Merge remote-tracking branch 'upstream/develop' into img_separable_conv
Showing
文件已移动
doc/design/fluid-compiler.graffle
0 → 100644
文件已添加
doc/design/fluid-compiler.png
0 → 100644
{kind=link}
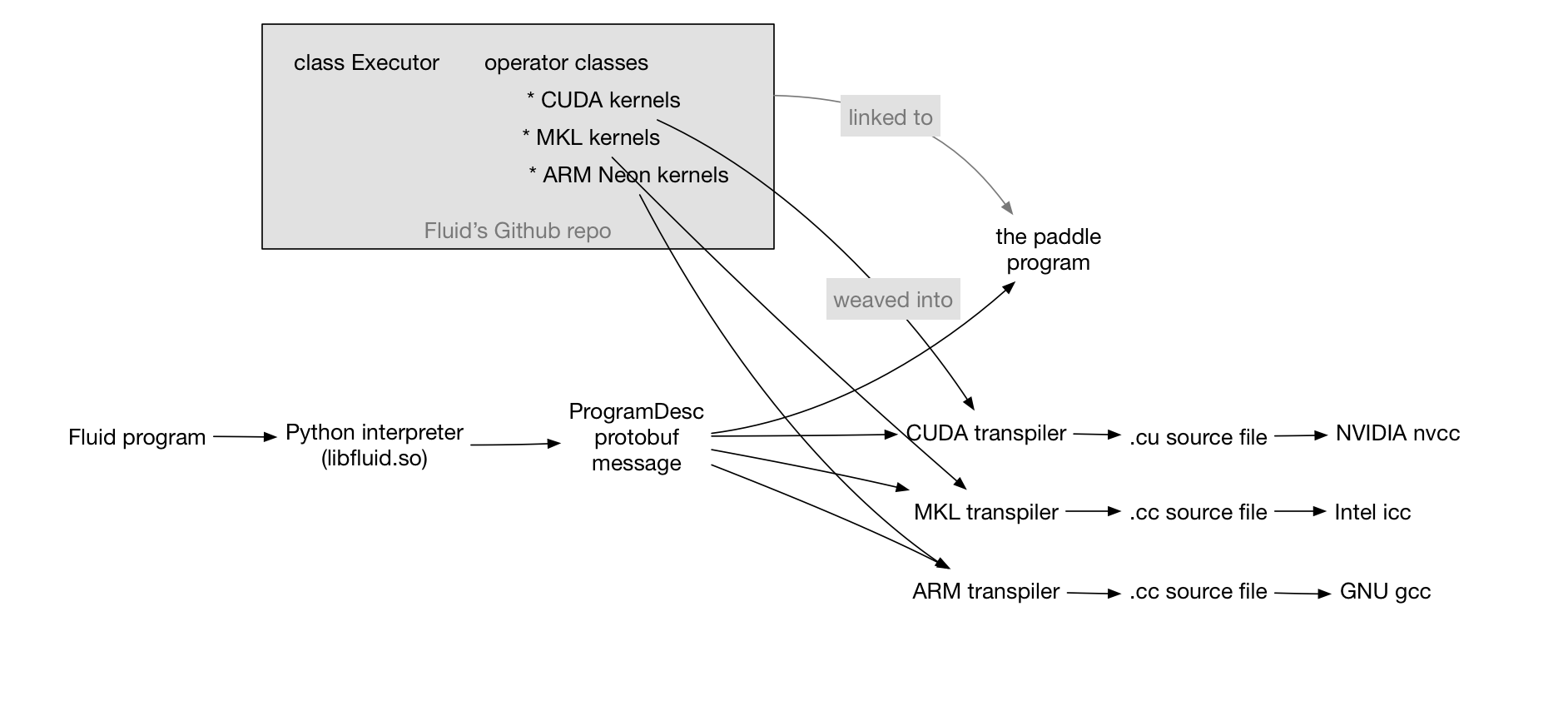
121.2 KB
doc/design/fluid.md
0 → 100644
文件已添加
{kind=link}
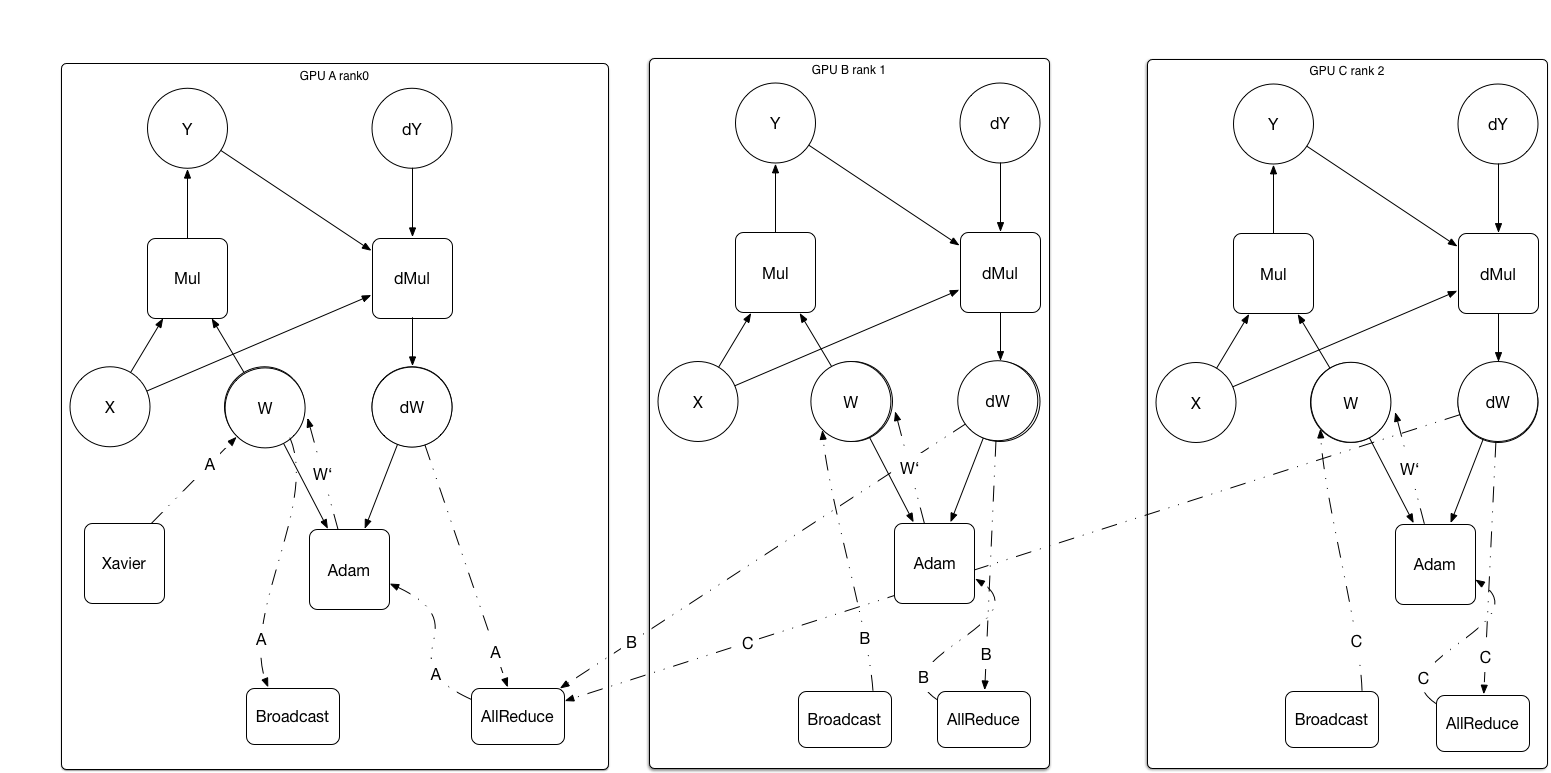
108.4 KB
