandle
();
void
*
GetCUPTIDsoHandle
();
void
*
GetCurandDsoHandle
();
void
*
GetWarpCTCDsoHandle
();
void
*
GetLapackDsoHandle
();
void
*
GetNCCLDsoHandle
();
}
// namespace dynload
}
// namespace platform
...
...
paddle/fluid/platform/dynload/nccl.cc
浏览文件 @
9eaf4458
...
...
@@ -25,11 +25,6 @@ void *nccl_dso_handle;
NCCL_RAND_ROUTINE_EACH
(
DEFINE_WRAP
);
void
LoadNCCLDSO
()
{
platform
::
call_once
(
nccl_dso_flag
,
[]
{
GetNCCLDsoHandle
(
&
nccl_dso_handle
);
});
}
}
// namespace dynload
}
// namespace platform
}
// namespace paddle
paddle/fluid/platform/dynload/nccl.h
浏览文件 @
9eaf4458
...
...
@@ -11,12 +11,13 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <dlfcn.h>
#include <nccl.h>
#include <mutex>
#include <mutex> // NOLINT
#include "paddle/fluid/platform/call_once.h"
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
...
...
@@ -28,18 +29,19 @@ extern std::once_flag nccl_dso_flag;
extern
void
*
nccl_dso_handle
;
#ifdef PADDLE_USE_DSO
extern
void
LoadNCCLDSO
();
#define DECLARE_DYNAMIC_LOAD_NCCL_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
auto operator()(Args... args) -> decltype(__name(args...)) { \
using nccl_func = decltype(__name(args...)) (*)(Args...); \
paddle::platform::dynload::LoadNCCLDSO(); \
void* p_##__name = dlsym(nccl_dso_handle, #__name); \
return reinterpret_cast<nccl_func>(p_##__name)(args...); \
} \
}; \
#define DECLARE_DYNAMIC_LOAD_NCCL_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
auto operator()(Args... args) -> decltype(__name(args...)) { \
using nccl_func = decltype(__name(args...)) (*)(Args...); \
std::call_once(nccl_dso_flag, []() { \
nccl_dso_handle = paddle::platform::dynload::GetNCCLDsoHandle(); \
}); \
void* p_##__name = dlsym(nccl_dso_handle, #__name); \
return reinterpret_cast<nccl_func>(p_##__name)(args...); \
} \
}; \
extern DynLoad__##__name __name
#else
#define DECLARE_DYNAMIC_LOAD_NCCL_WRAP(__name) \
...
...
paddle/fluid/platform/dynload/warpctc.h
浏览文件 @
9eaf4458
...
...
@@ -15,9 +15,10 @@ limitations under the License. */
#pragma once
#include <dlfcn.h>
#include <mutex>
#include "ctc.h"
#include <mutex>
// NOLINT
#include "paddle/fluid/platform/dynload/dynamic_loader.h"
#include "warpctc/include/ctc.h"
namespace
paddle
{
namespace
platform
{
...
...
@@ -31,18 +32,18 @@ extern void* warpctc_dso_handle;
* (for each function) to dynamic load warpctc routine
* via operator overloading.
*/
#define DYNAMIC_LOAD_WARPCTC_WRAP(__name) \
struct DynLoad__##__name { \
template <typename... Args> \
auto operator()(Args... args) -> decltype(__name(args...)) { \
using warpctcFunc = decltype(__name(args...)) (*)(Args...); \
std::call_once(warpctc_dso_flag, \
paddle::platform::dynload::GetWarpCTCDsoHandle,
\
&warpctc_dso_handle);
\
void* p_##_name = dlsym(warpctc_dso_handle, #__name); \
return reinterpret_cast<warpctcFunc>(p_##_name)(args...); \
} \
}; \
#define DYNAMIC_LOAD_WARPCTC_WRAP(__name)
\
struct DynLoad__##__name {
\
template <typename... Args>
\
auto operator()(Args... args) -> decltype(__name(args...)) {
\
using warpctcFunc = decltype(__name(args...)) (*)(Args...);
\
std::call_once(warpctc_dso_flag,
[]() {
\
warpctc_dso_handle = paddle::platform::dynload::GetWarpCTCDsoHandle();
\
});
\
void* p_##_name = dlsym(warpctc_dso_handle, #__name);
\
return reinterpret_cast<warpctcFunc>(p_##_name)(args...);
\
}
\
};
\
extern DynLoad__##__name __name
#define DECLARE_DYNAMIC_LOAD_WARPCTC_WRAP(__name) \
...
