Merge remote-tracking branch 'origin/develop' into op_name
Showing
.clang_format.hook
0 → 100755
doc/about/index_cn.md
已删除
100644 → 0
doc/about/index_en.rst
已删除
100644 → 0
{kind=link}
{kind=link}

| W: | H:
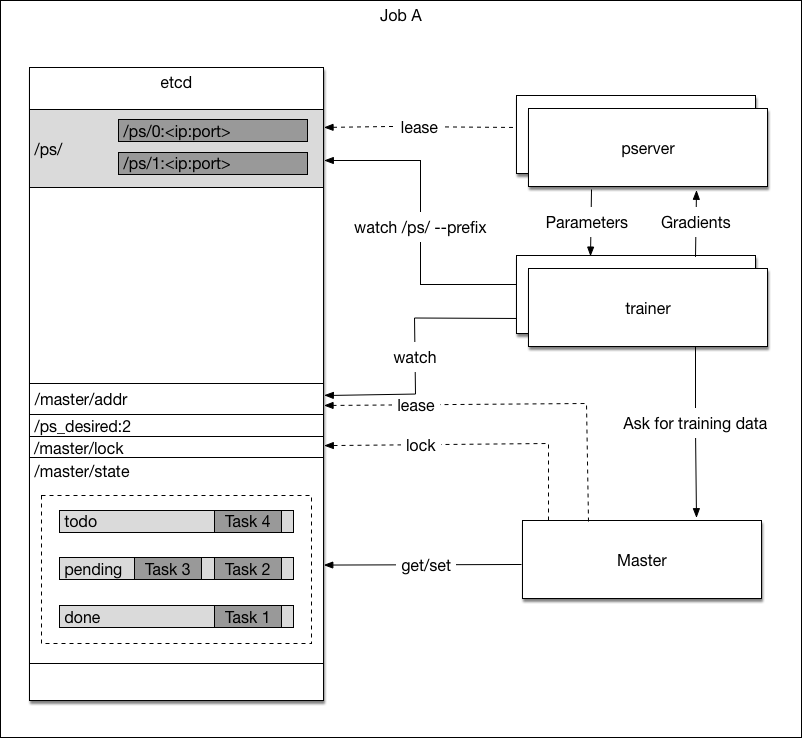
| W: | H:
doc/design/graph.md
0 → 100644
doc/design/if_else_op.md
0 → 100644
{kind=link}

58.3 KB
{kind=link}

50.2 KB
{kind=link}
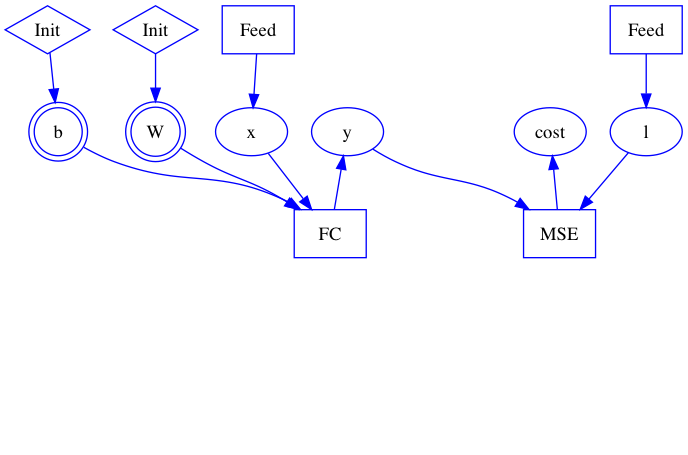
31.5 KB
doc/design/ops/dist_train.md
0 → 100644
文件已添加
doc/design/ops/src/dist-graph.png
0 → 100644
{kind=link}