文件已添加
{kind=link}
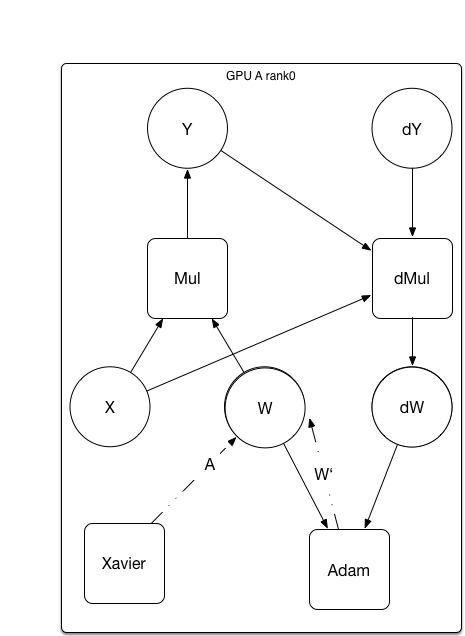
32.8 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
doc/design/mkl/mkl_packed.md
0 → 100644
doc/design/paddle_nccl.md
0 → 100644
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
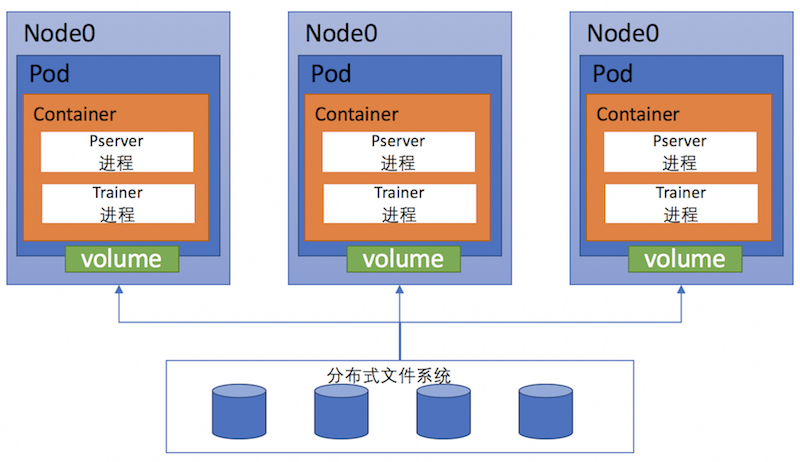
420.9 KB
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