...
paddle/fluid/platform/enforce.h
浏览文件 @
9eaf4458
...
...
@@ -16,35 +16,35 @@ limitations under the License. */
#include <dlfcn.h> // for dladdr
#include <execinfo.h> // for backtrace
#ifdef __GNUC__
#include <cxxabi.h> // for __cxa_demangle
#endif // __GNUC__
#ifdef PADDLE_WITH_CUDA
#include <cublas_v2.h>
#include <cudnn.h>
#include <curand.h>
#include <thrust/system/cuda/error.h>
#include <thrust/system_error.h>
#endif // PADDLE_WITH_CUDA
#include <iomanip>
#include <memory>
#include <sstream>
#include <stdexcept>
#include <string>
#include "glog/logging.h"
#include "paddle/fluid/platform/macros.h"
#include "paddle/fluid/string/printf.h"
#include "paddle/fluid/string/to_string.h"
#ifdef __GNUC__
#include <cxxabi.h> // for __cxa_demangle
#endif
#include <glog/logging.h>
#ifdef PADDLE_WITH_CUDA
#include "paddle/fluid/platform/dynload/cublas.h"
#include "paddle/fluid/platform/dynload/cudnn.h"
#include "paddle/fluid/platform/dynload/curand.h"
#include "paddle/fluid/platform/dynload/nccl.h"
#include <cublas_v2.h>
#include <cudnn.h>
#include <curand.h>
#include <thrust/system/cuda/error.h>
#include <thrust/system_error.h>
#endif
namespace
paddle
{
...
...
@@ -185,7 +185,7 @@ inline typename std::enable_if<sizeof...(Args) != 0, void>::type throw_on_error(
}
}
#endif // PADDLE_
ONLY_CPU
#endif // PADDLE_
WITH_CUDA
template
<
typename
T
>
inline
void
throw_on_error
(
T
e
)
{
...
...
paddle/fluid/platform/enforce_test.cc
浏览文件 @
9eaf4458
...
...
@@ -96,7 +96,6 @@ TEST(ENFORCE_GT, FAIL) {
bool
caught_exception
=
false
;
try
{
PADDLE_ENFORCE_GT
(
1
,
2UL
);
}
catch
(
paddle
::
platform
::
EnforceNotMet
error
)
{
caught_exception
=
true
;
EXPECT_TRUE
(
...
...
@@ -115,7 +114,6 @@ TEST(ENFORCE_GE, FAIL) {
bool
caught_exception
=
false
;
try
{
PADDLE_ENFORCE_GE
(
1
,
2UL
);
}
catch
(
paddle
::
platform
::
EnforceNotMet
error
)
{
caught_exception
=
true
;
EXPECT_TRUE
(
...
...
@@ -135,7 +133,6 @@ TEST(ENFORCE_LE, FAIL) {
bool
caught_exception
=
false
;
try
{
PADDLE_ENFORCE_GT
(
1
,
2UL
);
}
catch
(
paddle
::
platform
::
EnforceNotMet
error
)
{
caught_exception
=
true
;
EXPECT_TRUE
(
...
...
@@ -171,7 +168,6 @@ TEST(ENFORCE_NOT_NULL, FAIL) {
try
{
int
*
a
=
nullptr
;
PADDLE_ENFORCE_NOT_NULL
(
a
);
}
catch
(
paddle
::
platform
::
EnforceNotMet
error
)
{
caught_exception
=
true
;
EXPECT_TRUE
(
HasPrefix
(
StringPiece
(
error
.
what
()),
"a should not be null"
));
...
...
paddle/fluid/platform/float16.h
浏览文件 @
9eaf4458
...
...
@@ -15,6 +15,7 @@ limitations under the License. */
#pragma once
#include <stdint.h>
#include <limits>
#ifdef PADDLE_WITH_CUDA
#include <cuda.h>
...
...
