init branch
上级
Showing
AUTHORS.md
0 → 100644
CMakeLists.txt
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CODE_OF_CONDUCT_cn.md
0 → 100644
CONTRIBUTING.md
0 → 100644
Dockerfile
0 → 100644
ISSUE_TEMPLATE.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_cn.md
0 → 100644
RELEASE.md
0 → 100644
benchmark/.gitignore
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
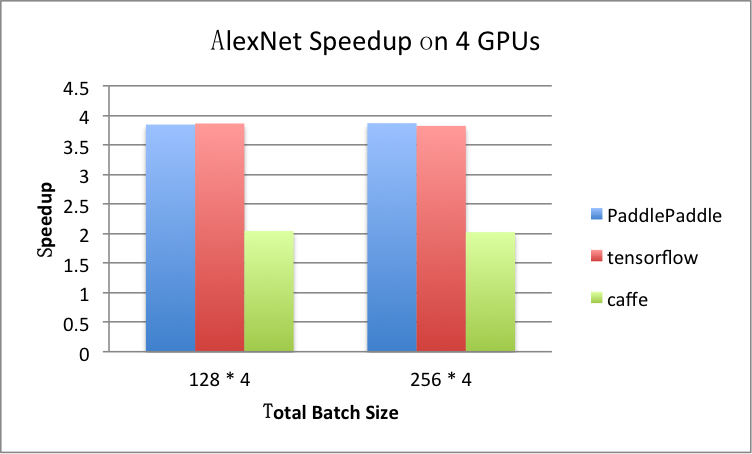
81.8 KB
{kind=link}
15.1 KB
{kind=link}
15.6 KB
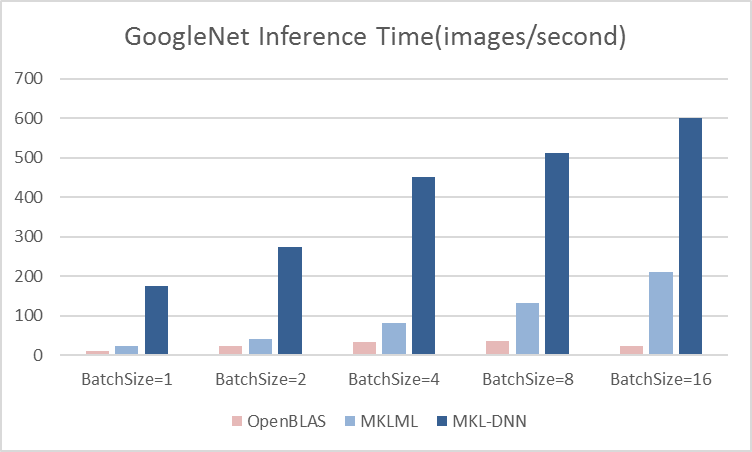
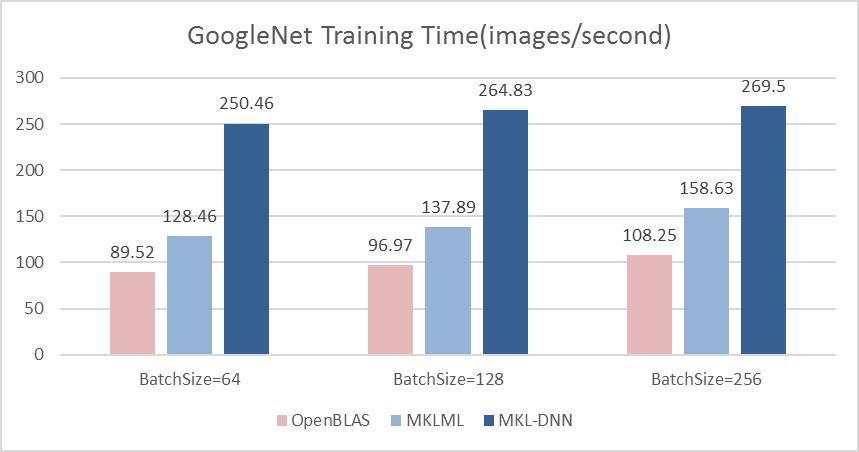
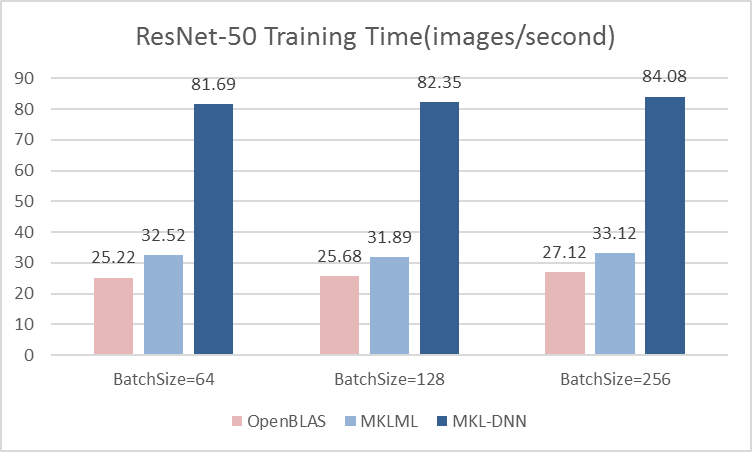
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}
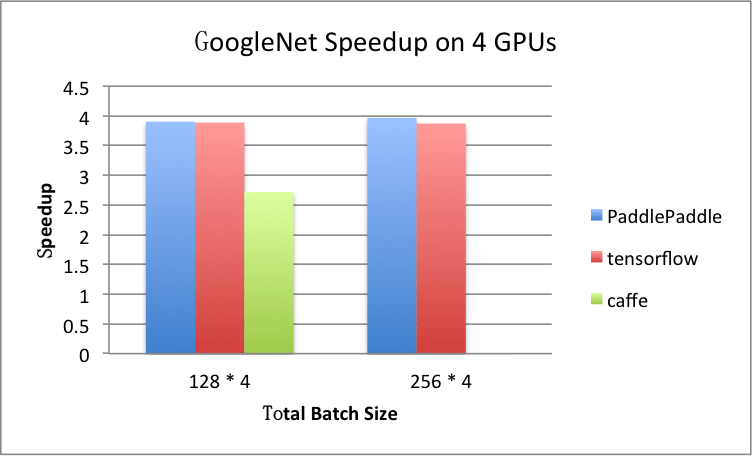
81.8 KB
{kind=link}
14.1 KB
{kind=link}
18.8 KB
{kind=link}

13.7 KB
{kind=link}
17.6 KB
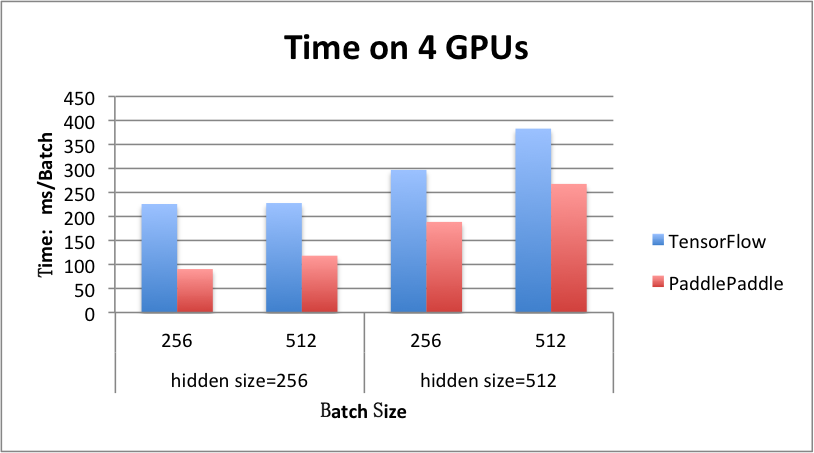
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}
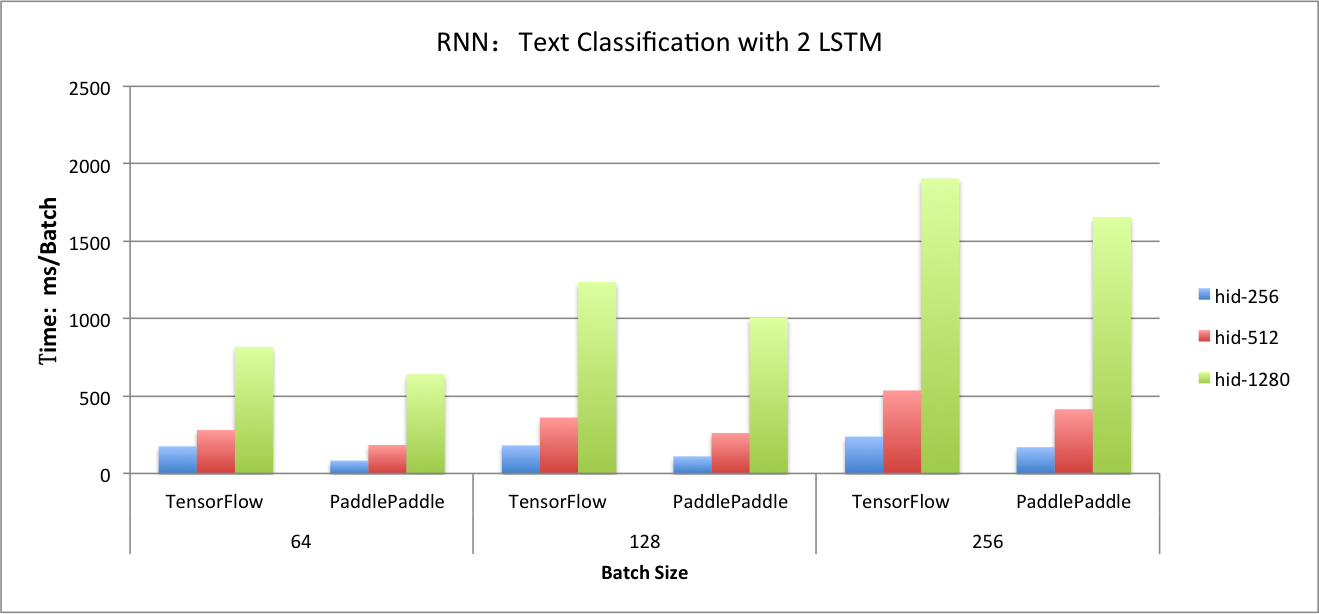
114.9 KB
benchmark/figs/vgg-cpu-infer.png
0 → 100644
{kind=link}
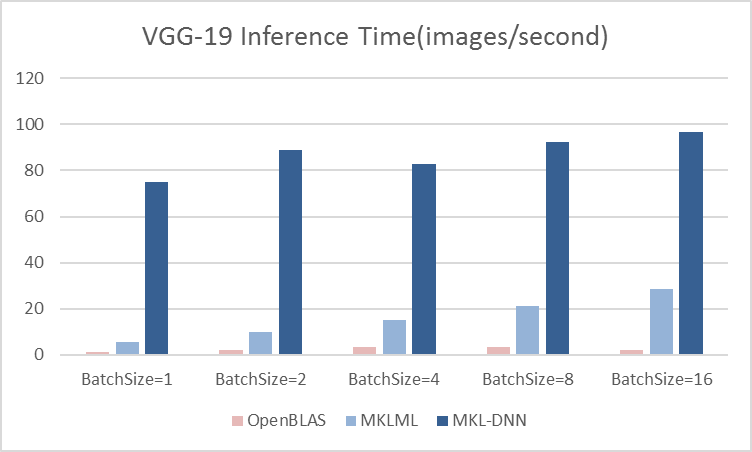
13.7 KB
benchmark/figs/vgg-cpu-train.png
0 → 100644
{kind=link}
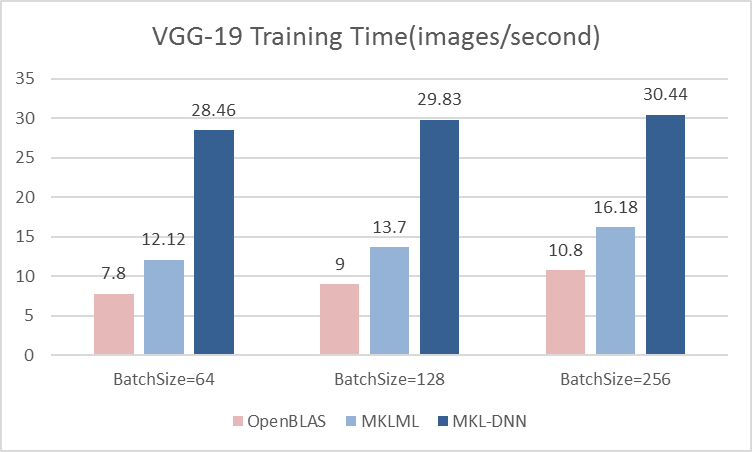
16.7 KB
benchmark/fluid/Dockerfile
0 → 100644
benchmark/fluid/README.md
0 → 100644
benchmark/fluid/args.py
0 → 100644
benchmark/fluid/check_env.sh
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/fluid/kube_gen_job.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/fluid/models/mnist.py
0 → 100644
此差异已折叠。
benchmark/fluid/models/resnet.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/fluid/models/vgg.py
0 → 100644
此差异已折叠。
此差异已折叠。
benchmark/fluid/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/mnist.py
0 → 100644
此差异已折叠。
benchmark/tensorflow/resnet.py
0 → 100644
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/vgg.py
0 → 100644
此差异已折叠。
此差异已折叠。
cmake/CMakeGoCompiler.cmake.in
0 → 100644
此差异已折叠。
cmake/CMakeGoInformation.cmake
0 → 100644
此差异已折叠。
cmake/CMakeTestGoCompiler.cmake
0 → 100644
此差异已折叠。