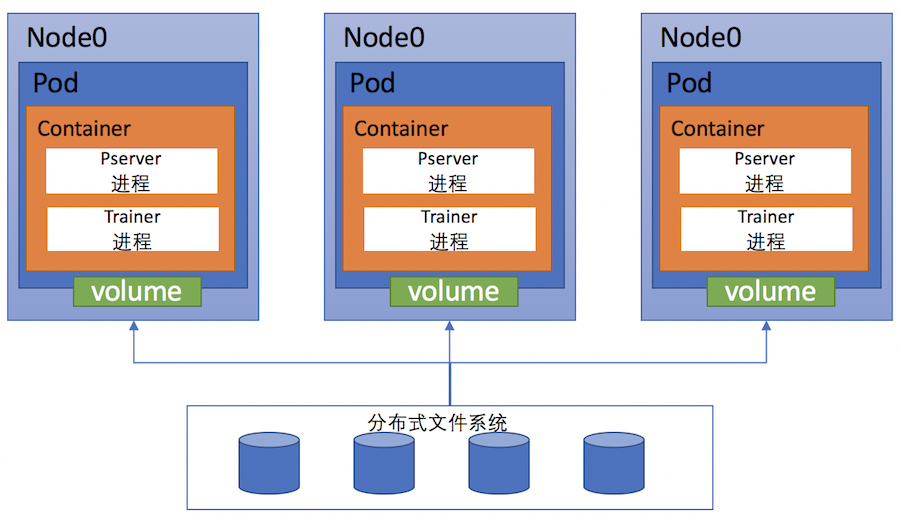
501.1 KB
paddle/framework/init.cc
0 → 100644
paddle/framework/init.h
0 → 100644
paddle/framework/init_test.cc
0 → 100644
paddle/operators/spp_op.cc
0 → 100644
paddle/operators/spp_op.cu.cc
0 → 100644
paddle/operators/spp_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。