222.2 KB
文件已添加
{kind=link}

27.9 KB
doc/design/var_desc.md
0 → 100644
doc/howto/dev/build_cn.md
0 → 100644
doc/howto/dev/build_en.md
0 → 100644
doc/howto/dev/new_op_cn.md
0 → 100644
doc/howto/dev/use_eigen_cn.md
0 → 100644
paddle/capi/export.map
0 → 100644
paddle/capi/export.sym
0 → 100644
paddle/framework/framework.proto
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}
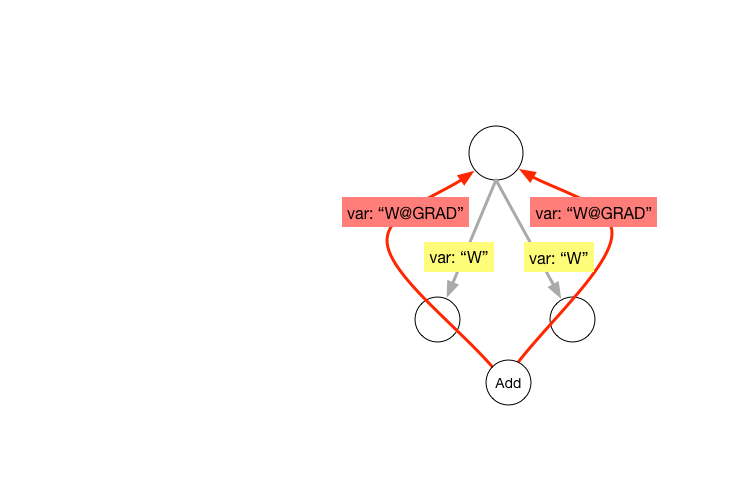
| W: | H:

| W: | H:
paddle/framework/lod_tensor.md
0 → 100644
此差异已折叠。
paddle/framework/op_info.cc
0 → 100644
此差异已折叠。
paddle/framework/op_info.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/function/EigenGemm.cpp
0 → 100644
此差异已折叠。
paddle/function/GemmFunctor.cpp
0 → 100644
此差异已折叠。
paddle/function/GruFunctor.h
0 → 100644
此差异已折叠。
paddle/function/SwitchOp.cpp
0 → 100644
此差异已折叠。
paddle/function/SwitchOp.h
0 → 100644
此差异已折叠。
paddle/function/SwitchOpGpu.cu
0 → 100644
此差异已折叠。
paddle/function/SwitchOpTest.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/MKLDNNMatrix.cpp
0 → 100644
此差异已折叠。
paddle/math/MKLDNNMatrix.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/concat_op.cc
0 → 100644
此差异已折叠。
paddle/operators/concat_op.cu
0 → 100644
此差异已折叠。
paddle/operators/concat_op.h
0 → 100644
此差异已折叠。
paddle/operators/cos_sim_op.cc
0 → 100644
此差异已折叠。
paddle/operators/cos_sim_op.cu
0 → 100644
此差异已折叠。
paddle/operators/cos_sim_op.h
0 → 100644
此差异已折叠。
paddle/operators/gather_op.cc
0 → 100644
此差异已折叠。
paddle/operators/gather_op.h
0 → 100644
此差异已折叠。
paddle/operators/identity_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/im2col.cc
0 → 100644
此差异已折叠。
paddle/operators/math/im2col.cu
0 → 100644
此差异已折叠。
paddle/operators/math/im2col.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/minus_op.cc
0 → 100644
此差异已折叠。
paddle/operators/minus_op.cu
0 → 100644
此差异已折叠。
paddle/operators/minus_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/scale_op.cc
0 → 100644
此差异已折叠。
paddle/operators/scale_op.cu
0 → 100644
此差异已折叠。
paddle/operators/scale_op.h
0 → 100644
此差异已折叠。
paddle/operators/scatter.h
0 → 100644
此差异已折叠。
paddle/operators/scatter_op.cc
0 → 100644
此差异已折叠。
paddle/operators/scatter_op.h
0 → 100644
此差异已折叠。
paddle/operators/scatter_test.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/sum_op.cc
0 → 100644
此差异已折叠。
paddle/operators/sum_op.cu
0 → 100644
此差异已折叠。
paddle/operators/sum_op.h
0 → 100644
此差异已折叠。
paddle/operators/top_k_op.cc
0 → 100644
此差异已折叠。
paddle/operators/top_k_op.cu
0 → 100644
此差异已折叠。
paddle/operators/top_k_op.h
0 → 100644
此差异已折叠。
paddle/platform/cuda_helper.h
0 → 100644
此差异已折叠。
paddle/platform/cudnn_helper.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/platform/environment.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/pybind/CMakeLists.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/trainer/recurrent_units.py
100755 → 100644
文件模式从 100755 更改为 100644
python/paddle/trainer_config_helpers/layers.py
100755 → 100644
此差异已折叠。
python/paddle/trainer_config_helpers/networks.py
100755 → 100644
文件模式从 100755 更改为 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。