@@ -293,39 +294,39 @@ struct PADDLE_ALIGN(2) float16 {
HOSTDEVICE
inline
explicit
operator
bool
()
const
{
return
(
x
&
0x7fff
)
!=
0
;
}
HOSTDEVICE
inline
explicit
operator
int8_t
()
const
{
return
static_cast
<
int8_t
>
(
float
(
*
this
));
return
static_cast
<
int8_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
uint8_t
()
const
{
return
static_cast
<
uint8_t
>
(
float
(
*
this
));
return
static_cast
<
uint8_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
int16_t
()
const
{
return
static_cast
<
int16_t
>
(
float
(
*
this
));
return
static_cast
<
int16_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
uint16_t
()
const
{
return
static_cast
<
uint16_t
>
(
float
(
*
this
));
return
static_cast
<
uint16_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
int32_t
()
const
{
return
static_cast
<
int32_t
>
(
float
(
*
this
));
return
static_cast
<
int32_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
uint32_t
()
const
{
return
static_cast
<
uint32_t
>
(
float
(
*
this
));
return
static_cast
<
uint32_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
int64_t
()
const
{
return
static_cast
<
int64_t
>
(
float
(
*
this
));
return
static_cast
<
int64_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
uint64_t
()
const
{
return
static_cast
<
uint64_t
>
(
float
(
*
this
));
return
static_cast
<
uint64_t
>
(
static_cast
<
float
>
(
*
this
));
}
HOSTDEVICE
inline
explicit
operator
double
()
const
{
return
static_cast
<
double
>
(
float
(
*
this
));
return
static_cast
<
double
>
(
static_cast
<
float
>
(
*
this
));
}
private:
...
...
@@ -370,7 +371,7 @@ DEVICE inline half operator+(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hadd
(
a
,
b
);
#else
float
res
=
float
(
float16
(
a
))
+
float
(
float16
(
b
));
float
res
=
static_cast
<
float
>
(
float16
(
a
))
+
static_cast
<
float
>
(
float16
(
b
));
return
half
(
float16
(
res
));
#endif
}
...
...
@@ -379,7 +380,7 @@ DEVICE inline half operator-(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hsub
(
a
,
b
);
#else
float
res
=
float
(
float16
(
a
))
-
float
(
float16
(
b
));
float
res
=
static_cast
<
float
>
(
float16
(
a
))
-
static_cast
<
float
>
(
float16
(
b
));
return
half
(
float16
(
res
));
#endif
}
...
...
@@ -388,7 +389,7 @@ DEVICE inline half operator*(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hmul
(
a
,
b
);
#else
float
res
=
float
(
float16
(
a
))
*
float
(
float16
(
b
));
float
res
=
static_cast
<
float
>
(
float16
(
a
))
*
static_cast
<
float
>
(
float16
(
b
));
return
half
(
float16
(
res
));
#endif
}
...
...
@@ -399,7 +400,7 @@ DEVICE inline half operator/(const half& a, const half& b) {
float
denom
=
__half2float
(
b
);
return
__float2half
(
num
/
denom
);
#else
float
res
=
float
(
float16
(
a
))
/
float
(
float16
(
b
));
float
res
=
static_cast
<
float
>
(
float16
(
a
))
/
static_cast
<
float
>
(
float16
(
b
));
return
half
(
float16
(
res
));
#endif
}
...
...
@@ -408,27 +409,27 @@ DEVICE inline half operator-(const half& a) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hneg
(
a
);
#else
float
res
=
-
float
(
float16
(
a
));
float
res
=
-
static_cast
<
float
>
(
float16
(
a
));
return
half
(
float16
(
res
));
#endif
}
DEVICE
inline
half
&
operator
+=
(
half
&
a
,
const
half
&
b
)
{
DEVICE
inline
half
&
operator
+=
(
half
&
a
,
const
half
&
b
)
{
// NOLINT
a
=
a
+
b
;
return
a
;
}
DEVICE
inline
half
&
operator
-=
(
half
&
a
,
const
half
&
b
)
{
DEVICE
inline
half
&
operator
-=
(
half
&
a
,
const
half
&
b
)
{
// NOLINT
a
=
a
-
b
;
return
a
;
}
DEVICE
inline
half
&
operator
*=
(
half
&
a
,
const
half
&
b
)
{
DEVICE
inline
half
&
operator
*=
(
half
&
a
,
const
half
&
b
)
{
// NOLINT
a
=
a
*
b
;
return
a
;
}
DEVICE
inline
half
&
operator
/=
(
half
&
a
,
const
half
&
b
)
{
DEVICE
inline
half
&
operator
/=
(
half
&
a
,
const
half
&
b
)
{
// NOLINT
a
=
a
/
b
;
return
a
;
}
...
