remove duplicated doc/tutorials, and rename tutorials to v1_api_tutorials
Showing
{kind=link}

455.6 KB
{kind=link}
51.4 KB
{kind=link}
48.7 KB
{kind=link}
30.3 KB
{kind=link}

455.6 KB
{kind=link}
51.4 KB
{kind=link}
48.7 KB
{kind=link}
30.3 KB
doc/tutorials/index_cn.md
已删除
100644 → 0
doc/tutorials/index_en.md
已删除
100644 → 0
{kind=link}
81.2 KB
{kind=link}
30.5 KB
{kind=link}
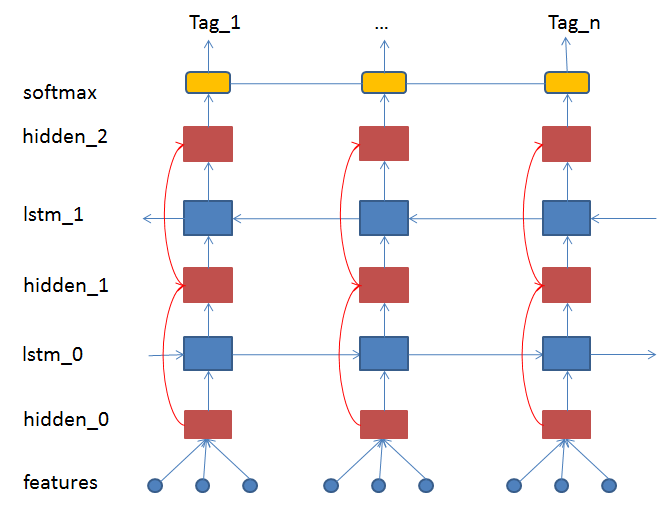
27.2 KB
{kind=link}
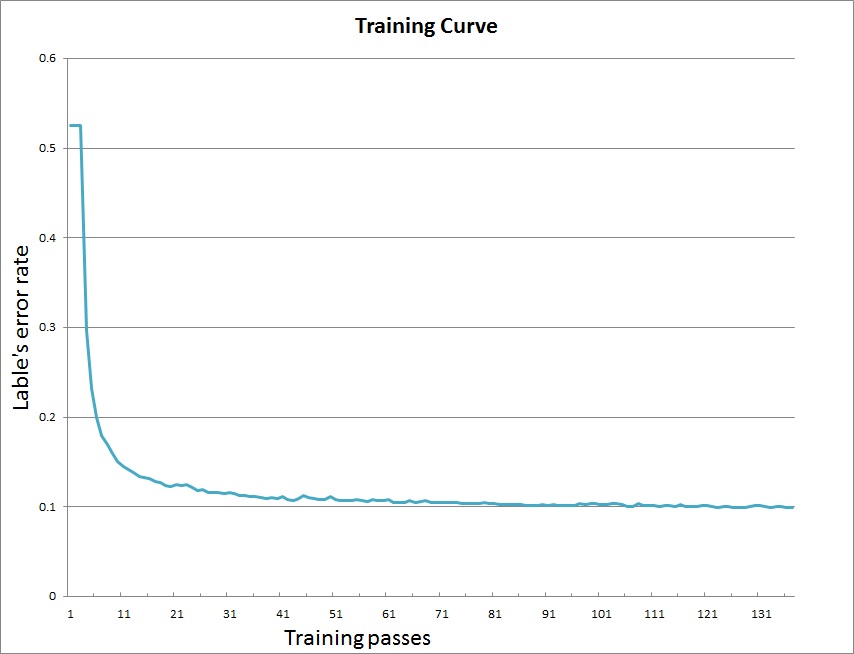
52.0 KB
{kind=link}
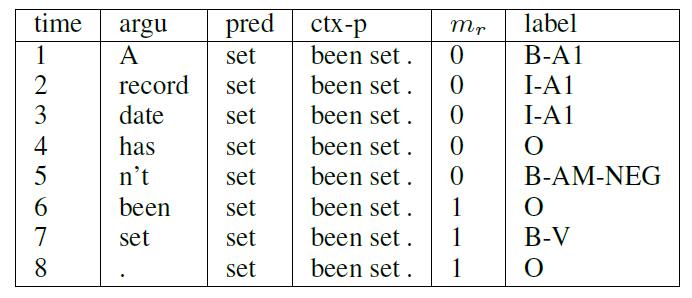
30.5 KB
{kind=link}
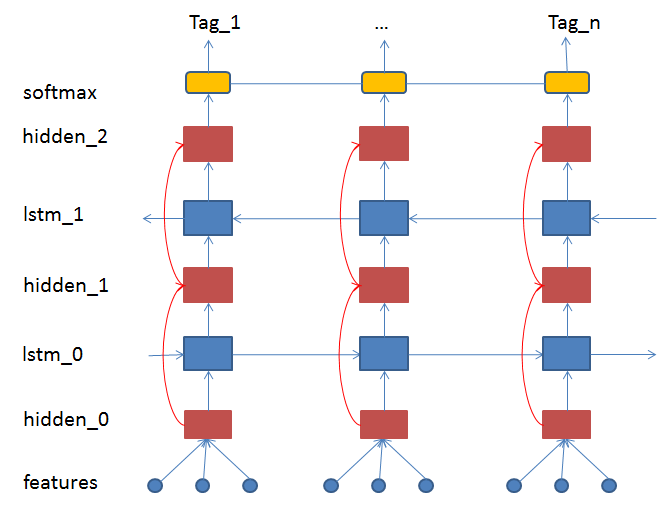
27.2 KB
{kind=link}
34.8 KB
{kind=link}
49.5 KB
{kind=link}
34.8 KB
{kind=link}
49.5 KB
{kind=link}
30.3 KB
{kind=link}
30.3 KB
{kind=link}
66.5 KB
doc/v1_api_tutorials/README.md
0 → 100644
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}