Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
ShawnGoethe
Understand Nodejs
提交
ecce6e9d
U
Understand Nodejs
项目概览
ShawnGoethe
/
Understand Nodejs
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
U
Understand Nodejs
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
未验证
提交
ecce6e9d
编写于
9月 20, 2020
作者:
T
theanarkh
提交者:
GitHub
9月 20, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update chapter01 nodejs组成和原理.md
上级
40d71c04
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
135 addition
and
0 deletion
+135
-0
chapter01 nodejs组成和原理.md
chapter01 nodejs组成和原理.md
+135
-0
未找到文件。
chapter01 nodejs组成和原理.md
浏览文件 @
ecce6e9d
...
...
@@ -474,3 +474,138 @@ require('internal/modules/cjs/loader').Module.runMain(process.argv[1]);
internal/modules/cjs/loader.js是负责加载用户js的模块,runMain函数在pre_execution.js被挂载。runMain做的事情是加载用户的js,然后执行。具体的过程在后面章节详细分析。
### 1.3.4 进入libuv事件循环
执行完所有的初始化后,nodejs执行了用户的js,用户的js会往libuv注册一些任务,比如创建一个服务器,最后nodejs进入libuv的事件循环中,开始一轮又一轮的事件循环处理。如果没有需要处理的任务,libuv会退出。从而nodejs退出。
## 1.4 nodejs和其他服务器的比较
服务器是现代软件中非常重要的一个组成。我们看服务器的设计模式都有哪些。首先我们先来了解,什么是服务器。顾名思义,服务器,重点是提供服务。那么既然提供服务,那就要为众人所知。不然大家怎么能找到服务呢。就像我们想去吃麦当劳一样,那我们首先得知道他在哪里。所以,服务器很重要的一个属性就是发布服务信息,服务信息包括提供的服务和服务地址。这样大家才能知道需要什么服务的时候,去哪里找。对应到计算机中,服务地址就是ip+端口。所以一个如果你想成为一个服务器,那么你就要首先公布你的ip和端口,但是ip和端口不容易记,不利于使用,所以又设计出DNS协议。这样我们就可以使用域名来访问一个服务,DNS服务会根据域名解析出ip。
一个基于tcp协议的服务器,基本的流程如下。
```
cpp
// 拿到一个socket用于监听
var
socketfd
=
socket
();
// 监听本机的地址(ip+端口)
bind
(
socketfd
,
监听地址
)
// 标记该socket是监听型socket
listen
(
socketfd
)
// 阻塞等待请求到来
var
socketForCommunication
=
accept
(
socket
);
```
执行完以上步骤,一个服务器正式开始服务。下面我们看一下基于上面的模型,分析各种各样的处理方法。
## 1 串行处理请求
```
cpp
while
(
1
)
{
var
socketForCommunication
=
accept
(
socket
);
var
data
=
read
(
socketForCommunication
);
handle
(
data
);
write
(
socketForCommunication
,
data
);
}
```
我们看看这种模式的处理过程。假设有n个请求到来。那么socket的结构是。

这时候进程从accept中被唤醒。然后拿到一个新的socket用于通信。
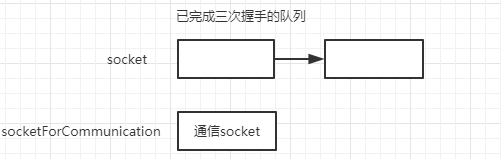
这种模式就是从已完成三次握手的队列里摘下一个节点,然后处理。再摘下一个节点,再处理。如果处理的过程中有文件io,可想而知,效率是有多低。而且大并发的时候,socket对应的队列很快就不被占满。这是最简单的模式,虽然服务器的设计中肯定不会使用这种模式,但是他让我们了解了一个服务器处理请求的过程。
## 2 多进程模式
多进程式下又分为几种。
2.
1 一个请求一个进程
```
cpp
while
(
1
)
{
var
socketForCommunication
=
accept
(
socket
);
if
(
fork
()
>
0
)
{
// 父进程负责accept
}
else
{
// 子进程
handle
(
socketForCommunication
);
}
}
```
这种模式下,每次来一个请求,就会新建一个进程去处理他。这种模式比串行的稍微好了一点,每个请求独立处理,假设a请求阻塞在文件io,那么不会影响b请求的处理,尽可能地做到了并发。他的瓶颈就是系统的进程数有限,大量的请求,系统无法扛得住。再者,进程的开销很大。对于系统来说是一个沉重的负担。
2.