...
@@ -437,7 +438,7 @@ DEVICE inline bool operator==(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__heq
(
a
,
b
);
#else
return
float
(
float16
(
a
))
==
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
==
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -445,7 +446,7 @@ DEVICE inline bool operator!=(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hne
(
a
,
b
);
#else
return
float
(
float16
(
a
))
!=
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
!=
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -453,7 +454,7 @@ DEVICE inline bool operator<(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hlt
(
a
,
b
);
#else
return
float
(
float16
(
a
))
<
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
<
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -461,7 +462,7 @@ DEVICE inline bool operator<=(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hle
(
a
,
b
);
#else
return
float
(
float16
(
a
))
<=
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
<=
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -469,7 +470,7 @@ DEVICE inline bool operator>(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hgt
(
a
,
b
);
#else
return
float
(
float16
(
a
))
>
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
>
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -477,7 +478,7 @@ DEVICE inline bool operator>=(const half& a, const half& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hge
(
a
,
b
);
#else
return
float
(
float16
(
a
))
>=
float
(
float16
(
b
));
return
static_cast
<
float
>
(
float16
(
a
))
>=
static_cast
<
float
>
(
float16
(
b
));
#endif
}
...
...
@@ -489,7 +490,7 @@ HOSTDEVICE inline float16 operator+(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
float16
(
__hadd
(
half
(
a
),
half
(
b
)));
#else
return
float16
(
float
(
a
)
+
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
+
static_cast
<
float
>
(
b
));
#endif
}
...
...
@@ -497,7 +498,7 @@ HOSTDEVICE inline float16 operator-(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
float16
(
__hsub
(
half
(
a
),
half
(
b
)));
#else
return
float16
(
float
(
a
)
-
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
-
static_cast
<
float
>
(
b
));
#endif
}
...
...
@@ -505,7 +506,7 @@ HOSTDEVICE inline float16 operator*(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
float16
(
__hmul
(
half
(
a
),
half
(
b
)));
#else
return
float16
(
float
(
a
)
*
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
*
static_cast
<
float
>
(
b
));
#endif
}
...
...
@@ -516,7 +517,7 @@ HOSTDEVICE inline float16 operator/(const float16& a, const float16& b) {
float
denom
=
__half2float
(
half
(
b
));
return
float16
(
num
/
denom
);
#else
return
float16
(
float
(
a
)
/
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
/
static_cast
<
float
>
(
b
));
#endif
}
...
...
@@ -530,22 +531,22 @@ HOSTDEVICE inline float16 operator-(const float16& a) {
#endif
}
HOSTDEVICE
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
HOSTDEVICE
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
+
b
;
return
a
;
}
HOSTDEVICE
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
HOSTDEVICE
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
-
b
;
return
a
;
}
HOSTDEVICE
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
HOSTDEVICE
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
*
b
;
return
a
;
}
HOSTDEVICE
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
HOSTDEVICE
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
/
b
;
return
a
;
}
...
...
@@ -554,7 +555,7 @@ HOSTDEVICE inline bool operator==(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__heq
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
==
float
(
b
);
return
static_cast
<
float
>
(
a
)
==
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -562,7 +563,7 @@ HOSTDEVICE inline bool operator!=(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hne
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
!=
float
(
b
);
return
static_cast
<
float
>
(
a
)
!=
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -570,7 +571,7 @@ HOSTDEVICE inline bool operator<(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hlt
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
<
float
(
b
);
return
static_cast
<
float
>
(
a
)
<
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -578,7 +579,7 @@ HOSTDEVICE inline bool operator<=(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hle
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
<=
float
(
b
);
return
static_cast
<
float
>
(
a
)
<=
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -586,7 +587,7 @@ HOSTDEVICE inline bool operator>(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hgt
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
>
float
(
b
);
return
static_cast
<
float
>
(
a
)
>
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -594,7 +595,7 @@ HOSTDEVICE inline bool operator>=(const float16& a, const float16& b) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hge
(
half
(
a
),
half
(
b
));
#else
return
float
(
a
)
>=
float
(
b
);
return
static_cast
<
float
>
(
a
)
>=
static_cast
<
float
>
(
b
);
#endif
}
...
