In Neural Network, the backpropagation algorithm follows the chain rule, so we need to compound the gradient operators/expressions together with the chain rule. Every forward network needs a backward network to construct the full computation graph, the operator/expression's backward pass will be generated respect to forward pass.
In Neural Network, many model is solved by the the backpropagation algorithm(known as BP) at present. Technically it caculates the gradient of the loss function, then distributed back through the networks. Follows the chain rule, so we need a module chains the gradient operators/expressions together with to construct the backward pass. Every forward network needs a backward network to construct the full computation graph, the operator/expression's backward pass will be generated respect to forward pass.
## Backward Operator Registry
## Implementation
A backward network is built up with several backward operators. Backward operators take forward operators' inputs outputs, and output gradients and then calculate its input gradients.
In this design doc, we exported only one API for generating the backward pass.
The implementation behind it can be divided into two parts, **Backward Operator Creating** and **Backward Operator Building**.
### Backward Operator Registry
A backward network is built up with several backward operators. Backward operators take forward operators' inputs, outputs, and output gradients and then calculate its input gradients.
`mul_grad` is the type of backward operator, and `MulOpGrad` is its class name.
`mul_grad` is the type of backward operator, and `MulOpGrad` is its class name.
## Backward Opeartor Creating
### Backward Opeartor Creating
Given a certain forward operator, we can get its corresponding backward operator by calling:
Given a certain forward operator, we can get its corresponding backward operator by calling:
...
@@ -43,40 +54,47 @@ The function `BuildGradOp` will sequentially execute following processes:
...
@@ -43,40 +54,47 @@ The function `BuildGradOp` will sequentially execute following processes:
4. Building backward operator with `inputs`, `outputs` and forward operator's attributes.
4. Building backward operator with `inputs`, `outputs` and forward operator's attributes.
## Backward Network Building
### Backward Network Building
A backward network is a series of backward operators. The main idea of building a backward network is creating backward operators in the inverted sequence and put them together.
In our design, the network itself is also a kind of operator. So the operators contained by a big network may be some small network.
A backward network is a series of backward operators. The main idea of building a backward network is creating backward operators in the inverted sequence and append them together one by one. There is some corner case need to process specially.
given a forward network, it generates the backward network. We only care about the Gradients—`OutputGradients`, `InputGradients`.
1. Op
1. Op
when the input forward network is an Op, return its gradient Operator Immediately.
When the input forward network is an Op, return its gradient Operator Immediately. If all of its outputs are in no gradient set, then return a special `NOP`.
2. NetOp
2. NetOp
when the input forward network is a NetOp, it needs to call the sub NetOp/Operators backward function recursively. During the process, we need to collect the `OutputGradients` name according to the forward NetOp.
In our design, the network itself is also a kind of operator(**NetOp**). So the operators contained by a big network may be some small network. When the input forward network is a NetOp, it needs to call the sub NetOp/Operators backward function recursively. During the process, we need to collect the `OutputGradients` name according to the forward NetOp.
3. RnnOp
RnnOp is a nested stepnet operator. Backward module need to recusively call `Backward` for every stepnet.
4. Sharing Variables
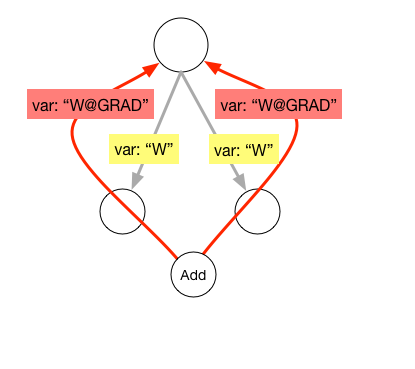
**sharing variables**. As illustrated in the pictures, two operator's share the same variable name of W@GRAD, which will overwrite their sharing input variable.
Sharing variable between operators or same input variable used in multiple operators leads to a duplicate gradient variable. As demo show above, we need to rename gradient name recursively and add a generic add operator to replace the overwrite links.
Share variable between operators or same input variable used in multiple operators leads to a duplicate gradient variable. As demo show above, we need to rename gradient name recursively and add a generic add operator replace the overwrite links.
pic 2. Replace sharing variable's gradient with `Add` operator.
2. Replace shared variable's gradient with `Add` operator.
Because our framework finds variables accord to their names, we need to rename the output links. We add a suffix of number to represent its position in clockwise.
</p>
5. Part of Gradient is Zero.
In the whole graph, there is some case of that one operator's gradient is not needed, but its input's gradient is a dependency link of other operator, we need to fill a same shape gradient matrix in the position. In our implement, we insert a special `fillZeroLike` operator.
Then collect the sub graph `OutputGradients`/`InputGradients` as the NetOp's and return it.
Follow these rules above, then collect the sub graph `OutputGradients`/`InputGradients` as the NetOp's and return it.
To make the operator document itself more clear, we recommend operator names obey the listing conventions.
### OpProtoMaker names
When defining an operator in Paddle, a corresponding [OpProtoMaker](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/framework/operator.h#L170)(TODO: OpProtoMaker Doc)need to be defined. All the Input/Output and Attributes will write into the [OpProto](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/framework/framework.proto#L61) , and will be used in client language to create operator.
- Input/Output.
- Input/Output names follow the **CamelCase**. e.g. `X`, `Y`, `Matrix`, `LastAxisInMatrix`. Input/Output much more like Variables, we prefer to meaningful English words.
- If an operator's Input/Output are tensors in math, not match to any meaningful words, input name should starts from `X`. e.g. `X`, `Y`, and output name should starts from `Out`. e.g. `Out`. This rule intends making operators which have few inputs/outputs unified.
- Attribute.
- Attribute name follows the **camelCase**. e.g. `x`, `y`, `axis`, `rowwiseMatrix`. Also, attribute name prefers to meaningful English words.
- Comments.
- Input/Output/Attr comment follow the format of **(type,default value) usage**, corresponding to which type it can be and how it will be used in the operator. e.g. Attribute in Accumulator`"gamma" `,`(float, default 1.0) Accumulation multiplier`.
- Operator comment format of` R"DOC(your comment here)DOC"`. You should explain the input/output of the operator first. If there is math calculation in this operator, you should write the equation in the comment. e.g. `Out = X + Y`.
- Order.
- Follow the order of Input/Output, then Attribute, then Comments. See the example in best practice.
### Best Practice
Here we give some examples to show how these rules will be used.
- The operator has one input, one output. e.g.`relu`, inputs: `X`, outputs: `Out`.
- The operator has two input, one output. e.g. `rowwise_add`, inputs : `X`, `Y`, outputs : `Out`.
- The operator contains attribute. e.g. `cosine`, inputs : `X`, `axis`, outputs : `Out`.
AddInput("X","(Tensor) The input tensor that has to be accumulated to the output tensor. If the output size is not the same as input size, the output tensor is first reshaped and initialized to zero, and only then, accumulation is done.");
{kind=link}
{kind=link}