remove conflict
Showing
adversarial/README.md
已删除
100644 → 0
doc/howto/dev/new_op_kernel_en.md
0 → 100644
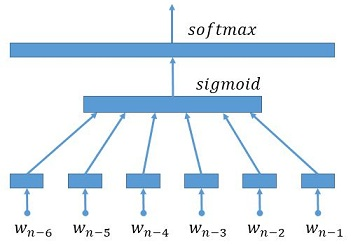
66.9 KB
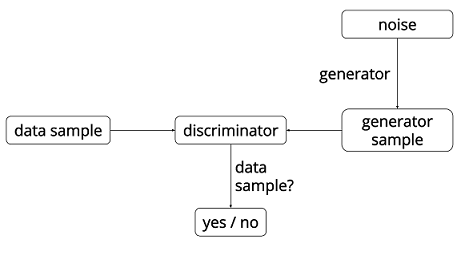
17.4 KB
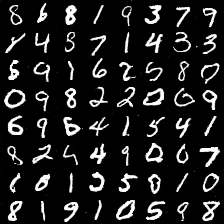
28.0 KB
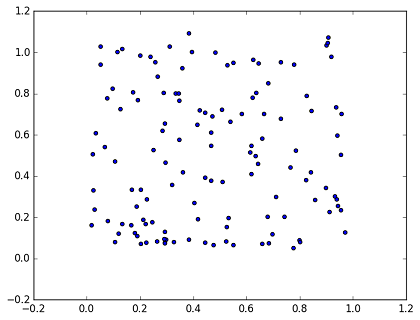
24.3 KB
21.9 KB
此差异已折叠。

35.0 KB

53.0 KB

43.0 KB

57.7 KB

29.6 KB

48.3 KB

45.3 KB

55.8 KB


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

9.2 KB
{kind=link}

8.5 KB
{kind=link}

9.0 KB
{kind=link}

8.6 KB
{kind=link}

13.9 KB
{kind=link}

11.4 KB
paddle/operators/ctc_align_op.cc
0 → 100644
paddle/operators/ctc_align_op.cu
0 → 100644
paddle/operators/ctc_align_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。