...
@@ -679,22 +680,22 @@ inline float16 operator-(const float16& a) {
return
res
;
}
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
+
b
;
return
a
;
}
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
-
b
;
return
a
;
}
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
*
b
;
return
a
;
}
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
a
/
b
;
return
a
;
}
...
...
@@ -784,19 +785,19 @@ inline bool operator>=(const float16& a, const float16& b) {
// Arithmetic operators for float16, software emulated on other CPU
#else
inline
float16
operator
+
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
+
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
+
static_cast
<
float
>
(
b
));
}
inline
float16
operator
-
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
-
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
-
static_cast
<
float
>
(
b
));
}
inline
float16
operator
*
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
*
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
*
static_cast
<
float
>
(
b
));
}
inline
float16
operator
/
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
/
float
(
b
));
return
float16
(
static_cast
<
float
>
(
a
)
/
static_cast
<
float
>
(
b
));
}
inline
float16
operator
-
(
const
float16
&
a
)
{
...
...
@@ -805,51 +806,57 @@ inline float16 operator-(const float16& a) {
return
res
;
}
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
+
float
(
b
));
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
float16
(
static_cast
<
float
>
(
a
)
+
static_cast
<
float
>
(
b
));
return
a
;
}
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
-
float
(
b
));
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
float16
(
static_cast
<
float
>
(
a
)
-
static_cast
<
float
>
(
b
));
return
a
;
}
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
*
float
(
b
));
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
float16
(
static_cast
<
float
>
(
a
)
*
static_cast
<
float
>
(
b
));
return
a
;
}
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
/
float
(
b
));
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
// NOLINT
a
=
float16
(
static_cast
<
float
>
(
a
)
/
static_cast
<
float
>
(
b
));
return
a
;
}
inline
bool
operator
==
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
==
float
(
b
);
return
static_cast
<
float
>
(
a
)
==
static_cast
<
float
>
(
b
);
}
inline
bool
operator
!=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
!=
float
(
b
);
return
static_cast
<
float
>
(
a
)
!=
static_cast
<
float
>
(
b
);
}
inline
bool
operator
<
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
<
float
(
b
);
return
static_cast
<
float
>
(
a
)
<
static_cast
<
float
>
(
b
);
}
inline
bool
operator
<=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
<=
float
(
b
);
return
static_cast
<
float
>
(
a
)
<=
static_cast
<
float
>
(
b
);
}
inline
bool
operator
>
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
>
float
(
b
);
return
static_cast
<
float
>
(
a
)
>
static_cast
<
float
>
(
b
);
}
inline
bool
operator
>=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
>=
float
(
b
);
return
static_cast
<
float
>
(
a
)
>=
static_cast
<
float
>
(
b
);
}
#endif
HOSTDEVICE
inline
float16
raw_uint16_to_float16
(
uint16_t
a
)
{
float16
res
;
res
.
x
=
a
;
return
res
;
}
HOSTDEVICE
inline
bool
(
isnan
)(
const
float16
&
a
)
{
#if defined(PADDLE_CUDA_FP16) && defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 530
return
__hisnan
(
half
(
a
));
...
...