cmake/FindGflags.cmake
0 → 100644
此差异已折叠。
cmake/FindGlog.cmake
0 → 100644
此差异已折叠。
cmake/FindGperftools.cmake
0 → 100644
此差异已折叠。
cmake/FindJeMalloc.cmake
0 → 100644
此差异已折叠。
cmake/FindNumPy.cmake
0 → 100644
此差异已折叠。
cmake/anakin_subgraph.cmake
0 → 100644
此差异已折叠。
cmake/cblas.cmake
0 → 100644
此差异已折叠。
cmake/ccache.cmake
0 → 100644
此差异已折叠。
cmake/configure.cmake
0 → 100644
此差异已折叠。
cmake/coveralls.cmake
0 → 100644
此差异已折叠。
cmake/coverallsGcovJsons.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
cmake/cross_compiling/host.cmake
0 → 100644
此差异已折叠。
cmake/cuda.cmake
0 → 100644
此差异已折叠。
cmake/cudnn.cmake
0 → 100644
此差异已折叠。
cmake/cupti.cmake
0 → 100644
此差异已折叠。
cmake/external/anakin.cmake
0 → 100644
此差异已折叠。
cmake/external/boost.cmake
0 → 100644
此差异已折叠。
cmake/external/brpc.cmake
0 → 100644
此差异已折叠。
cmake/external/cares.cmake
0 → 100644
此差异已折叠。
cmake/external/cub.cmake
0 → 100644
此差异已折叠。
cmake/external/dgc.cmake
0 → 100644
此差异已折叠。
cmake/external/dlpack.cmake
0 → 100644
此差异已折叠。
cmake/external/eigen.cmake
0 → 100644
此差异已折叠。
cmake/external/gflags.cmake
0 → 100644
此差异已折叠。
cmake/external/glog.cmake
0 → 100644
此差异已折叠。
cmake/external/grpc.cmake
0 → 100644
此差异已折叠。
cmake/external/gtest.cmake
0 → 100644
此差异已折叠。
cmake/external/gzstream.cmake
0 → 100644
此差异已折叠。
cmake/external/leveldb.cmake
0 → 100644
此差异已折叠。
cmake/external/libmct.cmake
0 → 100644
此差异已折叠。
cmake/external/libxsmm.cmake
0 → 100644
此差异已折叠。
cmake/external/mkldnn.cmake
0 → 100644
此差异已折叠。
cmake/external/mklml.cmake
0 → 100644
此差异已折叠。
cmake/external/ngraph.cmake
0 → 100644
此差异已折叠。
cmake/external/openblas.cmake
0 → 100644
此差异已折叠。
cmake/external/protobuf.cmake
0 → 100644
此差异已折叠。
cmake/external/pslib.cmake
0 → 100644
此差异已折叠。
cmake/external/pslib_brpc.cmake
0 → 100644
此差异已折叠。
cmake/external/pybind11.cmake
0 → 100644
此差异已折叠。
cmake/external/python.cmake
0 → 100644
此差异已折叠。
cmake/external/rocprim.cmake
0 → 100644
此差异已折叠。
cmake/external/snappy.cmake
0 → 100644
此差异已折叠。
cmake/external/snappystream.cmake
0 → 100644