2 多进程accept
这种模式不是等到请求来的时候再创建进程。而是在服务器启动的时候,就会创建一个多个进程。然后多个进程分别调用accept。这种模式的架构如下。

```
cpp
for
(
let
i
=
0
;
i
<
进程个数
;
i
++
)
{
if
(
fork
()
>
0
)
{
// 父进程负责监控子进程
}
else
{
// 子进程处理请求
while
(
1
)
{
var
socketForCommunication
=
accept
(
socket
);
handle
(
socketForCommunication
);
}
}
}
```
这种模式下多个子进程都阻塞在accept。如果这时候有一个请求到来,那么所有的子进程都会被唤醒,但是首先被调度的子进程会首先摘下这个请求节点。后续的进程被唤醒后发现并没有请求可以处理。又进入睡眠。这是著名的惊群现象。改进方式就是在accpet之前加锁,拿到锁之后才能进行accept。nginx就解决了这个问题。但是据说现代操作系统已经在内核层面解决了这个问题。
2.
3 进程池模式
进程池模式就是服务器创建的时候,创建一定数量的进程,但是这些进程是worker进程。他不负责accept请求。他只负责处理请求。主进程负责accept,他把accept返回的socket放到一个任务队列中。worker进程互斥访问任务队列从中取出请求进行处理。主进程的模式如下
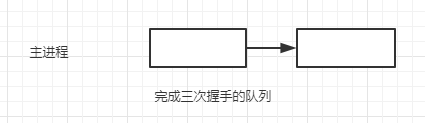
子进程的模式如下

逻辑如下
```
cpp
for
(
let
i
=
0
;
i
<
进程个数
;
i
++
)
{
if
(
fork
()
>
0
)
{
// 父进程
}
else
{
// 子进程处理请求
while
(
1
)
{
// 互斥从队列中获取任务节点
var
task
=
getTask
(
queue
);
handle
(
task
);
}
}
}
for
(;;)
{
var
newSocket
=
accept
(
socket
);
insertTask
(
queue
);
}
```
多进程的模式同样适合多线程。
## 3 事件驱动
现在很多服务器(nginx,nodejs)都开始使用事件驱动模式去设计。从2的设计模式中我们知道,为了应对大量的请求,服务器需要大量的进程/线程。这个是个非常大的开销。而事件驱动模式,一般是配合单进程(单线程),再多的请求,也是在一个进程里处理的。但是因为是单进程,所以不适合cpu密集型,因为一个任务一直在占据cpu的话,后续的任务就无法执行了。他更适合io密集的。而使用多进程/线程的时候,一个进程/线程是无法一直占据cpu的,执行一定时间后,操作系统会执行进程/线程调度。这样就不会出现饥饿情况。事件驱动在不同系统中实现不一样。所以一般都会有一层抽象层抹平这个差异。这里以linux的epoll为例子。
```
cpp
// 创建一个epoll
var
epollFD
=
epoll_create
();
/*
在epoll给某个文件描述符注册感兴趣的事件,这里是监听的socket,注册可读事件,即连接到来
event = {
event: 可读
fd: 监听socket
// 一些上下文
}
*/
epoll_ctl
(
epollFD
,
EPOLL_CTL_ADD
,
socket
,
event
);
while
(
1
)
{
// 阻塞等待事件就绪,events保存就绪事件的信息,total是个数
var
total
=
epoll_wait
(
epollFD
,
保存就绪事件的结构
events
,
事件个数
,
timeout
);
for
(
let
i
=
0
;
i
<
total
;
i
++
)
{
if
(
events
[
i
].
fd
===
socket
)
{
var
newSocket
=
accpet
(
socket
);
// 把新的socket也注册到epoll,等待可读,即可读取客户端数据
epoll_ctl
(
epollFD
,
EPOLL_CTL_ADD
,
newSocket
,
可读事件
);
}
else
{
// 从events[i]中拿到一些上下文,执行相应的回调
}
}
}
```
这就是事件驱动模式的大致过程。本质上是一个订阅/发布模式。服务器通过注册文件描述符和事件到epoll中。等待epoll的返回,epoll返回的时候会告诉服务器哪些事件就绪了。这时候服务器遍历就绪事件,然后执行对应的回调,在回调里可以再次注册新的事件。就是这样不断驱动着。epoll的原理其实也类似事件驱动。epoll底层维护用户注册的事件和文件描述符。epoll本身也会在文件描述符对应的文件/socket/管道处注册一个回调。然后自身进入阻塞。等到别人通知epoll有事件就绪的时候,epoll就会把就绪的事件返回给用户。
```
cpp
function
epoll_wait
()
{
for
事件个数
// 调用文件系统的函数判断
if
(
事件
[
i
]
中对应的文件描述符中有某个用户感兴趣的事件发生
?
)
{
插入就绪事件队列
}
else
{
在事件
[
i
]
中的文件描述符所对应的文件
/
socket
/
管道等
indeo
节点注册回调。即感兴趣的事件触发后回调
epoll
,回调
epoll
后,
epoll
把该
event
[
i
]
插入就绪事件队列返回给用户
}
}
```
以上就是服务器设计的一些基本介绍。现在的服务器还会涉及到协程。不过目前自己还没有看过具体的实现,所以还无法介绍。nodejs是基于单进程(单线程)的事件驱动模式。即epoll模式。这也是为什么nodejs擅长处理高并发io型任务而不擅长处理cpu型任务的原因。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录