@@ -886,28 +893,116 @@ struct is_pod<paddle::platform::float16> {
is_standard_layout
<
paddle
::
platform
::
float16
>::
value
;
};
template
<
>
struct
numeric_limits
<
paddle
::
platform
::
float16
>
{
static
const
bool
is_specialized
=
true
;
static
const
bool
is_signed
=
true
;
static
const
bool
is_integer
=
false
;
static
const
bool
is_exact
=
false
;
static
const
bool
has_infinity
=
true
;
static
const
bool
has_quiet_NaN
=
true
;
static
const
bool
has_signaling_NaN
=
true
;
static
const
float_denorm_style
has_denorm
=
denorm_present
;
static
const
bool
has_denorm_loss
=
false
;
static
const
std
::
float_round_style
round_style
=
std
::
round_to_nearest
;
static
const
bool
is_iec559
=
false
;
static
const
bool
is_bounded
=
false
;
static
const
bool
is_modulo
=
false
;
static
const
int
digits
=
11
;
static
const
int
digits10
=
3
;
static
const
int
max_digits10
=
5
;
static
const
int
radix
=
2
;
static
const
int
min_exponent
=
-
13
;
static
const
int
min_exponent10
=
-
4
;
static
const
int
max_exponent
=
16
;
static
const
int
max_exponent10
=
4
;
static
const
bool
traps
=
true
;
static
const
bool
tinyness_before
=
false
;
static
paddle
::
platform
::
float16
(
min
)()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x400
);
}
static
paddle
::
platform
::
float16
lowest
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0xfbff
);
}
static
paddle
::
platform
::
float16
(
max
)()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7bff
);
}
static
paddle
::
platform
::
float16
epsilon
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x0800
);
}
static
paddle
::
platform
::
float16
round_error
()
{
return
paddle
::
platform
::
float16
(
0.5
);
}
static
paddle
::
platform
::
float16
infinity
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7c00
);
}
static
paddle
::
platform
::
float16
quiet_NaN
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7e00
);
}
static
paddle
::
platform
::
float16
signaling_NaN
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7e00
);
}
static
paddle
::
platform
::
float16
denorm_min
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x1
);
}
};
}
// namespace std
namespace
Eigen
{
using
float16
=
paddle
::
platform
::
float16
;
template
<
>
struct
NumTraits
<
float16
>
:
GenericNumTraits
<
float16
>
{
enum
{
IsSigned
=
true
,
IsInteger
=
false
,
IsComplex
=
false
,
RequireInitialization
=
false
};
HOSTDEVICE
static
inline
float16
epsilon
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x0800
);
}
HOSTDEVICE
static
inline
float16
dummy_precision
()
{
return
float16
(
1e-2
f
);
}
HOSTDEVICE
static
inline
float16
highest
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7bff
);
}
HOSTDEVICE
static
inline
float16
lowest
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0xfbff
);
}
HOSTDEVICE
static
inline
float16
infinity
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7c00
);
}
HOSTDEVICE
static
inline
float16
quiet_NaN
()
{
return
paddle
::
platform
::
raw_uint16_to_float16
(
0x7c01
);
}
};
namespace
numext
{
template
<
>
EIGEN_DEVICE_FUNC
EIGEN_ALWAYS_INLINE
bool
(
isnan
)(
const
paddle
::
platform
::
float16
&
a
)
{
HOSTDEVICE
inline
bool
(
isnan
)(
const
float16
&
a
)
{
return
(
paddle
::
platform
::
isnan
)(
a
);
}
template
<
>
EIGEN_DEVICE_FUNC
EIGEN_ALWAYS_INLINE
bool
(
isinf
)(
const
paddle
::
platform
::
float16
&
a
)
{
HOSTDEVICE
inline
bool
(
isinf
)(
const
float16
&
a
)
{
return
(
paddle
::
platform
::
isinf
)(
a
);
}
template
<
>
EIGEN_DEVICE_FUNC
EIGEN_ALWAYS_INLINE
bool
(
isfinite
)(
const
paddle
::
platform
::
float16
&
a
)
{
HOSTDEVICE
inline
bool
(
isfinite
)(
const
float16
&
a
)
{
return
(
paddle
::
platform
::
isfinite
)(
a
);
}
template
<
>
HOSTDEVICE
inline
float16
exp
(
const
float16
&
a
)
{
return
float16
(
::
expf
(
static_cast
<
float
>
(
a
)));
}
}
// namespace numext
}
// namespace Eigen
paddle/fluid/platform/gpu_info.cc
浏览文件 @
9eaf4458
...
...
@@ -14,8 +14,9 @@ limitations under the License. */
#include "paddle/fluid/platform/gpu_info.h"
#include
"gflags/gflags.h"
#include
<algorithm>
#include "gflags/gflags.h"
#include "paddle/fluid/platform/enforce.h"
DEFINE_double
(
fraction_of_gpu_memory_to_use
,
0.92
,
...