此差异已折叠。
cmake/external/threadpool.cmake
0 → 100644
此差异已折叠。
cmake/external/warpctc.cmake
0 → 100644
此差异已折叠。
cmake/external/xbyak.cmake
0 → 100644
此差异已折叠。
cmake/external/xxhash.cmake
0 → 100644
此差异已折叠。
cmake/external/zlib.cmake
0 → 100644
此差异已折叠。
cmake/flags.cmake
0 → 100644
此差异已折叠。
cmake/generic.cmake
0 → 100644
此差异已折叠。
cmake/hip.cmake
0 → 100644
此差异已折叠。
cmake/inference_lib.cmake
0 → 100644
此差异已折叠。
cmake/make_resource.py
0 → 100644
此差异已折叠。
cmake/operators.cmake
0 → 100644
此差异已折叠。
cmake/package.cmake
0 → 100644
此差异已折叠。
cmake/python_module.cmake
0 → 100644
此差异已折叠。
cmake/simd.cmake
0 → 100644
此差异已折叠。
cmake/system.cmake
0 → 100644
此差异已折叠。
cmake/tensorrt.cmake
0 → 100644
此差异已折叠。
cmake/util.cmake
0 → 100644
此差异已折叠。
cmake/version.cmake
0 → 100644
此差异已折叠。
doc/README.md
0 → 100644
此差异已折叠。
go/glide.lock
0 → 100644
此差异已折叠。
go/glide.yaml
0 → 100644
此差异已折叠。
paddle/.common_test_util.sh
0 → 100644
此差异已折叠。
paddle/.gitignore
0 → 100644
此差异已折叠。
paddle/.set_port.sh
0 → 100755
此差异已折叠。
paddle/.set_python_path.sh
0 → 100755
此差异已折叠。
paddle/CMakeLists.txt
0 → 100644
此差异已折叠。
paddle/contrib/float16/.gitignore
0 → 100644
此差异已折叠。
paddle/contrib/float16/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/.clang-format
0 → 100644
此差异已折叠。
paddle/fluid/API.spec
0 → 100644
此差异已折叠。
paddle/fluid/CMakeLists.txt
0 → 100644
此差异已折叠。
paddle/fluid/framework/.gitignore
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/array.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/data_set.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/ddim.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/ddim.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/dim.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/eigen.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/executor.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/io/fs.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/io/fs.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/io/shell.