Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into feature/add_pinned_memory
Showing
cmake/hip.cmake
0 → 100644
doc/fluid/CMakeLists.txt
0 → 100644
{kind=link}
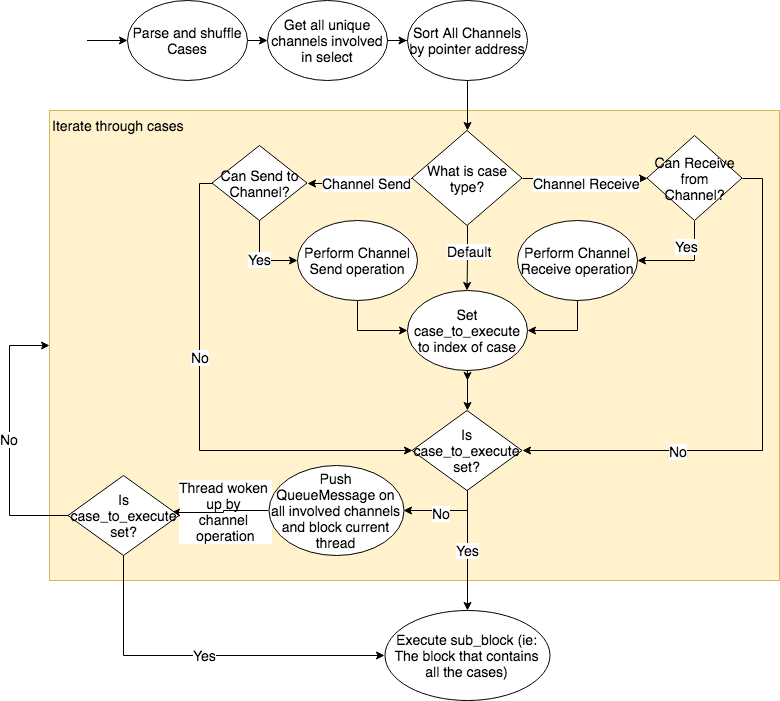
99.1 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
doc/fluid/design/index_cn.rst
0 → 100644
doc/fluid/design/index_en.rst
0 → 100644
doc/fluid/dev/index_cn.rst
0 → 100644
doc/fluid/dev/index_en.rst
0 → 100644
doc/fluid/faq/index_cn.rst
0 → 100644
doc/fluid/faq/index_en.rst
0 → 100644
doc/fluid/getstarted/index_cn.rst
0 → 100644
doc/fluid/getstarted/index_en.rst
0 → 100644
doc/fluid/howto/index_cn.rst
0 → 100644
doc/fluid/howto/index_en.rst
0 → 100644
doc/fluid/index_cn.rst
0 → 100644
doc/fluid/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/build.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。