...
@@ -77,8 +78,8 @@ void SetDeviceId(int id) {
"cudaSetDevice failed in paddle::platform::SetDeviceId"
);
}
void
GpuMemoryUsage
(
size_t
&
available
,
size_t
&
total
)
{
PADDLE_ENFORCE
(
cudaMemGetInfo
(
&
available
,
&
total
),
void
GpuMemoryUsage
(
size_t
*
available
,
size_t
*
total
)
{
PADDLE_ENFORCE
(
cudaMemGetInfo
(
available
,
total
),
"cudaMemGetInfo failed in paddle::platform::GetMemoryUsage"
);
}
...
...
@@ -86,7 +87,7 @@ size_t GpuMaxAllocSize() {
size_t
total
=
0
;
size_t
available
=
0
;
GpuMemoryUsage
(
available
,
total
);
GpuMemoryUsage
(
&
available
,
&
total
);
// Reserve the rest for page tables, etc.
return
static_cast
<
size_t
>
(
total
*
FLAGS_fraction_of_gpu_memory_to_use
);
...
...
@@ -101,7 +102,7 @@ size_t GpuMaxChunkSize() {
size_t
total
=
0
;
size_t
available
=
0
;
GpuMemoryUsage
(
available
,
total
);
GpuMemoryUsage
(
&
available
,
&
total
);
VLOG
(
10
)
<<
"GPU Usage "
<<
available
/
1024
/
1024
<<
"M/"
<<
total
/
1024
/
1024
<<
"M"
;
size_t
reserving
=
static_cast
<
size_t
>
(
0.05
*
total
);
...
...
paddle/fluid/platform/gpu_info.h
浏览文件 @
9eaf4458
...
...
@@ -23,10 +23,6 @@ limitations under the License. */
namespace
paddle
{
namespace
platform
{
//! Environment variable: fraction of GPU memory to use on each device.
const
std
::
string
kEnvFractionGpuMemoryToUse
=
"PADDLE_FRACTION_GPU_MEMORY_TO_USE"
;
//! Get the total number of GPU devices in system.
int
GetCUDADeviceCount
();
...
...
@@ -46,7 +42,7 @@ int GetCurrentDeviceId();
void
SetDeviceId
(
int
device_id
);
//! Get the memory usage of current GPU device.
void
GpuMemoryUsage
(
size_t
&
available
,
size_t
&
total
);
void
GpuMemoryUsage
(
size_t
*
available
,
size_t
*
total
);
//! Get the maximum allocation size of current GPU device.
size_t
GpuMaxAllocSize
();
...
...
paddle/fluid/platform/place.h
浏览文件 @
9eaf4458
...
...
@@ -11,10 +11,11 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <iostream>
#include <vector>
#include "paddle/fluid/platform/enforce.h"
#include "paddle/fluid/platform/variant.h"
...
...
paddle/fluid/pybind/.clang-format
已删除
100644 → 0
浏览文件 @
f132f51e
---
Language: Cpp
BasedOnStyle: Google
Standard: Cpp11
...
paddle/fluid/pybind/CMakeLists.txt
浏览文件 @
9eaf4458
...
...
@@ -15,4 +15,6 @@ if(WITH_PYTHON)
target_link_libraries
(
paddle_pybind rt
)
endif
(
NOT APPLE AND NOT ANDROID
)
endif
(
WITH_AMD_GPU
)
cc_test
(
tensor_py_test SRCS tensor_py_test.cc DEPS python
)
endif
(
WITH_PYTHON
)
paddle/fluid/pybind/const_value.cc
浏览文件 @
9eaf4458
...
...