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/ir/graph.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/ir/node.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/ir/node.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/ir/pass.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/ir/pass.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/op_desc.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/op_desc.h
0 → 100644
此差异已折叠。
paddle/fluid/framework/op_info.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/op_info.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/operator.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/prune.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/prune.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/reader.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/reader.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/rw_lock.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/scope.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/scope.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/tensor.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/tensor.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/trainer.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/trainer.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/tuple.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/var_desc.h
0 → 100644
此差异已折叠。
paddle/fluid/framework/var_type.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/variable.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/framework/version.cc
0 → 100644
此差异已折叠。
paddle/fluid/framework/version.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/imperative/README.md
0 → 100644
此差异已折叠。
paddle/fluid/imperative/engine.cc
0 → 100644
此差异已折叠。
paddle/fluid/imperative/engine.h
0 → 100644
此差异已折叠。
paddle/fluid/imperative/layer.cc
0 → 100644
此差异已折叠。
paddle/fluid/imperative/layer.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/imperative/tracer.cc
0 → 100644
此差异已折叠。
paddle/fluid/imperative/tracer.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/inference/api/api.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/inference/engine.h
0 → 100644
此差异已折叠。
paddle/fluid/inference/io.cc
0 → 100644
此差异已折叠。
paddle/fluid/inference/io.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/CMakeLists.txt
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/api/cxx_api.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/api/cxx_api.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/api/light_api.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/context.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/context.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/cpu_info.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/kernel.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/kernel.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/memory.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/memory.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/mir/node.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/mir/pass.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/op_lite.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/op_lite.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/program.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/program.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/scope.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/scope.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/tensor.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/types.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/core/types.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/core/variable.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/fluid/lite/cuda/blas.cc
0 → 100644
此差异已折叠。
paddle/fluid/lite/cuda/blas.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。