Convert bounding box annotated files to VOC-like dataset
Showing
{kind=link}
{kind=link}
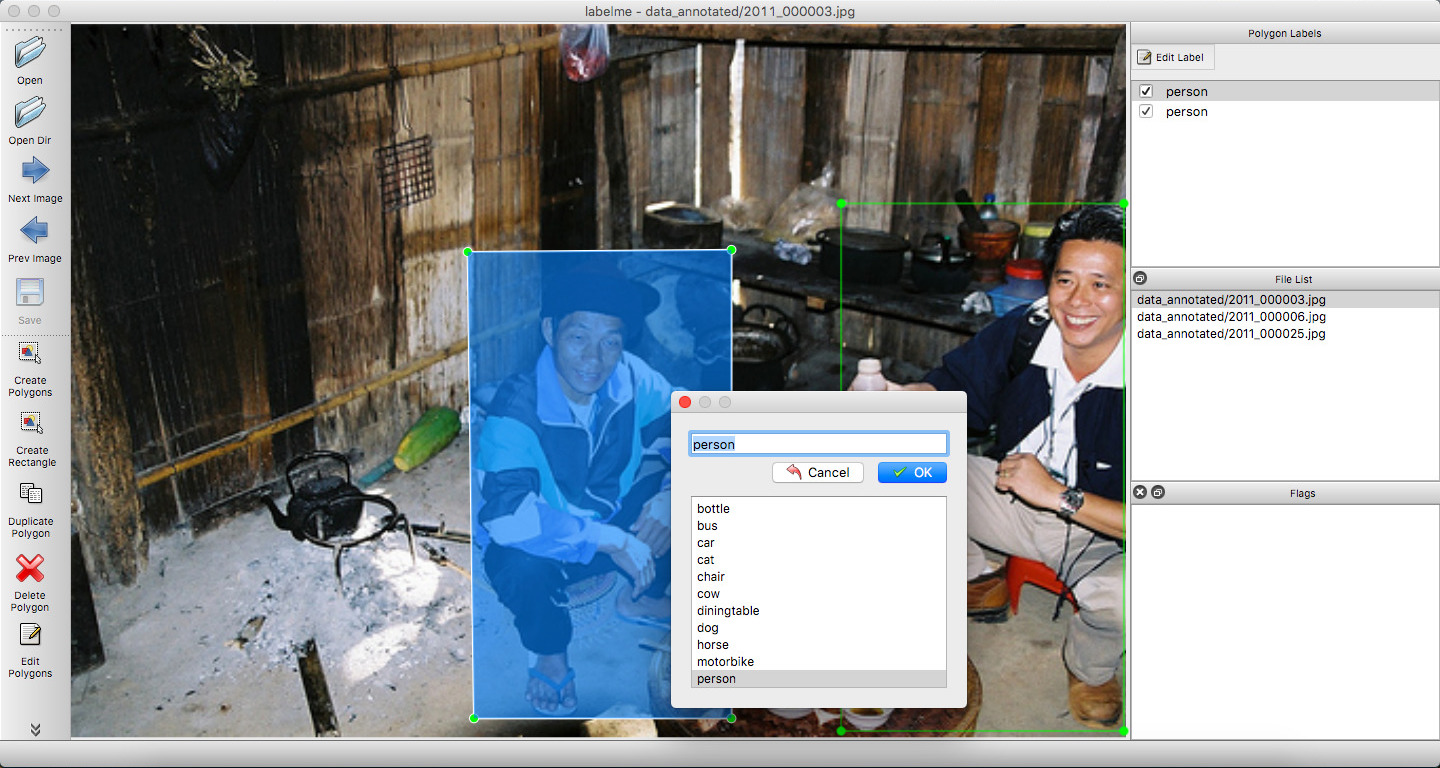
| W: | H:

| W: | H:
{kind=link}

46.1 KB
{kind=link}

30.6 KB
{kind=link}

45.8 KB
{kind=link}

45.4 KB
{kind=link}

28.6 KB
{kind=link}

43.9 KB
从无法访问的项目Fork
| W: | H:
| W: | H:
46.1 KB
30.6 KB
45.8 KB
45.4 KB
28.6 KB
43.9 KB