@@ -12,17 +12,17 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "const_value.h"
#include "
paddle/fluid/pybind/
const_value.h"
#include "paddle/fluid/framework/operator.h"
namespace
paddle
{
namespace
pybind
{
void
BindConstValue
(
pybind11
::
module
&
m
)
{
m
.
def
(
"kEmptyVarName"
,
[]
{
return
framework
::
kEmptyVarName
;
});
m
.
def
(
"kTempVarName"
,
[]
{
return
framework
::
kTempVarName
;
});
m
.
def
(
"kGradVarSuffix"
,
[]
{
return
framework
::
kGradVarSuffix
;
});
m
.
def
(
"kZeroVarSuffix"
,
[]
{
return
framework
::
kZeroVarSuffix
;
});
void
BindConstValue
(
pybind11
::
module
*
m
)
{
m
->
def
(
"kEmptyVarName"
,
[]
{
return
framework
::
kEmptyVarName
;
});
m
->
def
(
"kTempVarName"
,
[]
{
return
framework
::
kTempVarName
;
});
m
->
def
(
"kGradVarSuffix"
,
[]
{
return
framework
::
kGradVarSuffix
;
});
m
->
def
(
"kZeroVarSuffix"
,
[]
{
return
framework
::
kZeroVarSuffix
;
});
}
}
// namespace pybind
...
...
paddle/fluid/pybind/const_value.h
浏览文件 @
9eaf4458
...
...
@@ -11,16 +11,17 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <Python.h>
#include "paddle/fluid/platform/enforce.h"
#include "pybind11/pybind11.h"
namespace
py
=
pybind11
;
namespace
paddle
{
namespace
pybind
{
extern
void
BindConstValue
(
pybind11
::
module
&
m
);
void
BindConstValue
(
pybind11
::
module
*
m
);
}
// namespace pybind
}
// namespace paddle
paddle/fluid/pybind/exception.cc
浏览文件 @
9eaf4458
...
...
@@ -17,8 +17,8 @@ limitations under the License. */
namespace
paddle
{
namespace
pybind
{
void
BindException
(
pybind11
::
module
&
m
)
{
static
pybind11
::
exception
<
platform
::
EnforceNotMet
>
exc
(
m
,
"EnforceNotMet"
);
void
BindException
(
pybind11
::
module
*
m
)
{
static
pybind11
::
exception
<
platform
::
EnforceNotMet
>
exc
(
*
m
,
"EnforceNotMet"
);
pybind11
::
register_exception_translator
([](
std
::
exception_ptr
p
)
{
try
{
if
(
p
)
std
::
rethrow_exception
(
p
);
...
...
@@ -27,7 +27,8 @@ void BindException(pybind11::module& m) {
}
});
m
.
def
(
"__unittest_throw_exception__"
,
[]
{
PADDLE_THROW
(
"test exception"
);
});
m
->
def
(
"__unittest_throw_exception__"
,
[]
{
PADDLE_THROW
(
"test exception"
);
});
}
}
// namespace pybind
...
...
paddle/fluid/pybind/exception.h
浏览文件 @
9eaf4458
...
...
@@ -11,14 +11,17 @@ distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <Python.h>
#include "paddle/fluid/platform/enforce.h"
#include "pybind11/pybind11.h"
namespace
paddle
{
namespace
pybind
{
extern
void
BindException
(
pybind11
::
module
&
m
);
void
BindException
(
pybind11
::
module
*
m
);
}
// namespace pybind
}
// namespace paddle
paddle/fluid/pybind/protobuf.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/protobuf.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/pybind.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/recordio.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/recordio.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/tensor_py.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/pybind/tensor_py_test.cc
0 → 100644
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/chunk.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/chunk.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/chunk_test.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/header.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/header_test.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/scanner.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/scanner.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/writer.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/writer.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/recordio/writer_scanner_test.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/string/.clang-format
已删除
120000 → 0
浏览文件 @
f132f51e
此差异已折叠。
点击以展开。
paddle/fluid/string/piece.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/string/printf.h
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/string/printf_test.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/fluid/string/to_string_test.cc
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/gserver/tests/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/gserver/tests/test_Upsample.cpp
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/trainer/tests/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
paddle/utils/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
proto/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/__init__.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/distribute_transpiler.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/distributed_spliter.py
→
python/paddle/fluid/distributed_split
t
er.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/framework.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/layers/io.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/parallel_executor.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_conv2d_op.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_lookup_table_op.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_parallel_executor.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_prior_box_op.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_recordio_reader.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_sgd_op.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/fluid/tests/unittests/test_softmax_op.py
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/trainer_config_helpers/tests/CMakeLists.txt
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/paddle/trainer_config_helpers/tests/configs/generate_protostr.sh
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
python/setup.py.in
浏览文件 @
9eaf4458
此差异已折叠。
点击以展开。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}